Lifan-Z/Chinese-poetries-txt
收藏Hugging Face2023-12-19 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Lifan-Z/Chinese-poetries-txt
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- text-generation
language:
- zh
tags:
- art
---
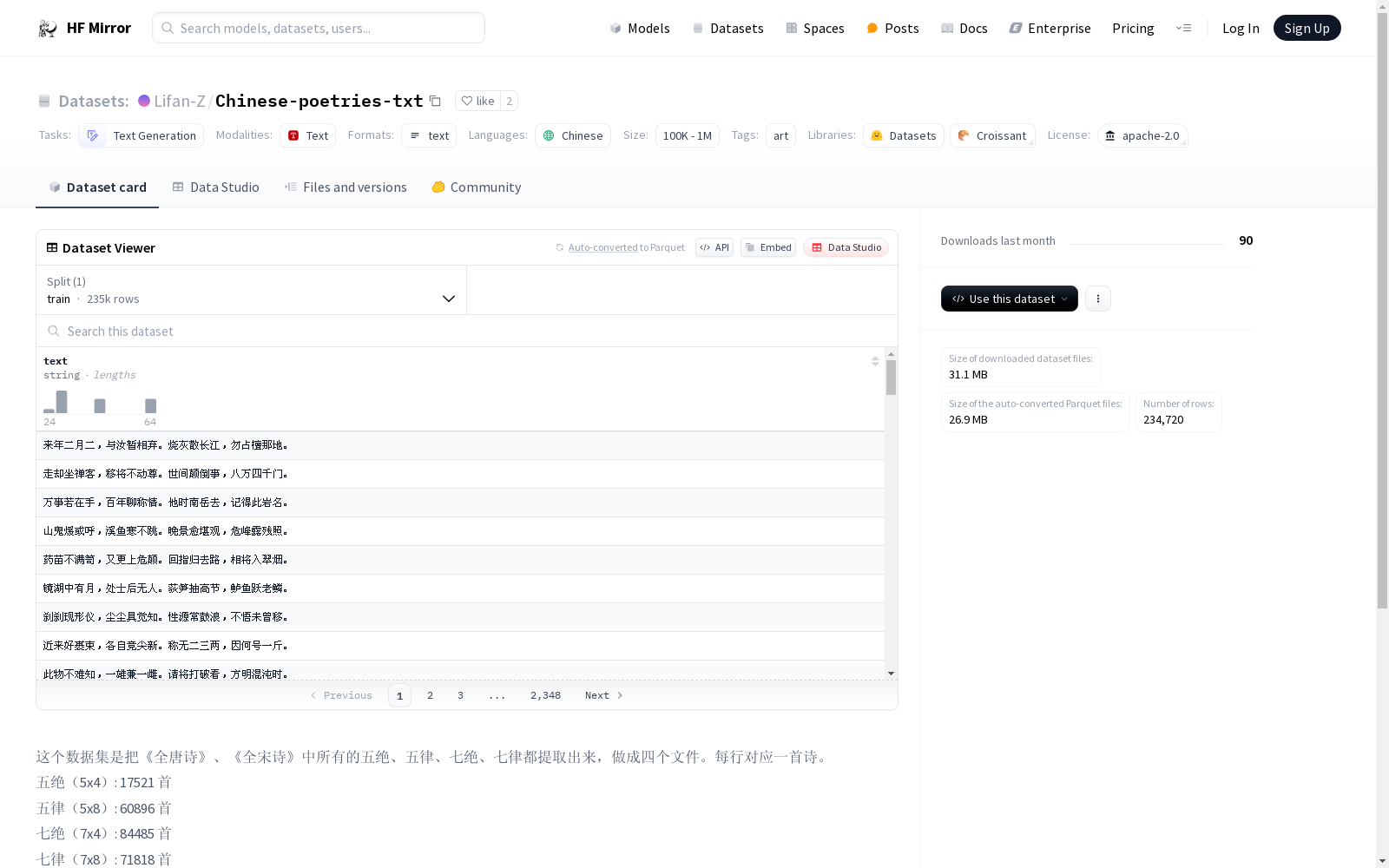
这个数据集是把《全唐诗》、《全宋诗》中所有的五绝、五律、七绝、七律都提取出来,做成四个文件。每行对应一首诗。
五绝(5x4): 17521 首
五律(5x8): 60896 首
七绝(7x4): 84485 首
七律(7x8): 71818 首
This dataset extracts four styles of poetries in "Complete Poems of the Tang Dynasty" and "Complete Poems of the Song Dynasty."
Each line corresponds to a Chinese poem.
