dgx-spark-kv-cache-benchmark
收藏Hugging Face2026-04-01 更新2026-04-02 收录
下载链接:
https://huggingface.co/datasets/memoriant/dgx-spark-kv-cache-benchmark
下载链接
链接失效反馈官方服务:
资源简介:
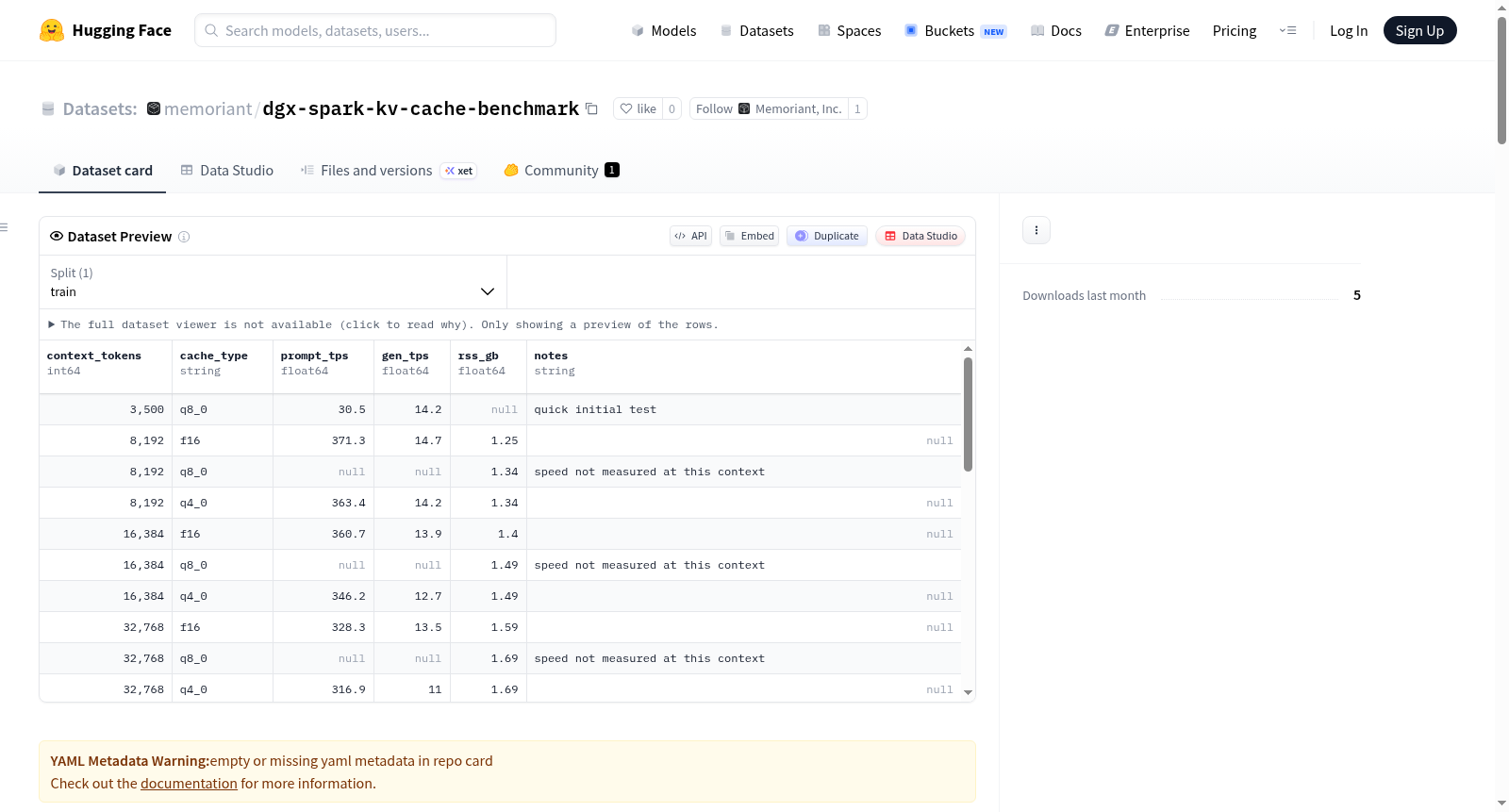
该数据集记录了在NVIDIA DGX Spark GB10硬件上进行的KV缓存量化性能基准测试结果(修正版v3)。研究比较了不同量化类型(f16、q8_0、q4_0)在不同上下文长度下的内存使用和吞吐量表现。主要发现包括:KV缓存量化可显著减少内存使用(q4_0最高节省72%内存),但在长上下文生成时会导致速度下降(110K tokens时q4_0比f16慢37%)。数据集包含详细的硬件配置(NVIDIA DGX Spark GB10,128GB统一内存)、测试方法(使用llama.cpp和nvidia-smi测量)以及原始基准测试数据。适用场景包括大型语言模型推理优化、内存效率与计算性能的权衡研究等。
创建时间:
2026-03-31
原始信息汇总
数据集概述:KV Cache Quantization on NVIDIA DGX Spark GB10
基本信息
- 数据集名称:KV Cache Quantization on NVIDIA DGX Spark GB10
- 作者:Nathan Maine, Memoriant Inc.
