EmbSpatial-Bench
收藏arXiv2024-06-09 更新2024-06-12 收录
下载链接:
官方服务:
资源简介:
EmbSpatial-Bench是由复旦大学数据科学与计算机科学学院创建的一个用于评估大型视觉语言模型(LVLMs)在具身任务中空间理解能力的基准数据集。该数据集包含3640个多选题,覆盖294个对象类别和6种空间关系,数据来源于MP3D、ScanNet和AI2-THOR等具身3D场景。创建过程涉及从3D场景中自动提取空间关系并生成问答对。EmbSpatial-Bench旨在解决LVLMs在具身环境中空间理解能力的评估问题,为具身AI系统的发展提供关键支持。
EmbSpatial-Bench is a benchmark dataset created by the School of Data Science and Computer Science, Fudan University, for evaluating the spatial comprehension capabilities of large vision-language models (LVLMs) in embodied tasks. This dataset contains 3,640 multiple-choice questions, covering 294 object categories and 6 types of spatial relationships, with data sourced from embodied 3D scenes such as MP3D, ScanNet, and AI2-THOR. Its creation process involves automatically extracting spatial relationships from 3D scenes and generating question-answer pairs. EmbSpatial-Bench aims to address the problem of evaluating the spatial comprehension abilities of LVLMs in embodied environments, providing critical support for the development of embodied AI systems.
提供机构:
复旦大学数据科学与计算机科学学院
创建时间:
2024-06-09
搜集汇总
数据集介绍
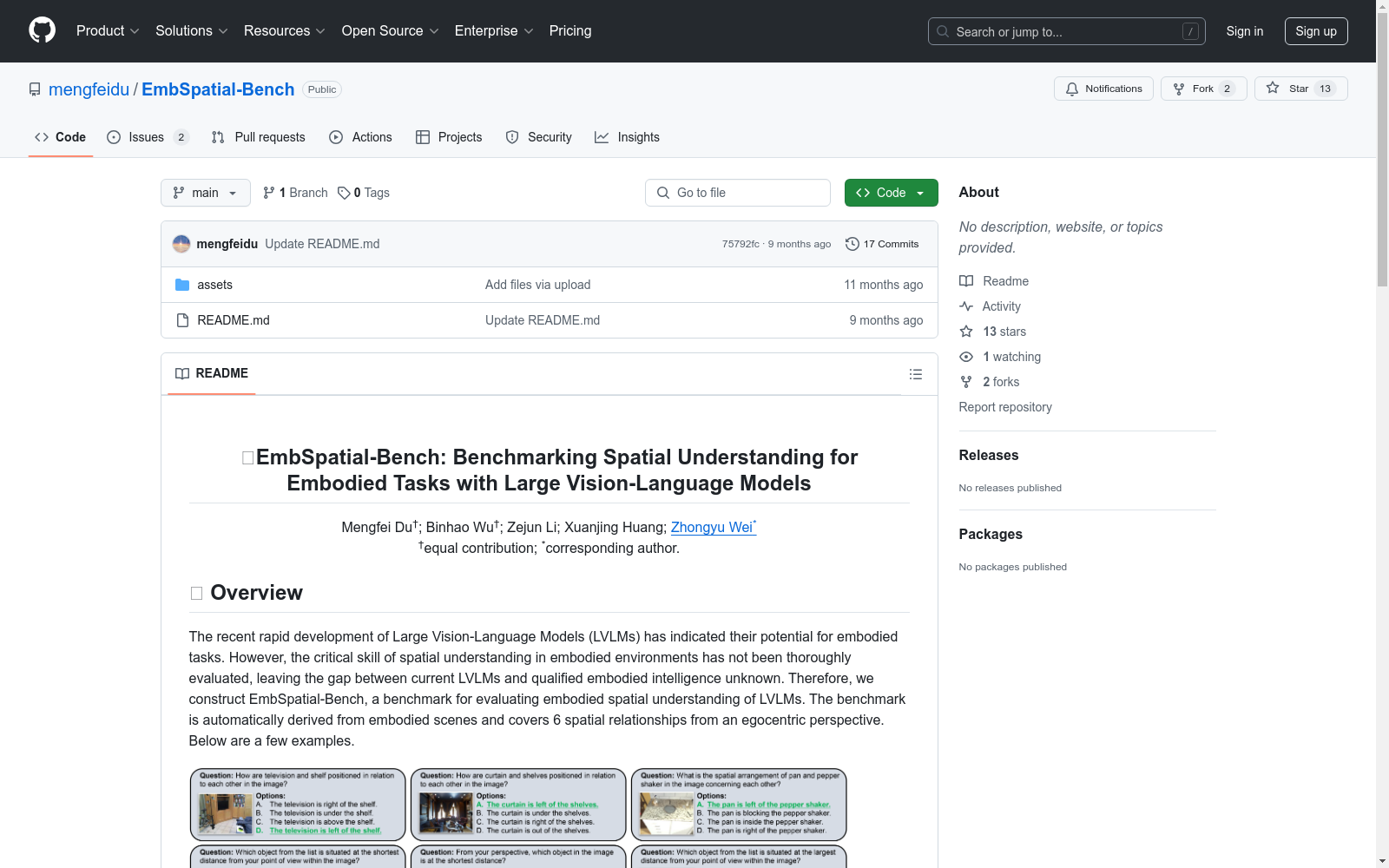
构建方式
EmbSpatial-Bench 数据集的构建基于现有的3D场景数据,通过从第一人称视角描述6种空间关系,包括上、下、左、右、近和远,从而全面覆盖三维坐标的三个维度。数据集采用多选题格式,并直接从具身3D场景中收集用于评估的图像。具体来说,数据集的构建流程包括从MP3D、ScanNet和AI2-THOR等具身3D场景中生成目标图像,并提取物体之间的空间关系。然后,生成QA对并进行过滤。为了保证数据的可靠性,还进行了人工验证,以确保每个样本的准确性。
特点
EmbSpatial-Bench 数据集的特点在于其从第一人称视角描述空间关系,这与具身任务中智能体以自身为中心进行坐标定位和决策的特点相符。此外,数据集的视觉场景与具身任务一致,保证了评估的准确性。数据集的组织格式为多选题,方便进行评估。最后,数据集包含了丰富的物体类别和空间关系组合,提高了评估的可靠性和多样性。
使用方法
EmbSpatial-Bench 数据集的使用方法包括零样本评估和指令微调。零样本评估用于评估当前LVLMs在具身场景中的空间理解能力,通过准确率作为指标。指令微调则用于提高LVLMs的空间理解能力,通过在EmbSpatial-SFT数据集上进行训练来实现。具体来说,EmbSpatial-SFT数据集提供了QA数据,包括空间关系识别和物体定位两个任务。通过对MiniGPT-v2等LVLMs进行指令微调,可以显著提高其在EmbSpatial-Bench数据集上的表现。
