Griffon-G-CCMD-8M
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/JefferyZhan/Griffon-G-CCMD-8M
下载链接
链接失效反馈官方服务:
资源简介:
Griffon G CCMD 8M数据集是一个用于视觉任务训练的数据集,包括对象检测和视觉问答两个任务类别。该数据集包含训练数据,分为三个阶段:范式预适应预训练和综合指令调整。第一阶段的数据需要遵循ShareGPT-4V的官方指南。第二阶段和第三阶段的数据分别存放在`pretrain`和`SFT`文件夹中。数据集的图像来源于多个开源数据集,包括Object365-2023、COCO、V3Det、Visual Genemo和Flickrs30K Entities等。此外,还提供了包含数百万图像的一般指令数据。数据集遵循知识共享署名-非商业4.0国际许可。
创建时间:
2025-08-11
原始信息汇总
Griffon-G-CCMD-8M 数据集概述
基本信息
- 许可证: Attribution-NonCommercial 4.0 International (cc-by-nc-4.0)
- 任务类别: 目标检测、视觉问答
- 语言: 英语 (en)
- 发布日期: 2025年8月12日
数据集详情
- 用途: 提供第二阶段(范式预适应预训练)和第三阶段(全面指令微调)的训练数据。
- 数据组织:
- 预训练数据 (
pretrain文件夹) - 指令微调数据 (
SFT文件夹)
- 预训练数据 (
预训练数据
- 图像来源: Object365-2023, COCO (train2017 & train2014), V3Det, Visual Genemo, Flickrs30K Entities。
- 注意事项: 需自行下载源图像。
指令微调数据
- 包含内容:
- 视觉分词器训练数据(含图像和标注)
- 处理后的标注(需自行下载源图像)
- 主要文件:
general_instructions.json: 包含多个数据源的标注。CT-datasetv2.tar.gz: 包含图像和标注。
- 图像来源: 与预训练数据相同。
许可证
- 遵循原始数据源的政策。
引用
bibtex @article{zhan2024griffon-G, title={Griffon-G: Bridging Vision-Language and Vision-Centric Tasks via Large Multimodal Models}, author={Zhan, Yufei and Zhao, Hongyin and Zhu, Yousong and Yang, Fan and Tang, Ming and Wang, Jinqiao}, journal={arXiv preprint arXiv:2410.16163}, year={2024} }
搜集汇总
数据集介绍
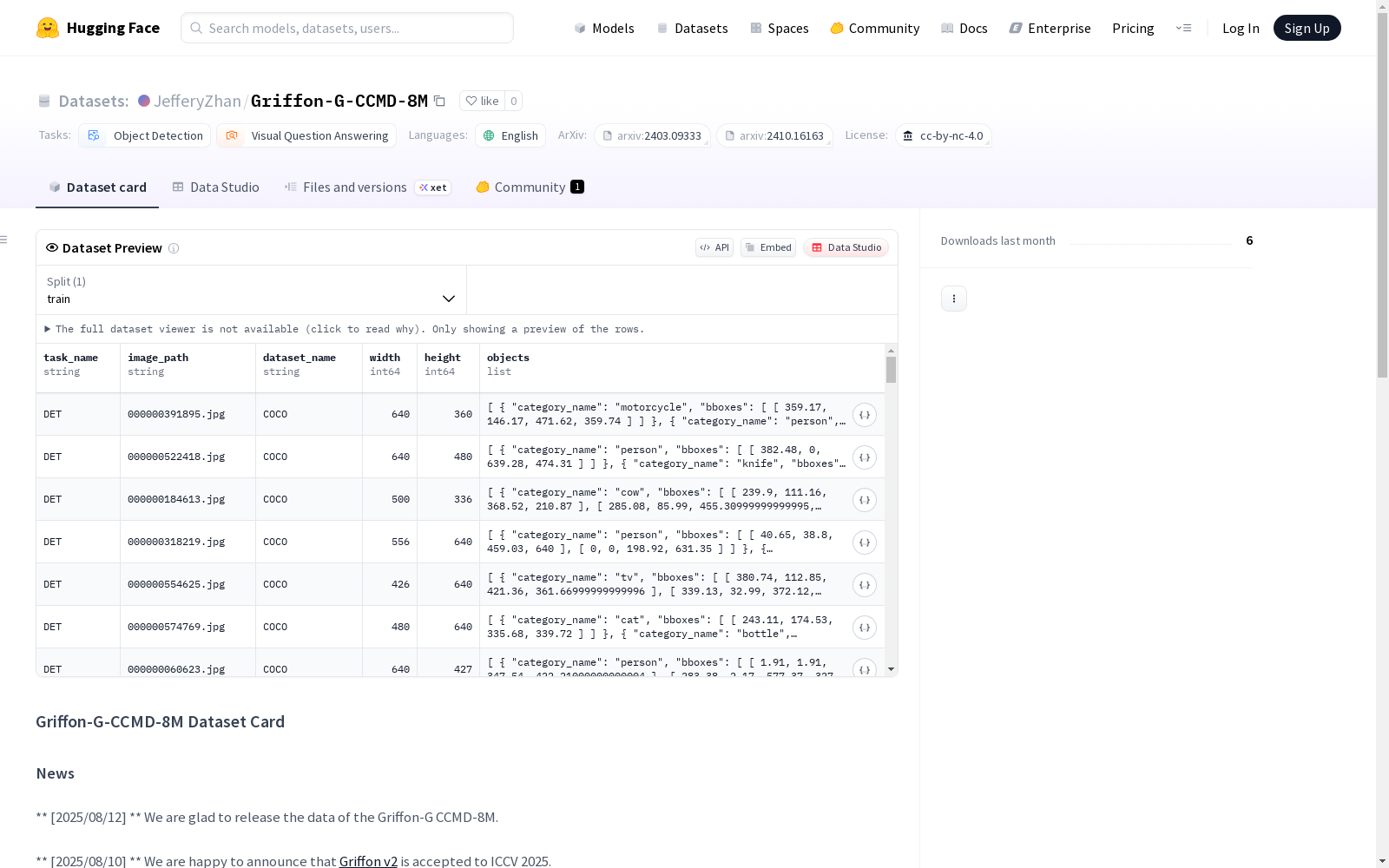
构建方式
Griffon-G-CCMD-8M数据集的构建过程体现了多模态学习领域的前沿探索。该数据集通过三阶段训练框架精心设计:第一阶段遵循ShareGPT-4V的官方指南进行对齐;第二阶段'范式预适应预训练'数据存放于pretrain文件夹,整合了Object365-2023、COCO等五大权威视觉数据源;第三阶段'综合指令微调'数据存储在SFT文件夹,囊括23个跨领域视觉问答数据集,并通过严格的图像-标注对齐流程确保数据质量。
