EmoCap100K
收藏arXiv2025-07-29 更新2025-07-30 收录
下载链接:
https://github.com/sunlicai/EmoCapCLIP
下载链接
链接失效反馈官方服务:
资源简介:
EmoCap100K是一个大规模的、语义丰富的面部情感描述数据集,包含超过10万个样本,具有丰富和结构化的语义描述,捕捉到整体情感状态和细微的面部行为。该数据集的创建旨在解决现有面部情感识别系统在表达和适用性上的局限性,通过利用自然语言提供的灵活性和可解释性来提高系统的通用性和实用性。数据集的创建过程包括从电影中提取面部图像,并利用多模态大型语言模型(MLLMs)进行自动标注,以生成全面且结构化的情感描述。EmoCap100K数据集可用于提高面部情感理解的研究,并为学习面部情感表示提供有价值的资源。
EmoCap100K is a large-scale, semantically rich facial emotion description dataset containing over 100,000 samples, with comprehensive and structured semantic descriptions that capture both overall emotional states and subtle facial behaviors. This dataset is developed to address the limitations in expression and applicability of existing facial emotion recognition systems, and improve the generality and practicality of such systems by leveraging the flexibility and interpretability provided by natural language. The construction process of the dataset involves extracting facial images from movies, and utilizing multi-modal large language models (MLLMs) for automatic annotation to generate comprehensive and structured emotional descriptions. The EmoCap100K dataset can be used to advance research in facial emotion understanding, and serves as a valuable resource for learning facial emotion representations.
提供机构:
University of Oulu, Southeast University, University of Turku, Institute of Automation, Chinese Academy of Sciences
创建时间:
2025-07-29
原始信息汇总
EmoCapCLIP 数据集概述
📌 基本信息
- 数据集名称: EmoCapCLIP
- 论文标题: Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
