labofsahil/arXiv-metadata-Dataset
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/labofsahil/arXiv-metadata-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc0-1.0
pretty_name: arXiv metadata Dataset
---
提供机构:
labofsahil
搜集汇总
数据集介绍
构建方式
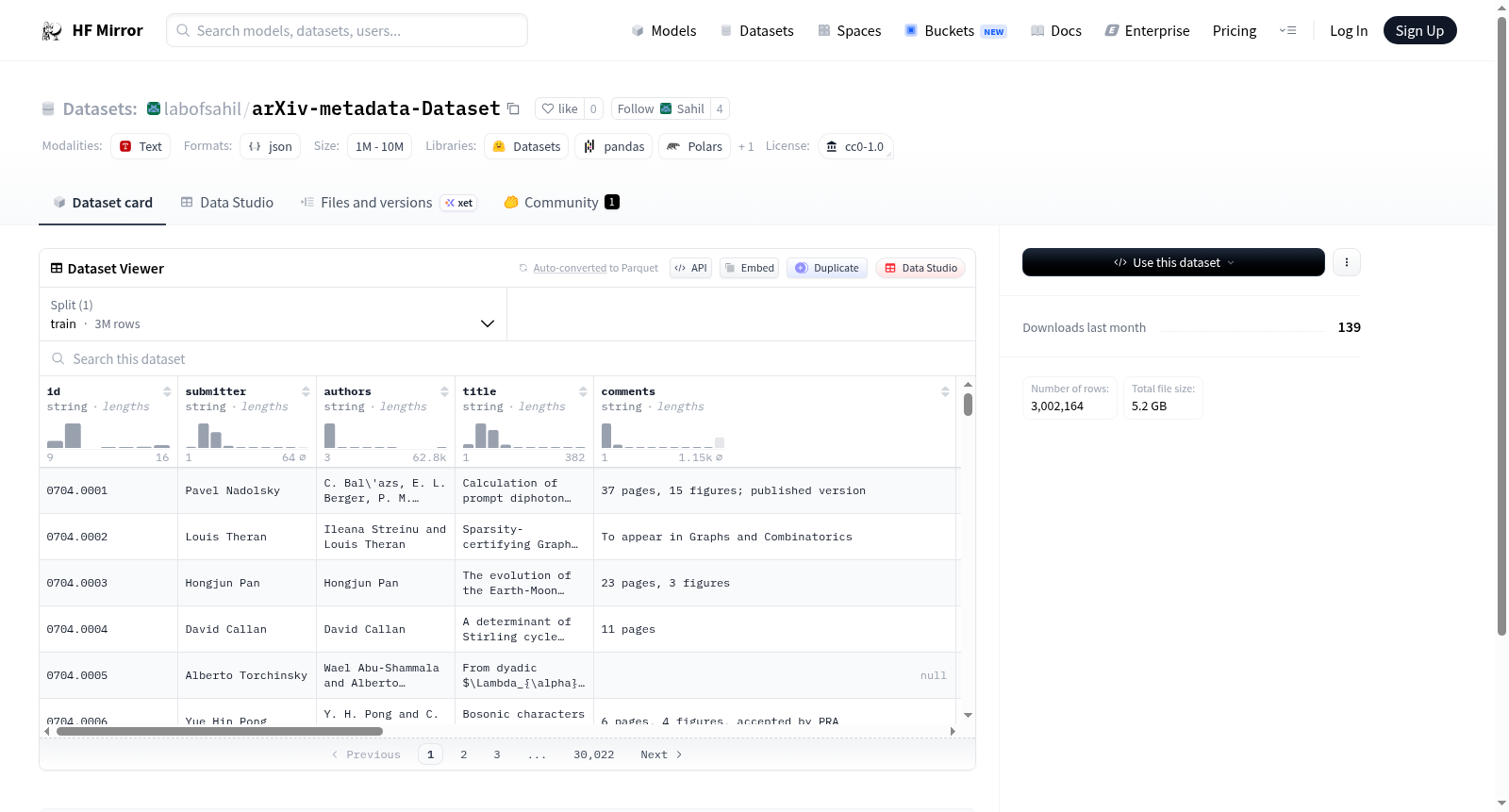
在学术信息数字化浪潮中,arXiv作为开放获取预印本服务器,积累了海量学术文献。arXiv-metadata-Dataset的构建正是基于这一庞大资源,通过系统性地收集与整理arXiv平台上的元数据信息而成。该数据集涵盖了每篇论文的标题、作者、摘要、提交日期、分类类别以及版本历史等结构化字段,其构建过程依赖于arXiv官方提供的定期数据导出与API接口,确保了数据的完整性与时效性。整个数据集经过清洗与标准化处理,形成了便于机器读取的统一格式,为大规模学术分析奠定了坚实基础。
使用方法
对于希望利用该数据集的研究者而言,其使用方法直接而高效。用户可以通过HuggingFace平台或相关数据仓库直接下载完整的数据集文件,通常以JSON或CSV等通用格式提供。在具体应用中,研究者可借助Python等编程语言进行数据加载与解析,进而开展诸如主题建模、作者协作网络分析、引用模式研究或趋势预测等任务。数据集的结构化设计使得集成到现有分析流程中变得简便,同时也支持与外部数据库进行关联,以拓展研究的深度与广度。
背景与挑战
背景概述
arXiv-metadata-Dataset作为学术文献数据的重要集合,其创建源于对大规模科学知识结构化管理的迫切需求。该数据集由arXiv平台及其合作研究机构共同构建,旨在系统收录物理学、数学、计算机科学等多领域的预印本论文元数据。自arXiv平台成立以来,随着开放科学运动的推进,该数据集逐步整合了论文标题、作者、摘要、分类代码及引用关系等关键信息,为核心研究问题——如学术趋势分析、学科交叉探测及知识图谱构建——提供了基础支撑。它不仅深化了文献计量学与科学学的研究范式,更推动了自然语言处理与信息检索技术在学术领域的创新应用,成为衡量学科发展动态的重要基准。
