KETI-AIR/kor_ai2_arc
收藏Hugging Face2023-12-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/KETI-AIR/kor_ai2_arc
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-sa-4.0
configs:
- config_name: ARC-Challenge
data_files:
- split: train
path: ARC-Challenge/train-*
- split: validation
path: ARC-Challenge/validation-*
- split: test
path: ARC-Challenge/test-*
- config_name: ARC-Easy
data_files:
- split: train
path: ARC-Easy/train-*
- split: validation
path: ARC-Easy/validation-*
- split: test
path: ARC-Easy/test-*
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
- config_name: ARC-Challenge
features:
- name: data_index_by_user
dtype: int32
- name: id
dtype: string
- name: question
dtype: string
- name: choices
struct:
- name: text
sequence: string
- name: label
sequence: string
- name: answerKey
dtype: string
splits:
- name: train
num_bytes: 396164
num_examples: 1119
- name: validation
num_bytes: 108314
num_examples: 299
- name: test
num_bytes: 425252
num_examples: 1172
download_size: 516331
dataset_size: 929730
- config_name: ARC-Easy
features:
- name: data_index_by_user
dtype: int32
- name: id
dtype: string
- name: question
dtype: string
- name: choices
struct:
- name: text
sequence: string
- name: label
sequence: string
- name: answerKey
dtype: string
splits:
- name: train
num_bytes: 694289
num_examples: 2251
- name: validation
num_bytes: 175983
num_examples: 570
- name: test
num_bytes: 735067
num_examples: 2376
download_size: 861121
dataset_size: 1605339
- config_name: default
features:
- name: data_index_by_user
dtype: int32
- name: id
dtype: string
- name: question
dtype: string
- name: choices
struct:
- name: text
sequence: string
- name: label
sequence: string
- name: answerKey
dtype: string
splits:
- name: train
num_bytes: 694289
num_examples: 2251
- name: validation
