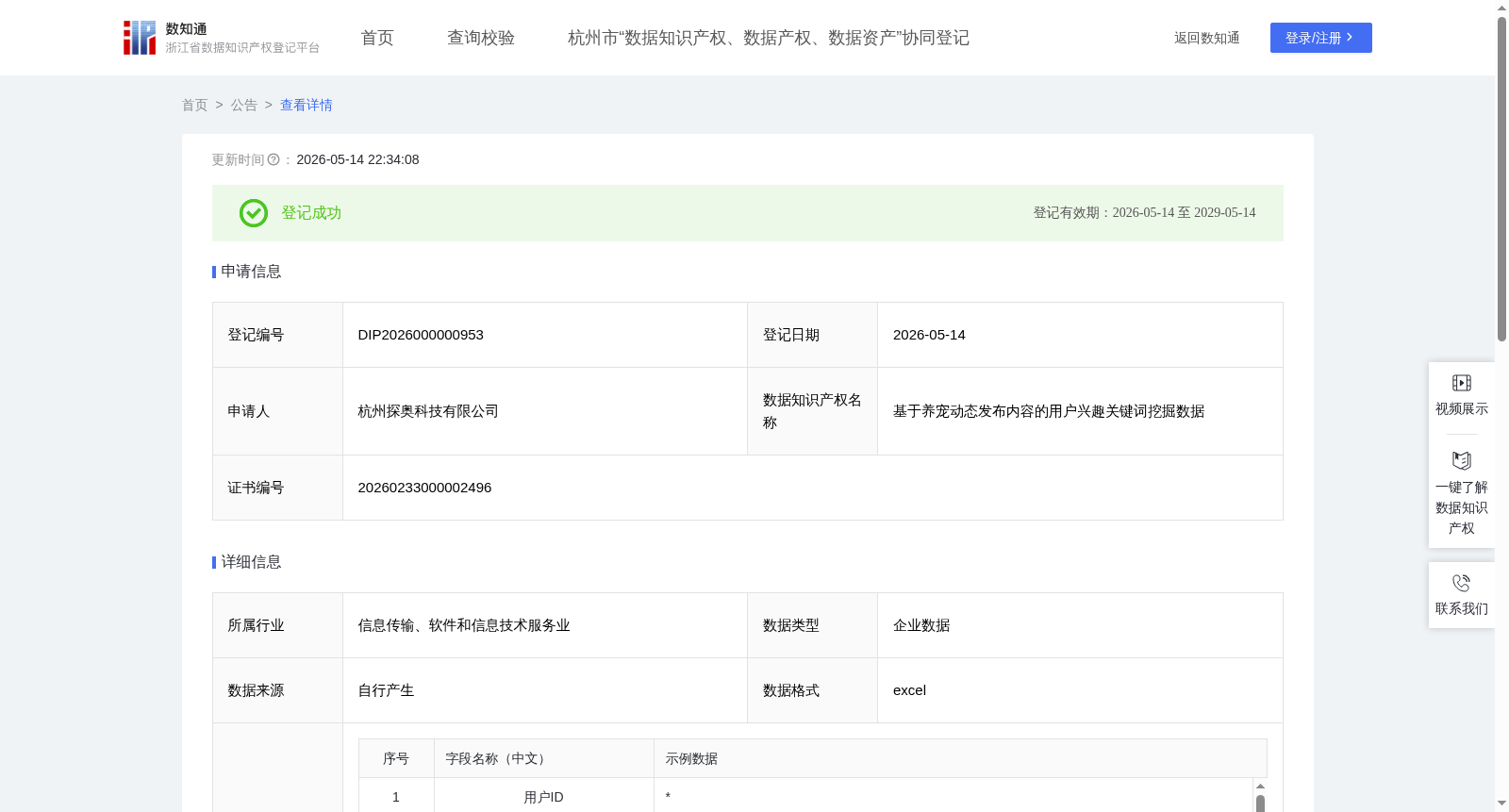
基于养宠动态发布内容的用户兴趣关键词挖掘数据
收藏浙江省数据知识产权登记平台2026-05-14 更新2026-05-15 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8444609
下载链接
链接失效反馈官方服务:
资源简介:
1.“宠one小程序”是公司自研的一款宠物社区平台,因此本数据对内有助于实现精细化用户运营。基于通过BERT模型微调生成的用户兴趣画像,运营团队能够精准把握养宠用户的需求动向,从而动态优化内容推荐与服务策略,有效提升用户活跃度与留存。
2.对外可为合作伙伴提供清晰的兴趣趋势洞察。经脱敏处理的用户主兴趣类别与关键词,能够帮助品牌及服务商把握市场需求的结构性变化,辅助其优化产品规划与营销资源分配,实现更精准的商业协同。
3.为算法模型提供持续迭代的高质量训练与验证样本。本数据产出过程本身即依赖于模型微调,其输出的带标注的兴趣画像数据,可直接作为推荐系统及预测模型的反馈信号,用于模型的再训练与优化,形成从数据到模型、再从业务反馈到数据的增强闭环。1.加工前的数据说明:(1)加工前的数据为公司基于“宠one小程序”日常记录功能而实时采集的养宠日常记录数据,并已经用户授权合法获得,采集字段包括:用户id、动态内容、类目id和创建时间;(2)数据预处理:过滤动态内容为空或少于5字符的记录,清洗特殊字符与广告内容,标准化时间格式,剔除数据异常记录。
2.处理规则: (1)兴趣分类模型构建:① 采用 RoBERTa-wwm-ext 预训练语言模型作为基础,在其输出层增加一个四分类 Softmax 层,对应四大养宠兴趣类别:饮食营养、健康医疗、行为训练与托管、居住与日常护理;② 将清洗后的动态内容文本直接输入该模型,结合动态所属的类目ID,共同用于模型训练与预测;(2)模型训练:将数据集按8:1:1比例划分为训练集、验证集与测试集,确保样本分布均衡。设置批次大小为32,学习率为5e-5,共训练8个轮次。训练过程同步优化模型全部参数,提升兴趣类别预测准确性。 (3)兴趣类别判定:将预处理后的数据输入微调完成的模型,由Softmax层输出四大兴趣类别的概率分布,取概率最高者作为该动态记录的主兴趣类别。 (4)核心关键词提取:利用微调后模型内部的注意力机制,分析模型在分类决策过程中对“动态内容”各词语的关注权重,直接提取权重最高的词语作为核心兴趣关键词。该过程复用分类模型,无需额外工具或后处理。 (5)最终输出:每条动态记录经处理后,输出其对应的主兴趣类别与核心兴趣关键词。 3.数据内容描述:加工前的数据经上述算法规则处理后,输出的数据内容为:每条养宠动态所对应的主兴趣类别与核心兴趣关键词。
提供机构:
杭州探奥科技有限公司
创建时间:
2026-02-06
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集基于养宠社区平台用户发布的动态内容,通过RoBERTa-wwm-ext模型进行微调,挖掘用户的兴趣类别(如行为训练与托管)及其核心关键词(如活泼好动)。数据包含1016条记录,实时更新,可用于精细化用户运营、商业趋势洞察及算法模型迭代优化。
以上内容由遇见数据集搜集并总结生成