背景与挑战
背景概述
在人工智能领域,具身智能(Embodied AI)是通用人工智能系统的前沿方向。具身智能要求智能体能够理解指令、感知物理环境、规划和执行动作以完成任务。近年来,基于大型语言模型(LLMs)的大型视觉语言模型(LVLMs)在遵循指令和基于视觉上下文进行规划方面展现出强大的能力,为具身智能系统的发展开辟了光明的前景。然而,现有研究揭示了LVLMs在理解视觉内容方面的显著缺陷。特别是在具身场景中,理解物体之间的空间关系对智能体有效地与环境交互至关重要。为了评估和提升LVLMs在具身任务中的空间理解能力,研究人员构建了EmbSpatial-Bench,这是一个用于评估LVLMs在具身环境中空间理解能力的基准。该基准是从具身场景自动衍生而来,涵盖了从自我中心视角的六个空间关系。实验结果表明,包括GPT-4V在内的现有LVLMs在空间理解方面能力不足。为了解决这一问题,研究人员还提出了EmbSpatial-SFT,这是一个指令微调数据集,旨在提高LVLMs的空间理解能力。
当前挑战
EmbSpatial-Bench数据集面临的挑战包括:1) LVLMs在空间理解方面的能力不足,无法准确评估其在具身任务中的空间关系理解能力;2) 现有基准主要基于通用的图像文本数据集构建,与具身场景的相关性较弱,难以准确评估LVLMs在具身任务中的空间理解能力;3) 构建EmbSpatial-Bench数据集需要从具身场景中自动提取空间关系,并生成问题,这需要解决空间关系提取、问题生成和过滤等方面的技术挑战。
常用场景
经典使用场景
EmbSpatial-Bench数据集的经典使用场景在于评估大型视觉语言模型(LVLMs)在具身场景中的空间理解能力。通过从第一人称视角描述六种空间关系(包括上方、下方、左侧、右侧、更近和更远),该数据集为研究者提供了一个标准化的评估平台,用以衡量LVLMs在理解具身环境中的空间关系方面的表现。此外,EmbSpatial-SFT数据集被设计为一种指令微调数据集,旨在通过提供空间关系识别和物体定位的任务数据来提高LVLMs的空间理解能力。
衍生相关工作
EmbSpatial-Bench数据集的提出衍生了一系列相关研究工作,如EmbSpatial-SFT指令微调数据集的构建。EmbSpatial-SFT旨在通过提供空间关系识别和物体定位的任务数据来提高LVLMs的空间理解能力。此外,EmbSpatial-Bench的评估结果也激发了研究者对LVLMs空间理解能力提升的探索,如通过改进模型架构、增加训练数据等方法来提高LVLMs的空间理解能力。
数据集最近研究
最新研究方向
Embodied AI领域正迅速发展,特别是在大型视觉语言模型(LVLMs)在执行具身任务方面的潜力。然而,对于具身环境中至关重要的空间理解能力,当前的LVLMs并未得到充分的评估。为了填补这一空白,研究者们构建了EmbSpatial-Bench,一个用于评估LVLMs在具身环境中的空间理解能力的基准。该基准基于具身场景自动生成,涵盖了从自我中心视角出发的6种空间关系。实验结果表明,即使是GPT-4V等当前最先进的LVLMs,在空间理解方面也存在不足。为了解决这个问题,研究者们进一步提出了EmbSpatial-SFT,一个用于提高LVLMs具身空间理解能力的指令调整数据集。经过在EmbSpatial-SFT上的微调,LVLMs在空间感知能力方面得到了显著提升。这一研究不仅揭示了当前LVLMs在具身任务中的空间理解缺陷,也为提高LVLMs的空间理解能力提供了新的方向。
相关研究论文
- 1EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models复旦大学数据科学与计算机科学学院 · 2024年
以上内容由遇见数据集搜集并总结生成