num_bytes: 175983
num_examples: 570
- name: test
num_bytes: 735067
num_examples: 2376
download_size: 861121
dataset_size: 1605339
---
# Dataset Card for "kor_ai2_arc"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
# Source Data Citation Information
```
@article{allenai:arc,
author = {Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and
Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord},
title = {Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge},
journal = {arXiv:1803.05457v1},
year = {2018},
}
```
许可协议:CC BY-SA 4.0(知识共享署名-相同方式共享4.0协议)
配置项:
- 配置名称:ARC-Challenge
数据文件:
- 数据拆分:train(训练集),路径:ARC-Challenge/train-*
- 数据拆分:validation(验证集),路径:ARC-Challenge/validation-*
- 数据拆分:test(测试集),路径:ARC-Challenge/test-*
- 配置名称:ARC-Easy
数据文件:
- 数据拆分:train(训练集),路径:ARC-Easy/train-*
- 数据拆分:validation(验证集),路径:ARC-Easy/validation-*
- 数据拆分:test(测试集),路径:ARC-Easy/test-*
- 配置名称:default(默认配置)
数据文件:
- 数据拆分:train(训练集),路径:data/train-*
- 数据拆分:validation(验证集),路径:data/validation-*
- 数据拆分:test(测试集),路径:data/test-*
数据集信息:
- 配置名称:ARC-Challenge
特征字段:
- 字段名:data_index_by_user,数据类型:int32(32位整数)
- 字段名:id,数据类型:string(字符串)
- 字段名:question,数据类型:string(字符串)
- 字段名:choices,结构体类型,包含子字段:
- 子字段名:text,数据类型:字符串序列
- 子字段名:label,数据类型:字符串序列
- 字段名:answerKey,数据类型:string(字符串)
数据拆分详情:
- 拆分名称:train(训练集),字节数:396164,样本数:1119
- 拆分名称:validation(验证集),字节数:108314,样本数:299
- 拆分名称:test(测试集),字节数:425252,样本数:1172
下载大小:516331
数据集总大小:929730
- 配置名称:ARC-Easy
特征字段:
- 字段名:data_index_by_user,数据类型:int32(32位整数)
- 字段名:id,数据类型:string(字符串)
- 字段名:question,数据类型:string(字符串)
- 字段名:choices,结构体类型,包含子字段:
- 子字段名:text,数据类型:字符串序列
- 子字段名:label,数据类型:字符串序列
- 字段名:answerKey,数据类型:string(字符串)
数据拆分详情:
- 拆分名称:train(训练集),字节数:694289,样本数:2251
- 拆分名称:validation(验证集),字节数:175983,样本数:570
- 拆分名称:test(测试集),字节数:735067,样本数:2376
下载大小:861121
数据集总大小:1605339
- 配置名称:default(默认配置)
