chcaa/eno-embs-old-news
收藏Hugging Face2026-05-06 更新2025-10-18 收录
下载链接:
https://hf-mirror.com/datasets/chcaa/eno-embs-old-news
下载链接
链接失效反馈官方服务:
资源简介:
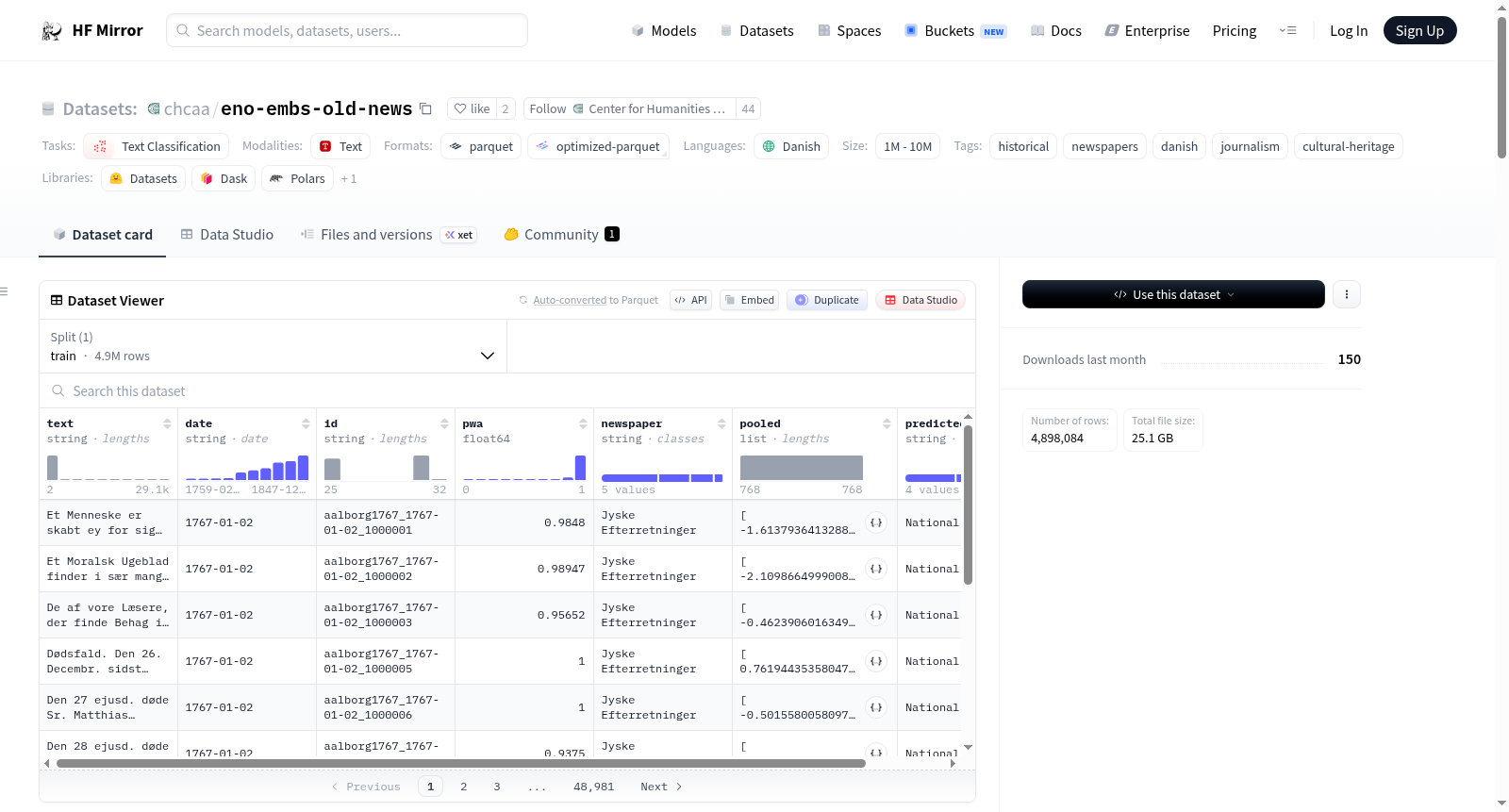
该数据集包含了文本、日期、ID、浮点数、报纸名称、浮点数列表和预测类别等多种类型的数据。数据集被划分为训练集,其中包含了大量的数据示例,适用于机器学习模型的训练。
The dataset includes various types of data such as text, date, ID, floating-point numbers, newspaper names, list of floating-point numbers, and predicted categories. The dataset is split into a training set, which contains a large number of data examples suitable for training machine learning models.
