big_bench_audio
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/ArtificialAnalysis/big_bench_audio
下载链接
链接失效反馈官方服务:
资源简介:
Big Bench Audio 数据集是 Big Bench Hard 问题的一个音频版本子集,旨在评估支持音频输入的模型的推理能力。该数据集包含四个类别(形式谬误、导航、物体计数和谎言网络)的1000个音频录音。音频是使用23个顶级供应商的声音合成生成的,全部为英语。数据集的结构包括类别、官方答案、文件名和ID字段。它被精心策划,以在推理任务上对原生音频模型进行基准测试,避免可能对音频模型不公平惩罚的类别。该数据集还继承了原始 Big Bench Hard 数据集中的偏见,特别是集中在美式和英式口音上。
创建时间:
2024-12-13
原始信息汇总
Artificial Analysis Big Bench Audio
数据集描述
数据集概述
Big Bench Audio 是 Big Bench Hard 问题的一个音频版本子集。该数据集用于评估支持音频输入的模型的推理能力。数据集包含 1000 个音频录音,涵盖以下 Big Bench Hard 类别:
- Formal Fallacies Syllogisms Negation (Formal Fallacies) - 250 个问题
- Navigate - 250 个问题
- Object Counting - 250 个问题
- Web of Lies - 250 个问题
支持的任务和排行榜
- Audio-to-Audio:该数据集可用于评估指令调优的音频到音频模型,也适用于测试音频到文本的管道。排行榜可在 https://artificialanalysis.ai/speech-to-speech 找到。
语言
所有音频录音均为英语,音频是使用来自 Artifical Analysis Speech Arena 的 23 种声音合成生成的。
数据集结构
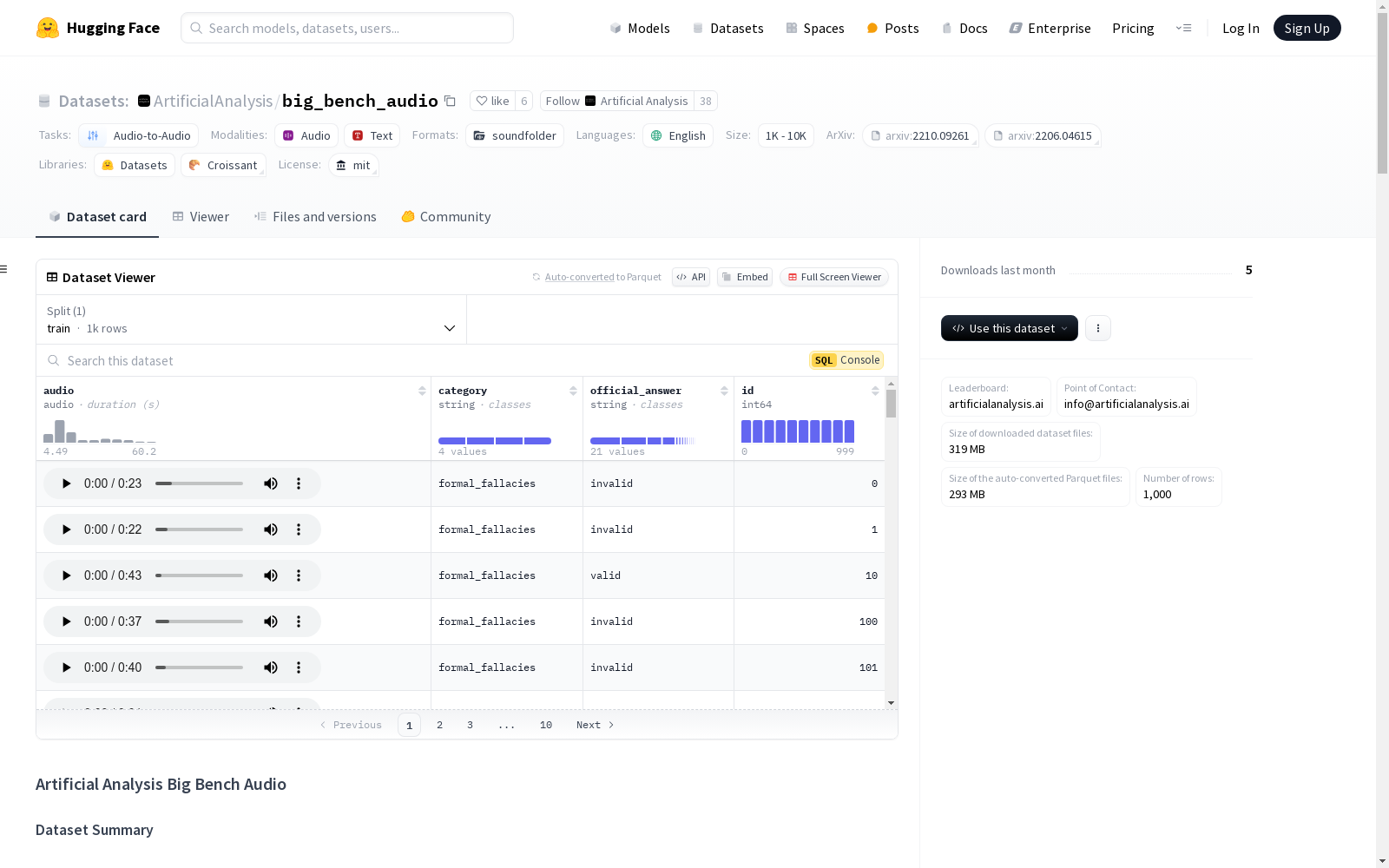
数据实例
每个实例包含四个字段:category、official_answer、file_name、id。
json { "category": "formal_fallacies", "official_answer": "invalid", "file_name": "data/question_0.mp3", "id": 0 }
数据字段
category:关联的 Big Bench Hard 类别official_answer:关联的 Big Bench Hard 答案file_name:包含音频问题的 mp3 文件路径id:每个问题的整数标识符
数据集创建
数据集来源
文本问题直接来自 Big Bench Hard,并在每个基本问题后附加了“. Answer the question”字符串,以生成音频版本的问题。音频生成使用了 OpenAI、Microsoft Azure 和 Amazon 提供的模型,这些模型在 Artifical Analysis Speech Arena 中经过验证,具有高人类偏好。
音频验证
通过计算生成的音频的转录版本与源文本之间的 Levenshtein 距离,并手动审查低于阈值 0.85 的音频文件,确保音频的准确性。
使用数据的注意事项
偏见讨论
所有音频均为英语,主要关注美国和英国口音。过度拟合此基准可能导致忽视其他低资源语言和口音。数据集还继承了原始 Big Bench Hard 数据集中所选类别的任何偏见。
其他信息
数据集策展人
- Micah Hill-Smith
- George Cameron
- Will Bosler
联系方式
引用信息