特征字段:
- 字段名:data_index_by_user,数据类型:int32(32位整数)
- 字段名:id,数据类型:string(字符串)
- 字段名:question,数据类型:string(字符串)
- 字段名:choices,结构体类型,包含子字段:
- 子字段名:text,数据类型:字符串序列
- 子字段名:label,数据类型:字符串序列
- 字段名:answerKey,数据类型:string(字符串)
数据拆分详情:
- 拆分名称:train(训练集),字节数:694289,样本数:2251
- 拆分名称:validation(验证集),字节数:175983,样本数:570
- 拆分名称:test(测试集),字节数:735067,样本数:2376
下载大小:861121
数据集总大小:1605339
---
# 「kor_ai2_arc」数据集卡片
[需补充更多信息](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
# 源数据引用信息
@article{allenai:arc,
author = {Peter Clark、 Isaac Cowhey、 Oren Etzioni、 Tushar Khot、 Ashish Sabharwal、 Carissa Schoenick、 Oyvind Tafjord},
title = {你认为自己攻克了问答任务?不妨试试AI2推理挑战数据集ARC},
journal = {arXiv:1803.05457v1},
year = {2018},
}
提供机构:
KETI-AIR
原始信息汇总
数据集概述
许可证
- 该数据集遵循 CC BY-SA 4.0 许可证。
配置
- ARC-Challenge
- 数据文件路径:
- 训练集:
ARC-Challenge/train-* - 验证集:
ARC-Challenge/validation-* - 测试集:
ARC-Challenge/test-*
- 训练集:
- 数据文件路径:
- ARC-Easy
- 数据文件路径:
- 训练集:
ARC-Easy/train-* - 验证集:
ARC-Easy/validation-* - 测试集:
ARC-Easy/test-*
- 训练集:
- 数据文件路径:
- default
- 数据文件路径:
- 训练集:
data/train-* - 验证集:
data/validation-* - 测试集:
data/test-*
- 训练集:
- 数据文件路径:
数据集信息
-
ARC-Challenge
- 特征:
data_index_by_user:int32id:stringquestion:stringchoices:text:sequenceofstringlabel:sequenceofstring
answerKey:string
- 分割:
- 训练集:396164 字节,1119 个样本
- 验证集:108314 字节,299 个样本
- 测试集:425252 字节,1172 个样本
- 下载大小:516331 字节
- 数据集大小:929730 字节
- 特征:
-
ARC-Easy
- 特征:
data_index_by_user:int32id:stringquestion:stringchoices:text:sequenceofstringlabel:sequenceofstring
answerKey:string
- 分割:
- 训练集:694289 字节,2251 个样本
- 验证集:175983 字节,570 个样本
- 测试集:735067 字节,2376 个样本
- 下载大小:861121 字节
- 数据集大小:1605339 字节
- 特征:
-
default
- 特征:
data_index_by_user:int32id:stringquestion:stringchoices:text:sequenceofstringlabel:sequenceofstring
answerKey:string
- 分割:
- 训练集:694289 字节,2251 个样本