提供机构:
chcaa
搜集汇总
数据集介绍
构建方式
该数据集源自丹麦与挪威国家图书馆珍藏的数字化历史报刊库,收录了1666年至1850年间出版的28种丹麦期刊与报纸,共计约489.8万篇文章。研究者通过光学字符识别技术提取文本,并利用Old_News_Segmentation_SBERT_V0.1模型为每篇文章生成池化嵌入向量,同时结合自动化分类流程赋予预测类别标签。整个处理管线遵循严格的数字化规范,以确保大规模历史语料的机器可读性与语义可比性。
使用方法
数据以Parquet格式存储于单一训练分片中,用户可通过Hugging Face Datasets库便捷加载。研究者可基于文本字段进行语言建模或命名实体识别,利用池化嵌入执行跨文章相似度计算与主题聚类,亦可结合日期与报纸元数据开展历时性语料分析。该资源尤其适用于历史语义变迁追踪、计算新闻学以及丹麦语NLP基准测试等任务。
背景与挑战
背景概述
该数据集由Alie Lassche与Johan Heinsen等人于2026年创建,依托奥胡斯大学与奥尔堡大学的研究力量,旨在为丹麦历史报纸的数字化研究提供结构化、机器可读的语料资源。核心研究问题聚焦于如何利用语义嵌入技术实现大规模历史文本的半自动化分类与主题探索,从而推动丹麦语言、文化与历史的计算分析。数据集收录了约490万篇1666至1850年间丹麦-挪威地区的报纸文章,并附有通过Old_News_Segmentation_SBERT_V0.1模型生成的文档嵌入向量。这一资源为历史语言学、数字人文以及计算新闻学等交叉领域提供了重要的基准数据,在2026年LREC会议上发布后,迅速成为丹麦历史文本挖掘研究的核心支撑。
当前挑战
该数据集所面临的挑战首先体现在领域问题层面:历史报纸文本的自动分类与语义分析需应对OCR识别错误、拼写与正字法的历时演变,以及内容中隐含的时代偏见,这对语言模型的鲁棒性与历史适应性提出了严苛要求。其次,在构建过程中,团队必须克服从丹麦与挪威国家图书馆的海量馆藏中筛选、数字化并统一格式的工程难题,同时确保嵌入模型在历史语料上的评估与选择具备可重现性。此外,覆盖范围的时空不均性——如部分报纸或时期数字化不完整,以及社会阶层、地域和政治立场的选择偏差,也进一步增加了数据集在代表性与通用性上的挑战。
常用场景
经典使用场景
该数据集最为经典的使用场景是历史语篇分析与语义变迁追踪。依托近五百万篇丹麦近代报纸全文及其预计算语义嵌入,研究者可对1666至1850年间丹麦-挪威地区的公众话语进行大规模量化解读。结合自动分类标签与时间戳,学者能够追溯特定主题(如战争、启蒙思想或宗教信仰)在漫长世纪中的浮现、扩散与消退轨迹,从而将历史新闻学从传统的个案诠释推向可重复、可验证的计算范式。
解决学术问题
该数据集直面的核心学术问题在于历史人文研究中质性与量化方法的断裂。传统上,研究19世纪以前的社会思潮严重依赖少量代表性文本的细读,难以覆盖语料的全景。此数据集通过提供结构化的全文、元数据与嵌入向量,使研究者得以应用文本分类、主题建模及聚类分析等技术来弥补样本偏差,揭示了新闻报道中隐含的意识形态倾向与媒体框架,为人文学者提供了一种兼具广度与深度的分析途径,极大地推动了数字人文学科的方法论革新。
实际应用
在实际应用层面,该数据集为文化遗产数字化保护与语义检索系统提供了关键基础设施。图书馆与档案馆可利用其预计算嵌入快速构建相似文章搜索工具,使历史学家能够以语义而非仅关键词的方式检索分散于不同报纸中的关联内容。此外,自动化分类标签可用于构建历史新闻流的时间线可视化,面向教育领域开发交互式历史知识图谱,帮助公众与学者更直观地理解丹麦近代社会变迁的媒介脉络。
数据集最近研究
最新研究方向
在数字人文与自然语言处理交叉领域,eno-embs-old-news数据集为历史语篇的语义计算开辟了新路径。该数据集汇聚了约490万篇1666至1850年间丹麦报纸文章,并嵌入基于Old_News_Segmentation_SBERT_V0.1模型的稠密向量表示,成为研究早期近代丹麦媒介生态、语言演变及文化史志的重要数字基础设施。当前前沿方向聚焦于利用预计算嵌入进行跨时代的主题建模与语义变迁追踪,例如,通过比较不同时期新闻分类的分布格局,揭示启蒙运动、政治革命及社会运动在丹麦公共话语中的回响。此外,研究者正借助该资源评估历史文本在嵌入模型中的表征鲁棒性,推动针对古丹麦语的命名实体识别与细粒度情感分析。结合OCR不确定性评估与历史偏见纠偏,该数据集正在催生可复现的文化分析范式,为计算历史学提供从微观叙事到宏观趋势的量化桥梁。
以上内容由遇见数据集搜集并总结生成


