CrowdAILab/scicap
收藏Hugging Face2024-04-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/CrowdAILab/scicap
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
---
# The 1st Scientific Figure Captioning (SciCap) Challenge 📖📊
Welcome to the 1st Scientific Figure Captioning (SciCap) Challenge! 🎉 This dataset contains approximately 400,000 scientific figure images sourced from various arXiv papers, along with their captions and relevant paragraphs. The challenge is open to researchers, AI/NLP/CV practitioners, and anyone interested in developing computational models for generating textual descriptions for visuals. 💻
*Challenge [homepage](http://SciCap.AI) 🏠*
## Challenge Overview 🌟
The SciCap Challenge will be hosted at ICCV 2023 in the 5th Workshop on Closing the Loop Between Vision and Language (October 2-3, Paris, France) 🇫🇷. Participants are required to submit the generated captions for a hidden test set for evaluation.
The challenge is divided into two phases:
- **Test Phase (2.5 months):** Use the provided training set, validation set, and public test set to build and test the models.
- **Challenge Phase (2 weeks):** Submit results for a hidden test set that will be released before the submission deadline.
Winning teams will be determined based on their results for the hidden test set 🏆. Details of the event's important dates, prizes, and judging criteria are listed on the challenge homepage.
## Dataset Overview and Download 📚
The SciCap dataset contains an expanded version of the [original SciCap](https://aclanthology.org/2021.findings-emnlp.277.pdf) dataset, and includes figures and captions from arXiv papers in eight categories: Computer Science, Economics, Electrical Engineering and Systems Science, Mathematics, Physics, Quantitative Biology, Quantitative Finance, and Statistics 📊. Additionally, it covers data from ACL Anthology papers [ACL-Fig](https://arxiv.org/pdf/2301.12293.pdf).
You can download the dataset using the following command:
```python
from huggingface_hub import snapshot_download
snapshot_download(repo_id="CrowdAILab/scicap", repo_type='dataset')
```
_Merge all image split files into one_ 🧩
```
zip -F img-split.zip --out img.zip
```
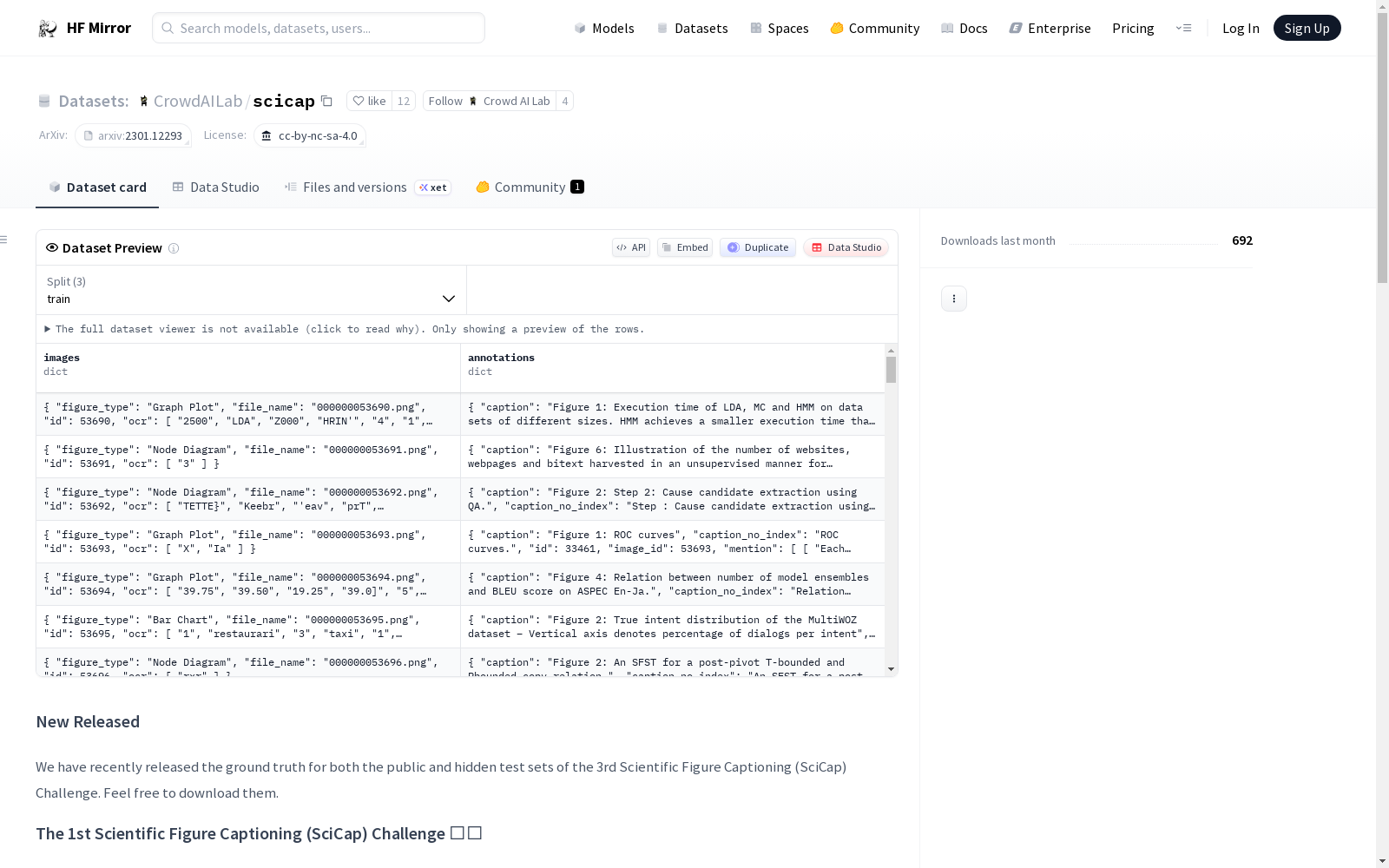
The dataset schema is similar to the `mscoco` dataset:
- **images:** two separated folders - arXiv and acl figures 📁
- **annotations:** JSON files containing text information (filename, image id, figure type, OCR, and mapped image id, captions, normalized captions, paragraphs, and mentions) 📝
## Evaluation and Submission 📩
You have to submit your generated captions in JSON format as shown below:
```json
[
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
},
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
}
...
]
```
Submit your results using this [challenge link](https://eval.ai/web/challenges/challenge-page/2012/overview) 🔗. Participants must register on [Eval.AI](http://Eval.AI) to access the leaderboard and submit results.
**Please note:** Participants should not use the original captions from the arXiv papers (termed "gold data") as input for their systems ⚠️.
## Technical Report Submission 🗒️
All participating teams must submit a 2-4 page technical report detailing their system, adhering to the ICCV 2023 paper template 📄. Teams have the option to submit their reports to either the archival or non-archival tracks of the 5th Workshop on Closing the Loop Between Vision and Language.
Good luck with your participation in the 1st SciCap Challenge! 🍀🎊
授权协议:知识共享署名-非商业性使用-相同方式共享 4.0 (CC BY-NC-SA 4.0)
# 第一届科学图表图像描述 (Scientific Figure Captioning, SciCap) 挑战赛 📖📊
欢迎参与第一届科学图表图像描述 (Scientific Figure Captioning, SciCap) 挑战赛!🎉 本数据集包含约40万张源自各类arXiv预印本论文的科学图表图像,以及其配套的图表说明文字与相关段落。本次挑战赛面向研究人员、人工智能/自然语言处理/计算机视觉从业者,以及所有致力于开发面向视觉内容生成文本描述的计算模型的爱好者开放。💻
*挑战赛[主页](http://SciCap.AI) 🏠*
## 挑战赛概览 🌟
本次SciCap挑战赛将在2023年国际计算机视觉大会(ICCV 2023)第五届“视觉与语言闭环”工作坊期间举办(10月2-3日,法国巴黎 🇫🇷)。参赛者需为隐藏测试集生成图像描述并提交以供评估。
本次挑战赛分为两个阶段:
- **测试阶段(2.5个月):** 利用提供的训练集、验证集与公开测试集构建并调试模型。
- **挑战赛阶段(2周):** 提交在隐藏测试集上的生成结果,该测试集将在提交截止日前开放获取。
获胜团队将根据隐藏测试集的评估结果决出 🏆。本次活动的重要日程、奖项设置与评审标准详见挑战赛主页。
## 数据集概览与下载 📚
SciCap数据集是[原始SciCap数据集](https://aclanthology.org/2021.findings-emnlp.277.pdf)的扩展版本,涵盖了arXiv预印本论文中8个类别的图表与说明文字:计算机科学、经济学、电气工程与系统科学、数学、物理学、定量生物学、定量金融学与统计学 📊。此外,数据集还包含ACL文集(ACL Anthology)论文中的图表数据[ACL-Fig](https://arxiv.org/pdf/2301.12293.pdf)。
你可以通过以下命令下载数据集:
python
from huggingface_hub import snapshot_download
snapshot_download(repo_id="CrowdAILab/scicap", repo_type='dataset')
**合并所有图像拆分文件 🧩**
zip -F img-split.zip --out img.zip
数据集的结构与`mscoco`数据集类似:
- **图像文件:** 分为两个独立文件夹——arXiv预印本论文图表与ACL论文图表 📁
- **标注文件:** 包含文本信息的JSON文件,涵盖文件名、图像ID、图表类型、光学字符识别 (Optical Character Recognition) 结果、映射图像ID、说明文字、标准化说明文字、相关段落与提及内容 📝
## 评估与提交 📩
你需要按照以下格式提交生成的图像描述结果(JSON格式):
json
[
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
},
{
"image_id": int,
"caption": "PREDICTED CAPTION STRING"
}
...
]
请通过此[挑战赛链接](https://eval.ai/web/challenges/challenge-page/2012/overview) 🔗提交结果。参赛者需在[Eval.AI](http://Eval.AI)平台注册,方可查看排行榜并提交结果。
**请注意:** 参赛者不得将arXiv预印本论文中的原始说明文字(即“金标准数据”)作为模型输入使用 ⚠️。
## 技术报告提交 🗒️
所有参赛团队需提交2至4页的技术报告,详细阐述所用系统,需符合ICCV 2023论文模板 📄。团队可选择将报告提交至第五届“视觉与语言闭环”工作坊的存档或非存档赛道。
预祝各位在第一届SciCap挑战赛中取得佳绩!🍀🎊
提供机构:
CrowdAILab
原始信息汇总
数据集概述
数据集名称
The 1st Scientific Figure Captioning (SciCap) Challenge
数据集内容
- 数据量:约400,000张科学图表图像
- 来源:来自arXiv论文的图表及其标题和相关段落
- 分类:包含八个类别,包括计算机科学、经济学、电气工程与系统科学、数学、物理学、定量生物学、定量金融和统计学
数据集结构
- 图像:分为两个文件夹 - arXiv和acl图表
- 注释:JSON文件,包含文件名、图像ID、图表类型、OCR、映射的图像ID、标题、规范化标题、段落和提及
数据集下载
python from huggingface_hub import snapshot_download snapshot_download(repo_id="CrowdAILab/scicap", repo_type=dataset)
挑战概述
挑战时间与地点
- 时间:2023年10月2-3日
- 地点:巴黎,法国,ICCV 2023的第5届视觉与语言闭环工作坊
挑战阶段
- 测试阶段:2.5个月,使用提供的训练集、验证集和公开测试集构建和测试模型
- 挑战阶段:2周,提交对隐藏测试集的生成标题
提交格式
json [ { "image_id": int, "caption": "PREDICTED CAPTION STRING" }, { "image_id": int, "caption": "PREDICTED CAPTION STRING" } ... ]
技术报告提交
- 要求:2-4页技术报告,遵循ICCV 2023论文模板
- 选项:可选择存档或非存档轨道提交