- 验证集:175983 字节,570 个样本
- 测试集:735067 字节,2376 个样本
- 下载大小:861121 字节
- 数据集大小:1605339 字节
- 特征:
搜集汇总
数据集介绍
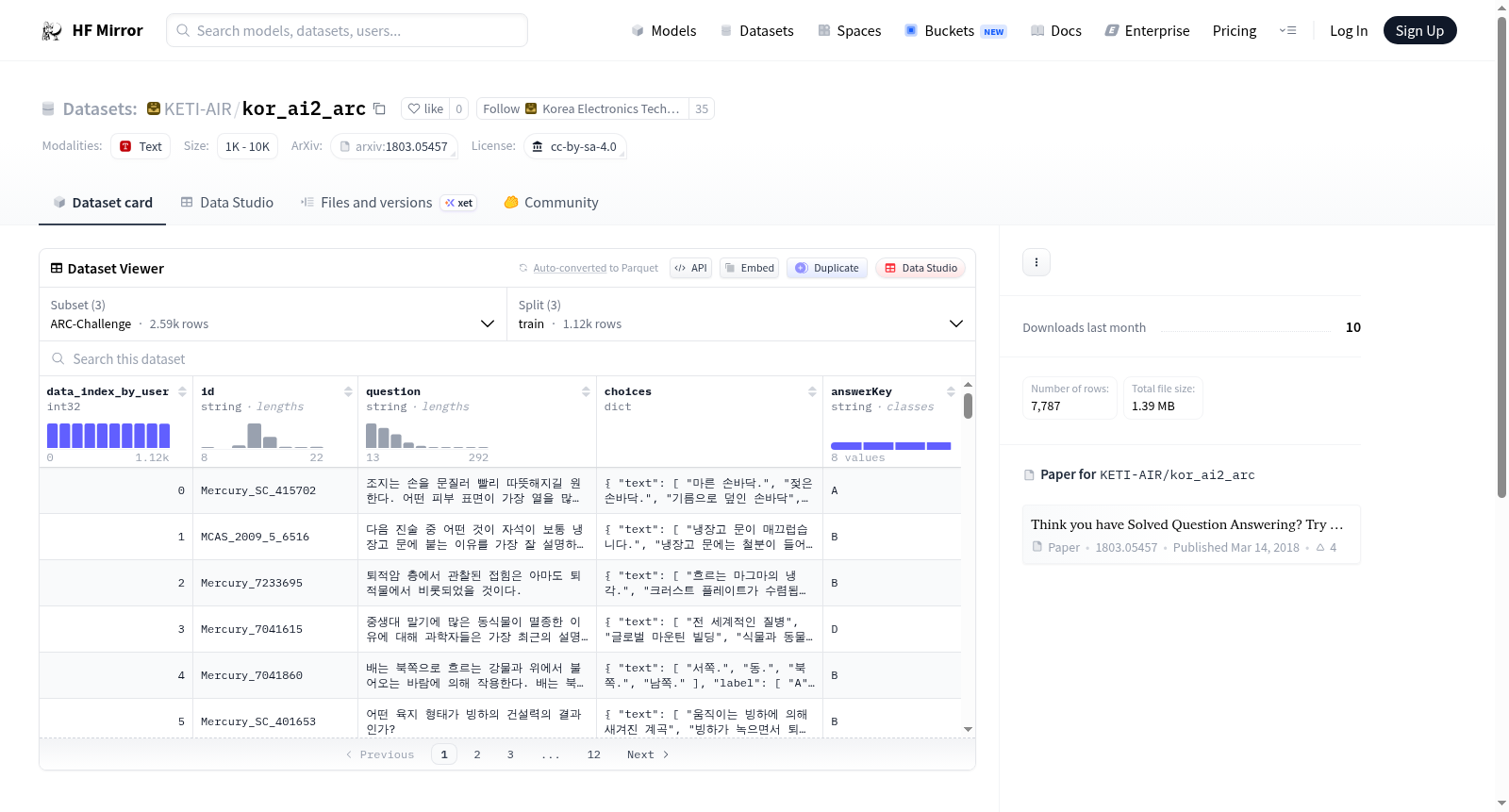
构建方式
在人工智能推理领域,KETI-AIR/kor_ai2_arc数据集源自AI2 Reasoning Challenge(ARC)的韩语版本,其构建过程遵循严谨的科学方法。该数据集通过精心筛选来自科学考试的真实题目,涵盖物理、化学、生物等学科,确保问题具有挑战性和多样性。构建时采用标准化流程,将原始英语题目翻译并适配为韩语,同时保留多选项结构,每个问题附带唯一标识符和答案键,以支持机器推理研究。数据集划分为训练、验证和测试三个子集,便于模型评估与迭代,整体设计旨在促进跨语言推理能力的发展。
特点
该数据集的特点体现在其多层次结构和学科覆盖的广度上。它包含两个主要配置:ARC-Challenge和ARC-Easy,分别针对不同难度级别,前者侧重复杂推理,后者则更注重基础理解。每个配置均提供结构化特征,如问题文本、选项标签和答案键,确保数据的一致性和可访问性。数据规模适中,训练集与测试集分布均衡,有助于避免过拟合问题。此外,数据集以CC-BY-SA-4.0许可证发布,支持开放学术使用,其多语言特性为韩语自然语言处理研究提供了宝贵资源。
使用方法
使用该数据集时,研究者可首先通过HuggingFace平台加载指定配置,例如ARC-Challenge或ARC-Easy,以获取相应难度的数据。数据以标准分割形式提供,包括训练、验证和测试集,便于直接应用于模型训练与评估流程。在具体应用中,用户可基于问题文本和选项构建多选问答任务,利用答案键进行监督学习或性能测试。数据集的结构化格式支持快速集成到深度学习框架中,如PyTorch或TensorFlow,同时其开放许可证鼓励在学术和工业场景中广泛使用,以推动人工智能推理技术的进步。
背景与挑战
背景概述
在人工智能推理能力评估领域,艾伦人工智能研究所于2018年推出的AI2推理挑战数据集,标志着对机器深度理解与逻辑推理能力的前沿探索。该数据集由Peter Clark等学者主导构建,其核心研究问题聚焦于考察模型在科学知识基础上的复杂推理能力,旨在超越传统的浅层模式匹配。通过精心设计的多项选择题形式,该数据集不仅推动了自然语言处理领域向认知智能的深化,也为评估模型的常识推理与科学知识应用设立了重要基准,对后续的机器推理研究产生了深远影响。
当前挑战
该数据集致力于解决科学问题回答中的复杂推理挑战,其问题设计需要模型整合多步骤逻辑与跨领域知识,而非依赖简单的文本匹配。在构建过程中,挑战主要源于如何确保问题的科学严谨性与多样性,同时避免数据泄露或偏见;此外,从原始英文数据到韩语版本的转换,还需克服语言与文化差异带来的语义保真度问题,这对保持推理难度与数据质量构成了显著考验。
常用场景
经典使用场景
在自然语言处理领域,知识推理是衡量模型智能水平的关键维度。KETI-AIR/kor_ai2_arc数据集作为AI2 Reasoning Challenge的韩语版本,其经典使用场景聚焦于评估和提升模型在复杂科学问题上的多选问答能力。该数据集通过涵盖物理、化学、生物等学科的真实考试题目,要求模型不仅理解表层语言,还需进行深层次的逻辑推理与知识关联,从而为研究者提供了一个严谨的基准测试平台。
解决学术问题
该数据集有效应对了当前人工智能研究中模型缺乏深度推理能力的核心挑战。它通过精心设计的科学问题,迫使模型超越简单的模式匹配,转向需要外部知识整合与因果推断的复杂认知过程。这一设定直接推动了可解释推理、知识图谱增强学习以及跨领域迁移学习等前沿方向的发展,为构建更接近人类思维方式的机器智能奠定了实证基础。
衍生相关工作
围绕该数据集,学术界已衍生出一系列具有影响力的经典研究工作。例如,诸多研究探索了如何将大型语言模型与结构化知识库相结合,以提升在ARC挑战上的表现。同时,针对其韩语特性,研究工作也集中在改进跨语言迁移学习与少样本学习策略上。这些工作不仅刷新了数据集的性能榜单,更普遍推动了知识驱动型自然语言处理模型架构与训练范式的创新。
以上内容由遇见数据集搜集并总结生成