如果您的研究使用了此数据集,请引用 Artificial Analysis、原始 Big Bench 论文和 Big Bench Hard 论文。
搜集汇总
数据集介绍
构建方式
Big Bench Audio数据集的构建基于Big Bench Hard问题集的一个子集,旨在评估支持音频输入的模型的推理能力。该数据集包含1000个音频记录,涵盖四个类别:形式谬误、导航、对象计数和谎言网络。音频生成过程采用了23种不同的语音配置,来自OpenAI、Microsoft Azure和Amazon等提供商的高质量语音模型。为确保音频质量,通过计算Levenshtein距离并手动审查低于阈值的音频文件,确保生成的音频与原始文本高度一致。
特点
Big Bench Audio数据集的主要特点在于其专注于音频输入的推理任务,涵盖了多个复杂且具有挑战性的类别。所有音频均以英语生成,主要集中在美国和英国口音,确保了语音模型的广泛适用性。此外,数据集的设计避免了在音频环境中难以处理的符号和拼写歧义问题,确保了音频模型在推理任务中的公平评估。
使用方法
Big Bench Audio数据集适用于评估音频到音频模型的推理能力,特别适合测试音频到文本的管道。用户可以通过访问[https://artificialanalysis.ai/speech-to-speech](https://artificialanalysis.ai/speech-to-speech)查看排行榜,并使用数据集中的音频文件进行模型训练和测试。数据集的结构包括类别、官方答案、音频文件路径和问题ID,便于用户进行数据处理和模型评估。
背景与挑战
背景概述
Big Bench Audio数据集是Big Bench Hard问题集的音频版本,由Micah Hill-Smith、George Cameron和Will Bosler等人创建,旨在评估支持音频输入的模型的推理能力。该数据集包含了从Big Bench Hard中精选的四个类别,共计1000个音频问题,涵盖形式谬误、导航、物体计数和谎言网络等复杂任务。通过将文本问题转化为音频形式,Big Bench Audio为语音代理工作流程的简化提供了新的研究方向,同时也为音频模型的智能评估提供了基准。
当前挑战
Big Bench Audio数据集在构建过程中面临多项挑战。首先,音频生成过程中需要确保语音合成的准确性,避免因发音不完全导致的理解偏差。其次,数据集继承了Big Bench Hard的复杂性,要求模型在音频输入下仍能保持高水平的推理能力。此外,数据集主要使用英语和美英口音,可能导致对其他语言和口音的忽视,增加了模型泛化能力的挑战。
常用场景
经典使用场景
Big Bench Audio数据集的经典使用场景主要集中在评估和提升音频输入模型的推理能力。该数据集通过包含1000个音频记录的子集,涵盖了形式谬误、导航、对象计数和谎言网络等四个类别,为研究者提供了一个标准化的测试平台。这些任务不仅要求模型具备基本的音频识别能力,还需要其在复杂情境中进行逻辑推理和问题解决,从而推动音频处理技术在智能语音助手、自动导航系统等领域的应用。
解决学术问题
Big Bench Audio数据集解决了音频处理领域中模型推理能力评估的学术难题。通过引入音频形式的复杂推理任务,该数据集为研究者提供了一个全新的视角,以评估和比较不同音频模型的性能。这不仅有助于揭示现有模型在处理复杂音频输入时的局限性,还为开发更智能、更高效的音频处理算法提供了理论基础和实验数据支持。
衍生相关工作
Big Bench Audio数据集的发布激发了一系列相关研究工作,特别是在音频处理和多模态学习领域。研究者们利用该数据集开发了新的音频识别和推理算法,探索了音频与文本、图像等多模态数据的融合方法。此外,该数据集还促进了跨学科的研究合作,如与语言学、认知科学等领域的结合,进一步推动了音频处理技术的发展和应用。
以上内容由遇见数据集搜集并总结生成