当前挑战
该数据集所针对的领域问题在于如何从海量学术文献中提取有效知识并支持复杂分析,其挑战体现在多维度异构数据的整合与标准化。具体而言,元数据字段的完整性与一致性常受作者提交规范差异的影响,导致信息缺失或格式混乱;同时,跨学科术语的语义消歧与分类体系演化增加了内容标注的难度。在构建过程中,技术挑战集中于大规模数据的高效抓取与实时更新,需平衡系统性能与数据新鲜度;此外,隐私保护与版权合规要求对作者信息及全文内容的处理施加了严格约束,使得数据清洗与开放共享面临伦理与法律的双重考量。
常用场景
经典使用场景
在学术信息检索与知识发现领域,arXiv-metadata-Dataset作为大规模预印本论文元数据集合,其经典使用场景聚焦于自然语言处理任务中的文本分类与主题建模。研究者常利用该数据集构建机器学习模型,自动识别论文所属学科类别或预测其关键词标签,从而高效组织海量学术文献,为知识图谱构建与智能检索系统提供结构化数据支持。
解决学术问题
该数据集有效解决了学术文献管理中的信息过载与知识结构化难题。通过提供标准化元数据,它支持跨学科趋势分析、新兴研究领域探测以及学术影响力评估等研究,显著提升了文献计量学与科学学研究的可扩展性。其开放共享特性更促进了透明可复现的学术实践,为开放科学运动奠定了数据基础。
实际应用
在实际应用中,arXiv-metadata-Dataset已成为学术搜索引擎优化与推荐系统的核心数据源。出版机构利用其构建个性化论文推送服务,科研管理平台借助其实现机构成果自动归类与可视化分析。此外,科技政策制定者可通过该数据集追踪全球研究热点演变,为科研资源配置提供数据驱动的决策依据。
数据集最近研究
最新研究方向
在学术知识图谱与开放科学领域,arXiv-metadata-Dataset作为涵盖海量预印本论文元数据的资源,正推动着前沿研究的深化。当前研究聚焦于利用该数据集构建动态学术网络,通过图神经网络分析论文间的引用关系与主题演化,以揭示新兴交叉学科的生长脉络。同时,结合自然语言处理技术,研究者致力于开发自动化摘要生成与趋势预测模型,助力科研人员快速把握领域热点。这些探索不仅促进了学术信息的智能检索与知识发现,也为开放科学基础设施的优化提供了数据支撑,彰显了大规模元数据在加速科研创新中的关键作用。
以上内容由遇见数据集搜集并总结生成