- 发布日期:2026年3月,2026年4月修正
- 数据集地址:https://huggingface.co/datasets/memoriant/dgx-spark-kv-cache-benchmark
- 相关链接:https://github.com/Memoriant/dgx-spark-kv-cache-benchmark
核心内容
本数据集提供了在NVIDIA DGX Spark GB10统一内存架构上,对KV缓存进行量化(q4_0和q8_0)与基准(f16)的性能对比基准测试结果。测试重点关注内存占用和吞吐量性能。
关键发现
- 内存节省:KV缓存量化能有效减少内存占用。
- q4_0相比f16节省72%的KV缓冲区内存(216 MiB vs 768 MiB)。
- q8_0相比f16节省47%的KV缓冲区内存(408 MiB vs 768 MiB)。
- 吞吐量影响:
- 提示处理吞吐量:在所有上下文长度下,量化对提示处理吞吐量无影响。
- 生成吞吐量:在长上下文(约110K)下,生成吞吐量出现下降。q4_0相比f16下降约37%(24 tps vs 38 tps)。
测试设置
- 模型:Nemotron-3-Nano-30B-A3B-UD-Q4_K_XL.gguf
- 硬件:NVIDIA DGX Spark GB10(计算能力12.1,124,610 MiB VRAM)
- 软件:llama.cpp build 8399,CUDA 13.0
- 上下文大小:131072
- 测量方法:GPU内存使用通过
nvidia-smi和llama.cpp内部报告测量;吞吐量通过llama.cpp的/v1/chat/completions响应计时测量。
数据修正说明
原始v1版本(2026年3月31日)的基准测试存在方法错误:
- 错误声称“在64K上下文下提示吞吐量崩溃92.5%”。实际提示吞吐量不受缓存量化影响。
- 错误声称“q4_0比f16占用更多内存”。这是由于使用了进程RSS测量,该方法不适用于GB10的GPU/统一内存。实际测量显示q4_0可节省552 MiB内存。 修正后的v3版本(2026年4月)使用了正确的测量方法。
实际结论
KV缓存量化能按预期节省内存,但在长上下文下会对生成速度造成影响。这种权衡取决于使用场景:
- 长上下文RAG(主要是提示,生成令牌少):可使用q4_0以节省内存。
- 长上下文下的长文本生成:可使用f16以保持解码速度。
包含文件
data/benchmark_results_v3_complete.csv:修正后的v3数据。data/benchmark_results.csv:原始的v1数据(有缺陷,仅供参考)。CORRECTION-NOTICE.md:完整的修正和方法比较说明。
引用格式
bibtex @techreport{maine2026kvcache, title = {KV Cache Quantization on NVIDIA DGX Spark GB10}, author = {Maine, Nathan}, institution = {Memoriant Inc.}, year = {2026}, note = {Corrected April 2026}, url = {https://github.com/Memoriant/dgx-spark-kv-cache-benchmark} }
搜集汇总
数据集介绍
构建方式
在大型语言模型推理优化的研究领域,数据集dgx-spark-kv-cache-benchmark的构建遵循了严谨的实证基准测试范式。其核心方法是在NVIDIA DGX Spark GB10统一内存架构上,系统性地对比不同KV缓存量化配置(如f16、q8_0、q4_0)对内存占用与推理吞吐量的影响。测试采用固定模型(Nemotron-3-Nano-30B-A3B-UD-Q4_K_XL.gguf)与工具链(llama.cpp),通过严格控制变量,在不同上下文长度下收集GPU内存(使用nvidia-smi与llama.cpp内部报告)及令牌处理速度数据,并经过版本迭代修正了早期测量方法学的误差,确保了数据的准确性与可复现性。