- 论文地址: https://arxiv.org/abs/2507.21015
- 作者: Licai Sun∗, Xingxun Jiang∗, Haoyu Chen, Yante Li, Zheng Lian, Biu Liu, Yuan Zong, Wenming Zheng†, Jukka M. Leppänen, Guoying Zhao†
- 机构: University of Oulu, Southeast University, University of Turku, Institute of Automation, Chinese Academy of Sciences
📝 数据集简介
- 数据集名称: EmoCap100K
- 规模: 超过100,000个样本
- 特点:
- 包含丰富且结构化的语义描述
- 捕捉全局情感状态和细粒度局部面部行为
- 提供自然语言描述作为监督信号
🎯 研究目标
- 解决当前面部情绪识别系统的局限性:
- 过度简化情绪表达为固定类别或抽象维度值
- 缺乏对丰富情绪谱系的捕捉能力
- 利用自然语言的灵活性和表达力:
- 提供更广泛、更丰富的监督来源
- 提高情绪表示的泛化能力和适用性
🏗️ 技术框架
- 方法名称: EmoCapCLIP
- 关键技术:
- 联合全局-局部对比学习框架
- 跨模态引导的正样本挖掘模块
- 全面利用多级标题信息
- 适应紧密相关表达之间的语义相似性
📊 评估结果
- 测试范围: 超过20个基准测试
- 覆盖任务: 5种不同任务
- 性能表现: 展示了优越的性能
📅 发布计划
- 代码状态: 即将发布
- 联系方式: licai.sun@oulu.fi
📚 引用信息
bibtex @article{sun2025learning, title={Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions}, author={Licai Sun, Xingxun Jiang, Haoyu Chen, Yante Li, Zheng Lian, Biu Liu, Yuan Zong, Wenming Zheng, Jukka M. Leppänen, Guoying Zhao}, journal={arXiv preprint arXiv:2507.21015}, year={2025} }
搜集汇总
数据集介绍
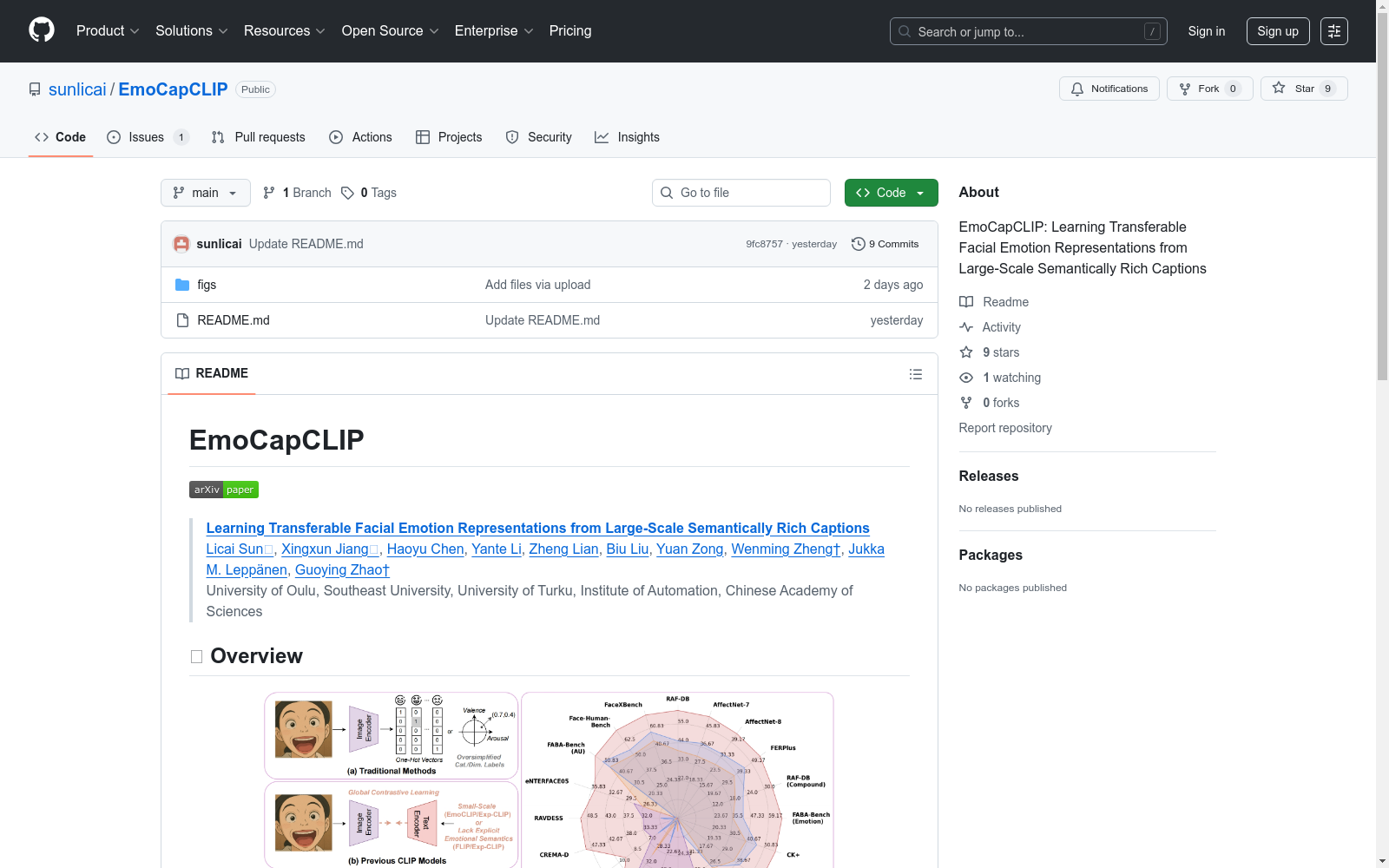
构建方式
EmoCap100K数据集的构建采用了多模态大语言模型(MLLMs)进行自动化标注,以解决传统手动标注成本高昂且规模受限的问题。研究团队从开源平台下载了超过1000部电影,从中提取了涵盖多种头部姿态、场景上下文和情感类别的人脸图像。为确保数据多样性,特别包含了复合情感和非典型情感表达。通过精心设计的提示模板,利用Gemini-1.5-Flash模型生成结构化情感描述,每条标注包含全局情感状态、局部面部行为细节和整合性总结三个层次,形成兼具规模与语义深度的标注体系。
特点
该数据集的核心特点体现在其规模性与语义丰富性:包含107,134个样本,平均每条标注达267词,覆盖703个独特情感词汇。区别于现有面部数据集,EmoCap100K通过层级化标注结构同步捕捉整体情感氛围(如"惊喜的愉悦")与局部微表情特征(如"显著扬起的眉毛"),其标注密度达到同类数据集MAFW的14.8倍。数据分布上突破了传统六种基本情绪的限制,包含大量复合情感状态,并通过电影素材的自然情境保证了表情的动态真实性。