特点
该数据集最显著的特点在于其前所未有的规模与多样性。作为包含800万样本的多模态资源,它创新性地融合了目标检测与视觉问答两大任务模态,覆盖通用物体识别、图表解析、文档理解等丰富场景。特别值得注意的是,数据集采用模块化设计,既包含可直接使用的CT-datasetv2完整数据包,也支持研究者根据需求灵活组合23个子集的标注文件,这种弹性架构极大提升了资源的可扩展性。
使用方法
使用该数据集需遵循严谨的多阶段流程。研究者首先需从原始数据源下载对应图像,通过官方提供的Python脚本实现图像与标注的精确匹配。对于指令微调阶段,general_instructions.json文件提供了跨数据集统一接口,而CT-datasetv2.tar.gz则提供开箱即用的训练资源。值得注意的是,所有使用需遵守CC-BY-NC-4.0许可协议,并严格遵循各原始数据源的使用规范,相关引用需包含作者提供的BibTeX条目以尊重知识产权。
背景与挑战
背景概述
Griffon-G-CCMD-8M数据集由Yufei Zhan等研究人员于2024年提出,旨在构建一个大规模多模态模型,以弥合视觉语言任务与视觉中心任务之间的鸿沟。该数据集作为Griffon v2模型的重要组成部分,被ICCV 2025接收,标志着其在计算机视觉与自然语言处理交叉领域的重要地位。数据集整合了Object365-2023、COCO、V3Det等多个权威视觉数据源,并通过范式预适应预训练和综合指令微调两个阶段,为多模态学习提供了丰富的训练资源。其非商业性的CC-BY-NC-4.0许可协议确保了数据使用的规范性与可持续性。
当前挑战
Griffon-G-CCMD-8M数据集面临的核心挑战体现在两个方面:在领域问题层面,如何有效统一视觉语言理解(如视觉问答)与目标检测等视觉中心任务的表征学习,需解决跨模态对齐与任务冲突的固有难题;在构建过程中,数据整合涉及20余个异构数据源,需协调不同标注规范与许可协议,且部分图像需依赖原始数据集配额,导致完整数据获取存在延迟。此外,百万级图像与文本对的精确匹配校验,对数据处理流程的鲁棒性提出了极高要求。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,Griffon-G-CCMD-8M数据集为多模态任务提供了丰富的训练资源。该数据集广泛应用于视觉问答和对象检测任务,通过整合来自Object365-2023、COCO、V3Det等多个权威数据源的图像和标注,为研究者提供了高质量的预训练和指令微调数据。其多阶段训练框架特别适合探索视觉-语言对齐和跨模态理解的前沿问题。
实际应用
在实际应用层面,该数据集支撑的模型可部署于智能客服、无障碍辅助系统等需要视觉理解的场景。其涵盖的图表解析(ChartQA)、文档理解(DocVQA)等专业子集,为金融、医疗领域的自动化文档处理提供了技术基础。通过整合网络名人(web-celebrity)和地标(web-landmark)数据,进一步增强了模型在社交媒体内容分析中的实用性。
衍生相关工作
基于该数据集衍生的Griffon v2模型在ICCV 2025展示了突破性性能,启发了多模态提示学习的新范式。其构建方法为后续工作如ShareGPT-4V的跨模态对齐提供了参考框架,相关技术已延伸至科学问答(ScienceQA)、视觉推理(VisualMRC)等细分领域,形成了一系列基于指令微调的视觉语言模型改进方案。
以上内容由遇见数据集搜集并总结生成


