有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
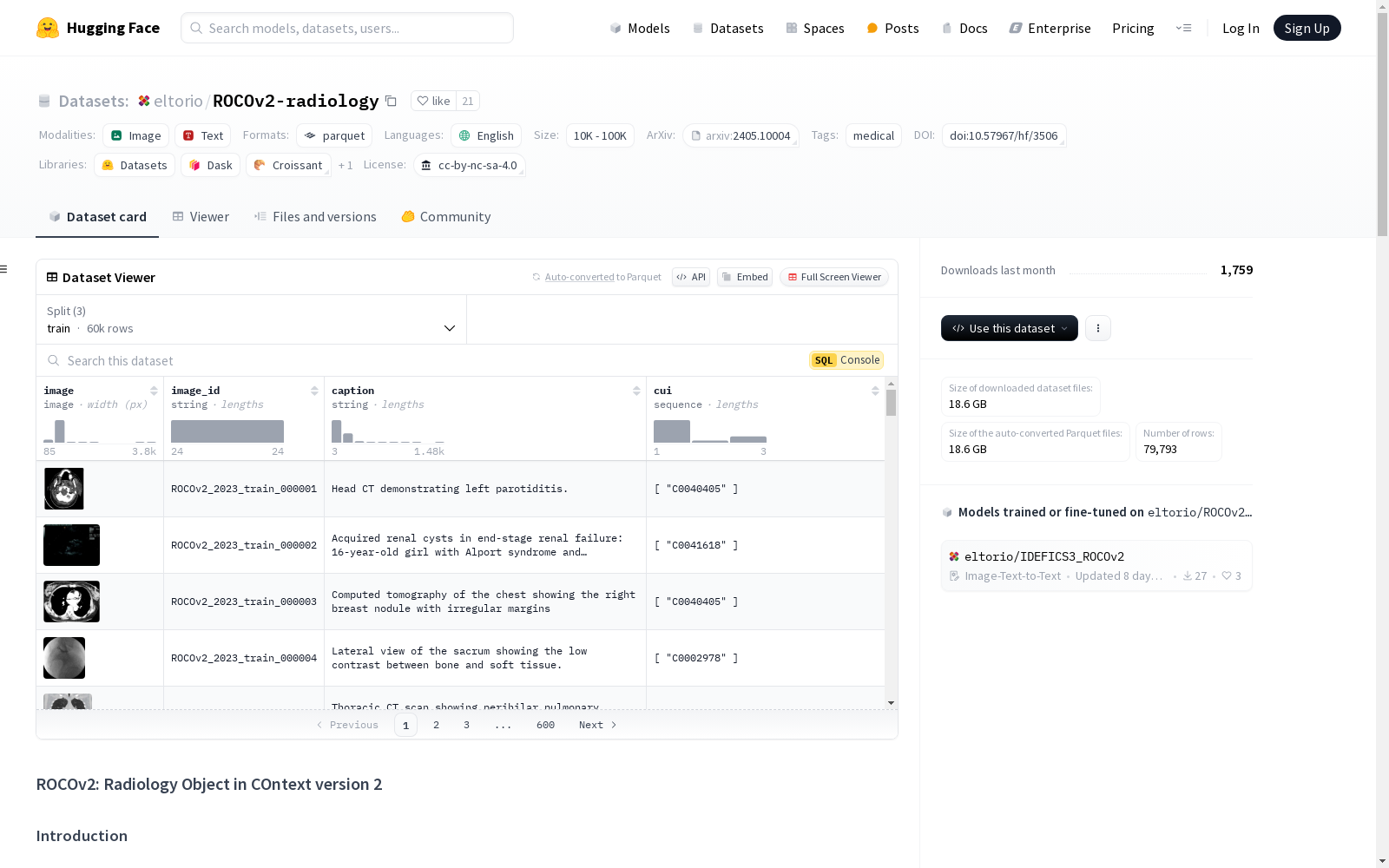
ROCOv2是一个多模态数据集,包含放射图像及其相关的医学概念和描述,这些数据是从PMC开放获取子集中提取的。它是ROCO数据集的更新版本,新增了35,705张图像,并改进了概念提取和过滤。
ROCOv2数据集包含79,789张放射图像,每张图像都有相应的描述和医学概念。这些图像来自PMC开放获取子集中的公开出版物,并根据CC BY或CC BY-NC许可发布。
数据集通过下载完整的PMC开放获取子集,提取图像和描述,并使用两个二分类模型进行过滤创建。这些模型分别达到了约90%和98.6%的准确率。
数据集标签和概念使用医学概念注释工具包v1.10.0(MedCAT)生成,并手动为模态(所有图像)、身体区域(仅X射线)和方向性(仅X射线)进行了概念的整理。
ROCOv2数据集可用于多种应用,包括:
如果使用ROCOv2数据集进行研究,请引用以下论文: Pelka, O., Menze, B. H., & Rexhausen, S. E. (2023). Radiology Objects in COntext version 2 (ROCOv2): A multimodal dataset for medical image analysis. arXiv preprint arXiv:2405.10004.
ROCOv2数据集根据CC BY-NC-SA 4.0许可证发布。
我们感谢美国国家医学图书馆(NLM)提供PMC开放获取子集的访问权限,并感谢医学概念注释工具包(MedCAT)的创建者提供了宝贵的概念提取和注释工具。
学生课堂行为数据集 (SCB-dataset3)
学生课堂行为数据集(SCB-dataset3)由成都东软学院创建,包含5686张图像和45578个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和趴桌。数据集覆盖从幼儿园到大学的不同场景,通过YOLOv5、YOLOv7和YOLOv8算法评估,平均精度达到80.3%。该数据集旨在为学生行为检测研究提供坚实基础,解决教育领域中学生行为数据集的缺乏问题。
arXiv 收录
MultiTalk
MultiTalk数据集是由韩国科学技术院创建,包含超过420小时的2D视频,涵盖20种不同语言,旨在解决多语言环境下3D说话头生成的问题。该数据集通过自动化管道从YouTube收集,每段视频都配有语言标签和伪转录,部分视频还包含伪3D网格顶点。数据集的创建过程包括视频收集、主动说话者验证和正面人脸验证,确保数据质量。MultiTalk数据集的应用领域主要集中在提升多语言3D说话头生成的准确性和表现力,通过引入语言特定风格嵌入,使模型能够捕捉每种语言独特的嘴部运动。
arXiv 收录
ChemBL
ChemBL是一个化学信息学数据库,包含大量生物活性数据,涵盖了药物发现和开发过程中的各种化学实体。数据集包括化合物的结构信息、生物活性数据、靶点信息等。
www.ebi.ac.uk 收录
猫狗图像数据集
该数据集包含猫和狗的图像,每类各12500张。训练集和测试集分别包含10000张和2500张图像,用于模型的训练和评估。
github 收录
LinkedIn Salary Insights Dataset
LinkedIn Salary Insights Dataset 提供了全球范围内的薪资数据,包括不同职位、行业、地理位置和经验水平的薪资信息。该数据集旨在帮助用户了解薪资趋势和市场行情,支持职业规划和薪资谈判。
www.linkedin.com 收录