使用方法
EmoCap100K专为视觉-语言对比学习设计,支持全局-局部联合表征训练。使用时需将图像输入视觉编码器(如ViT),文本标注按全局描述、局部行为、总结三部分分别处理。推荐采用论文提出的EmoCapCLIP框架,通过跨模态引导的正样本挖掘模块增强语义关联性。该数据集适用于零样本情感识别、跨模态检索等任务,在RAF-DB等基准测试中,基于其预训练的模型较传统方法提升超20%准确率。对于小样本场景,可通过线性探测或提示微调快速适配下游任务。
背景与挑战
背景概述
EmoCap100K是由芬兰奥卢大学、东南大学、图尔库大学和中国科学院自动化研究所等机构的研究团队于2025年推出的一个大规模面部情感描述数据集。该数据集包含超过10万条样本,通过多模态大语言模型自动生成具有丰富情感语义的标注,旨在解决传统面部情感识别(FER)中固定类别或抽象维度标注的局限性。研究团队利用电影中提取的自然面部表情数据,结合精心设计的提示策略,生成了包含全局情感状态和局部面部行为细节的结构化描述。这一创新工作为情感计算领域提供了更灵活、更具表达力的监督信号,推动了基于自然语言的面部情感表示学习研究。
当前挑战
EmoCap100K面临的挑战主要体现在两个方面:领域问题层面,传统FER系统受限于固定类别或抽象维度标注,难以捕捉情感的连续变化和混合状态,而自然语言标注虽然更具表达力,但缺乏大规模高质量数据集;构建过程层面,人工标注成本高昂且难以保证多样性,研究团队通过多模态大语言模型实现自动化标注,但需要解决提示工程设计和多级语义信息整合等关键技术问题。此外,如何有效利用结构化描述中的全局-局部信息,以及处理语义相近情感表达之间的关系,也是模型设计中的核心挑战。
常用场景
经典使用场景
EmoCap100K数据集在面部情感识别领域具有广泛的应用价值,特别是在零样本学习和少样本学习场景中表现突出。该数据集通过丰富的语义描述,为模型提供了从全局情感状态到局部面部行为的全面监督信号。在零样本静态面部表情识别(SFER)任务中,EmoCap100K支持的模型能够超越传统基于固定类别或维度标签的方法,展现出更强的泛化能力。例如,在RAF-DB和AffectNet等基准测试中,基于EmoCap100K训练的模型在未见过特定类别标签的情况下,仍能准确识别复杂或混合情感状态。
实际应用
在实际应用中,EmoCap100K能够支持多种情感计算场景。在人机交互领域,基于该数据集训练的模型可以更准确地理解用户的情感状态,从而提供更自然的交互体验。在心理健康监测中,模型能够识别细微的情感变化,为早期心理问题筛查提供辅助工具。此外,在娱乐产业如影视作品分析中,EmoCap100K可以帮助自动识别演员的情感表达,为内容分析和推荐提供支持。这些应用场景都得益于数据集对复杂情感状态的细致描述能力。
衍生相关工作
EmoCap100K的提出催生了一系列相关研究工作。基于该数据集开发的EmoCapCLIP框架创新性地结合了全局-局部对比学习和跨模态引导正样本挖掘,成为情感识别领域的新基准。此外,该数据集还启发了更多利用多模态大语言模型生成情感描述的研究,如FABA-Instruct等工作的扩展。在模型架构方面,EmoCap100K促进了针对细粒度情感理解的视觉-语言预训练方法的发展,如后续的SoftCLIP等改进对比学习的工作。这些衍生研究共同推动了情感计算领域从离散分类向连续语义理解的范式转变。
以上内容由遇见数据集搜集并总结生成