注意事项
- 参与者不应使用arXiv论文中的原始标题(称为“黄金数据”)作为系统输入
搜集汇总
数据集介绍
构建方式
在科学文献可视化分析领域,SciCap数据集通过系统化采集与标注流程构建而成。该数据集从arXiv预印本平台的八个学科类别及ACL Anthology论文中,精选约40万幅科学图表,每幅图像均关联原始论文中的描述性段落与标注信息。构建过程中采用自动化提取与人工校验相结合的方式,确保图像与文本对应关系的准确性,并遵循类似MS-COCO的数据架构,形成包含图像文件与结构化标注JSON文件的完整资源体系。
特点
SciCap数据集的核心特点体现在其跨学科覆盖与多层次标注结构上。数据集涵盖计算机科学、物理学、经济学等多个学科的科学图表,每幅图像不仅提供原始标题,还包含标准化标题、相关段落及文本提及信息,形成丰富的上下文关联。图像类型多样,涵盖流程图、统计图等多种形式,并附带光学字符识别结果,为多模态学习提供细粒度文本视觉对齐基础。数据集的规模与标注深度为科学图表理解任务设立了新的基准。
使用方法
该数据集适用于科学图表自动描述生成任务的研究与评估。使用者可通过HuggingFace Hub直接下载完整数据集,按照挑战设定的训练集、验证集及公开测试集划分进行模型开发。评估阶段需针对隐藏测试集生成描述文本,并以特定JSON格式提交结果,系统将自动计算标准自然语言生成指标。研究人员可利用图像文件夹与标注文件的对应关系,构建端到端的视觉语言模型,但需注意不得直接使用原始论文中的黄金描述作为模型输入,以确保评估的公正性。
背景与挑战
背景概述
科学图表自动标注作为跨模态信息处理的前沿领域,旨在通过计算模型为学术文献中的图表生成精准的文本描述。SciCap数据集由CrowdAILab团队于2023年构建,依托ICCV 2023的'Closing the Loop Between Vision and Language'研讨会正式发布。该数据集汇集了约40万幅来自arXiv及ACL Anthology论文的科学图表,涵盖计算机科学、物理学、经济学等八个学科类别,其核心研究问题聚焦于提升模型对复杂科学视觉内容的语义理解与生成能力。SciCap的推出显著推动了学术图表理解领域的发展,为多模态人工智能在科研文档处理中的应用奠定了数据基础。
当前挑战
SciCap数据集致力于解决科学图表自动标注这一跨模态任务的挑战,其核心难点在于图表通常包含密集的专业符号、多模态数据呈现以及高度学科特定的语义逻辑,要求模型不仅识别视觉元素,还需融合上下文学术文本进行推理。在构建过程中,团队面临数据采集与标注的复杂性:科学图表来源分散,需从海量论文中提取并统一处理;标注工作需依赖领域知识以确保描述的专业性与准确性,同时需设计自动化流程以处理大规模图像与文本的对齐问题,并避免使用原始论文中的'黄金数据'作为输入,以保障评估的公正性。
常用场景
经典使用场景
在跨模态人工智能研究领域,科学文献中的图表与文本描述之间的语义关联一直是核心挑战之一。SciCap数据集通过整合约40万幅来自arXiv和ACL Anthology的学术图表及其对应标题与相关段落,为视觉语言生成任务提供了大规模、多学科的基准资源。该数据集最经典的应用场景在于训练和评估端到端的图像描述生成模型,特别是在科学图表自动标注方向,研究者可基于其丰富的图像-文本对,开发能够理解复杂学术视觉内容并生成精准、连贯自然语言描述的算法。
解决学术问题
SciCap数据集主要致力于解决科学图表自动理解与描述生成中的若干关键学术问题。其一,它针对学术图表多样性高、结构复杂的特点,提供了覆盖计算机科学、物理学、经济学等八大学科领域的标注数据,有助于克服传统图像描述数据集中领域局限性强的瓶颈。其二,通过提供图表对应的上下文段落及提及信息,该数据集支持对图表与正文语义关联的深入建模,推动了多模态语义融合研究的发展。这些贡献显著提升了模型在科学图表理解任务上的泛化能力与解释性。
衍生相关工作
围绕SciCap数据集,已衍生出一系列具有影响力的研究工作。例如,最初的SciCap论文(发表于EMNLP 2021 Findings)建立了数据集的基础版本并提出了早期基准模型。后续的ACL-Fig扩展工作进一步融入了计算语言学领域的图表数据。在ICCV 2023的‘Closing the Loop Between Vision and Language’研讨会上举办的首届SciCap挑战赛,吸引了众多团队参与,推动了基于Transformer的多模态架构、预训练视觉语言模型在科学图表描述任务上的创新应用。这些工作共同深化了对学术图表语义理解的技术前沿探索。
以上内容由遇见数据集搜集并总结生成