The syle on 5x4: 17521
The syle on 5x8: 60896
The syle on 7x4: 84485
The syle on 7x8: 71818
The raw data source from https://github.com/chinese-poetry/chinese-poetry/tree/master/%E5%85%A8%E5%94%90%E8%AF%97
许可证:Apache-2.0
任务类别:文本生成
语言:中文
标签:艺术
本数据集从《全唐诗》与《全宋诗》中提取全部五言绝句、五言律诗、七言绝句、七言律诗四类古典诗歌体裁,生成四个对应的数据文件,每个文件内每一行对应一首诗歌。各类体裁的诗歌数量统计如下:
五言绝句(5x4):17521首
五言律诗(5x8):60896首
七言绝句(7x4):84485首
七言律诗(7x8):71818首
原始数据来源:https://github.com/chinese-poetry/chinese-poetry/tree/master/%E5%85%A8%E5%94%90%E8%AF%97
提供机构:
Lifan-Z
原始信息汇总
数据集概述
数据集描述
这个数据集是从《全唐诗》和《全宋诗》中提取的四种风格的诗歌,每行对应一首诗。
诗歌类型及数量
- 五绝(5x4): 17521 首
- 五律(5x8): 60896 首
- 七绝(7x4): 84485 首
- 七律(7x8): 71818 首
语言
- 中文
标签
- 艺术
许可
- Apache 2.0
任务类别
- 文本生成
搜集汇总
数据集介绍
构建方式
该数据集的构建采取了对《全唐诗》及《全宋诗》中特定格式的诗作进行系统提取的方式,涵盖五言绝句、五言律诗、七言绝句与七言律诗四种体裁。通过从原始文本中筛选出符合格式要求的诗歌,每一行文本代表一首独立诗作,从而构建了一个结构化且便于处理的文本数据集。
特点
此数据集的特点在于其内容的丰富性与体裁的专一性。它包含了大量的古典诗歌,总计近二十八万首,为研究中国古代文学、尤其是诗歌创作提供了珍贵的一手资料。此外,按照诗歌格式分类存储,便于用户针对不同体裁进行专门的研究与应用。
使用方法
在使用该数据集时,用户可以直接访问数据集中的四个文件,每个文件对应一种诗歌体裁。用户可以根据自身需求,采用文本处理工具对数据集进行读取、筛选与分析。同时,数据集遵循Apache-2.0协议,保证了用户在使用数据时的合法性与便捷性。
背景与挑战
背景概述
Lifan-Z/Chinese-poetries-txt数据集,一项汇聚了中国古典文学精华的宝贵资源,其搜集整理了《全唐诗》及《全宋诗》中的五绝、五律、七绝与七律四种诗歌形式,共计近二十八万首诗篇。该数据集的创建,不仅是对古代诗歌文献的数字化保存,也为文本生成、自然语言处理等领域的研究提供了丰富的文本素材。其诞生可追溯至近年来对古典文学与人工智能结合研究的深入,由数据集创建者Lifan-Z精心打造,并以Apache-2.0许可证开源共享,对推动中文艺术文本处理研究有着不容忽视的贡献。
当前挑战
尽管Lifan-Z/Chinese-poetries-txt数据集为研究者提供了丰富的资源,但在使用过程中亦面临着诸多挑战。首先,数据集的构建过程中需克服文献整理、文本清洗和格式统一的难题,确保数据质量。其次,在研究领域问题方面,如何利用这一数据集提升文本生成模型的文学创作能力,以及如何准确评估生成文本的艺术价值,都是当前面临的挑战。此外,数据集在标注和诗歌风格分类方面可能存在的偏差,也给相关研究带来了额外的复杂性。
常用场景
经典使用场景
在自然语言处理领域,Lifan-Z/Chinese-poetries-txt数据集被广泛用于文本生成任务,尤其是诗歌创作。其丰富的古典诗歌文本为模型提供了充足的学习素材,使得模型能够模仿古代诗人的风格,创作出韵律和谐、意境深远的诗歌。
衍生相关工作
基于该数据集,研究者们已经衍生出一系列相关工作,如诗歌风格分类、情感分析以及诗歌创作中的语言模型研究,这些工作不仅推动了古典文学研究的进展,也为自然语言处理技术的创新发展提供了新的视角。
数据集最近研究
最新研究方向
在自然语言处理与文学研究的交汇领域,Lifan-Z/Chinese-poetries-txt数据集的应用正日益广泛。近期研究聚焦于文本生成任务,尤其是探索古典诗词的创作规律与生成模型。学者们借助此数据集,深入剖析五言绝句、五言律诗、七言绝句及七言律诗的结构特点,以期为现代诗歌创作提供算法支持,同时推动文学作品的智能化普及。此外,该数据集亦成为研究古代文学风格、流派及作者风格特色的宝贵资源,对深化文学领域的数据驱动研究具有不可忽视的影响和意义。
以上内容由遇见数据集搜集并总结生成