特点
该数据集揭示了KV缓存量化技术在先进硬件平台上的真实性能特征。其显著特点在于精准量化了内存节省与计算开销之间的权衡关系:量化能有效降低KV缓存内存占用(如q4_0相比f16节省72%),且对提示词处理吞吐量无影响;然而,在生成长文本时,量化会引入显著的解量化开销,导致生成吞吐量下降(如在110K上下文下q4_0比f16慢约37%)。数据集清晰区分了提示处理与令牌生成两种场景的性能差异,为模型部署的优化策略提供了关键依据。
使用方法
研究者与工程师可利用此数据集评估在NVIDIA GB10架构上部署量化大型语言模型的可行性。具体而言,通过分析不同上下文长度下内存与吞吐量的详细基准数据,用户可以针对特定应用场景(如以检索增强生成为主的任务或长文本生成任务)在内存效率与推理速度之间做出最优选择。数据集提供的原始CSV文件支持进一步的数据挖掘与交叉验证,其严谨的测试设置与修正记录也为后续相关基准研究提供了可靠的参考框架与方法学范例。
背景与挑战
背景概述
在大型语言模型推理优化领域,键值缓存量化技术旨在高效管理模型生成过程中的内存占用。由Memoriant Inc.的Nathan Maine于2026年创建的dgx-spark-kv-cache-benchmark数据集,专注于评估NVIDIA DGX Spark GB10统一内存架构上键值缓存量化的性能表现。该数据集的核心研究问题在于精确量化不同精度格式对内存节省与推理速度的影响,为高内存带宽环境下的模型部署提供了关键基准,推动了高效推理技术的实证研究发展。
当前挑战
该数据集致力于解决大语言模型长上下文推理中内存效率与计算速度的平衡挑战,具体体现为量化技术在高负载下导致的生成阶段吞吐量显著下降。在构建过程中,研究团队最初因采用不适用于统一内存架构的RSS测量方法而得出错误结论,凸显了在新型硬件平台上进行精准性能评估的方法学复杂性。后续修正依赖于nvidia-smi与llama.cpp内部报告的协同验证,揭示了量化解压开销在序列生成时的累积效应,这为未来异构计算系统的基准测试确立了更严谨的度量标准。
常用场景
经典使用场景
在大型语言模型推理优化领域,KV缓存量化技术旨在平衡内存占用与计算效率。本数据集通过系统化基准测试,为研究人员提供了在NVIDIA DGX Spark GB10统一内存架构上评估不同量化级别(如q4_0、q8_0)对KV缓存内存节省及生成吞吐量影响的经典场景。它常用于验证量化算法在长上下文处理中的实际表现,特别是在处理高达110K令牌的序列时,量化缓存如何显著降低内存需求,同时揭示生成阶段可能出现的性能折衷。
解决学术问题
该数据集解决了大模型推理中KV缓存内存爆炸与计算开销之间的核心矛盾。通过精确测量量化后缓存的内存占用和吞吐量变化,它量化了统一内存系统中不同精度格式的权衡关系,纠正了早期研究中关于内存测量和吞吐量崩溃的错误结论。其意义在于为学术界提供了可靠的经验数据,推动了对注意力机制中缓存优化策略的深入理解,并促进了高效推理方法的发展,尤其是在资源受限的边缘计算和云端部署场景中。
衍生相关工作
该基准测试衍生了一系列关注大模型高效推理的研究工作。例如,基于其揭示的生成阶段解量化开销问题,后续研究探索了混合精度缓存策略或硬件感知的量化算法,以缓解长上下文下的性能下降。同时,它启发了对统一内存架构中内存测量方法的标准化探讨,促进了类似llama.cpp等推理框架的优化。这些工作共同推动了KV缓存量化从理论到实际部署的成熟进程。
以上内容由遇见数据集搜集并总结生成


