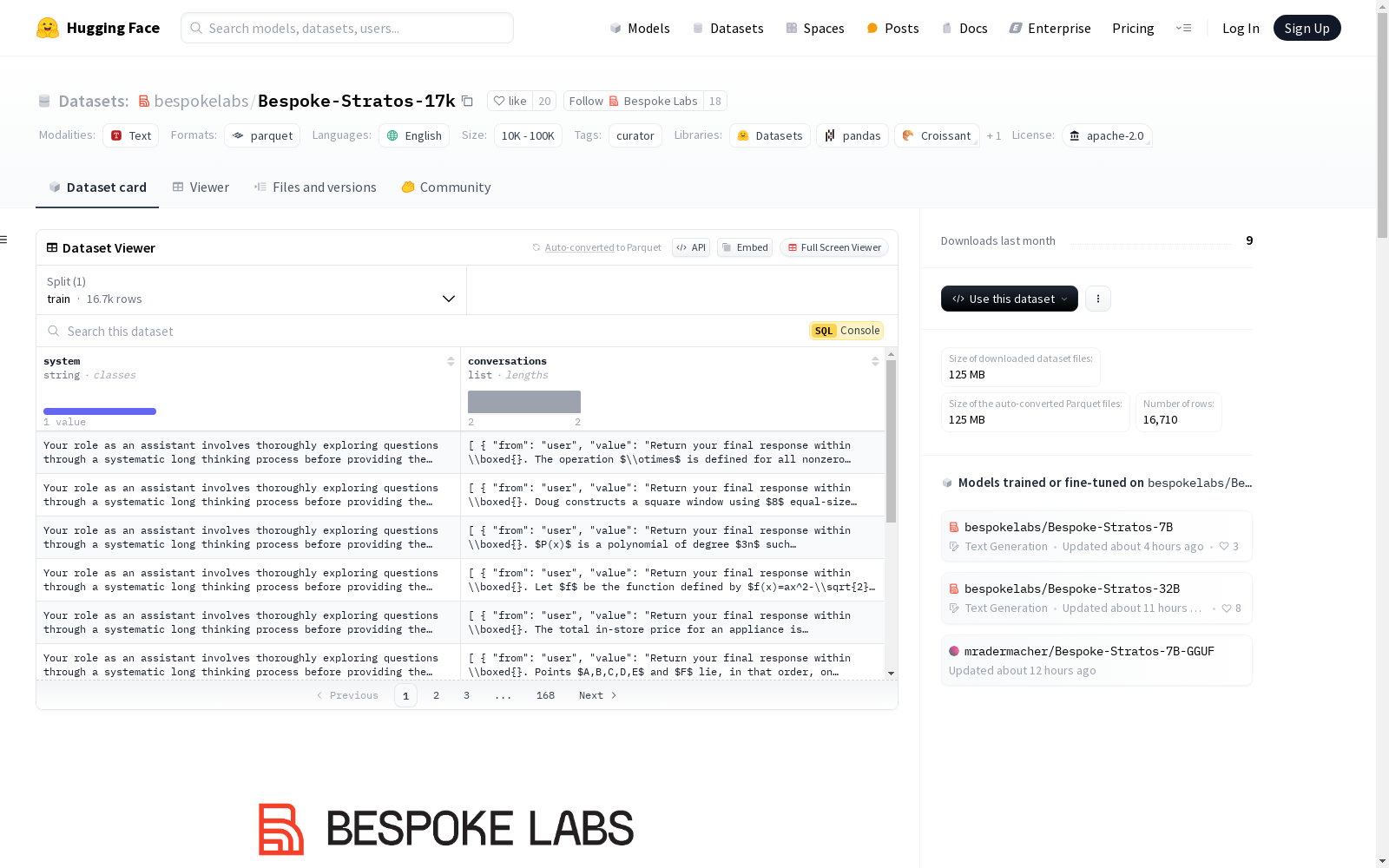
Bespoke-Stratos-17k
收藏Hugging Face2025-01-22 更新2025-01-23 收录
下载链接:
https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k
下载链接
链接失效反馈官方服务:
资源简介:
Bespoke-Stratos-17k是一个推理数据集,包含问题、推理轨迹和答案。该数据集是通过复制和改进Berkeley Sky-T1数据管道,并使用DeepSeek-R1的SFT蒸馏数据创建的。数据集用于训练两个模型:Bespoke-Stratos-32B和Bespoke-Stratos-7B。Bespoke-Stratos-32B是基于Qwen-2.5-32B-Instruct微调的32B推理模型,而Bespoke-Stratos-7B是基于Qwen-2.5-7B-Instruct微调的7B推理模型。数据集的生成过程使用了Bespoke Curator工具,并在1.5小时内完成,成本为800美元。与Sky-T1相比,Bespoke-Stratos-17k使用了DeepSeek-R1作为教师推理模型,并且没有重新格式化DeepSeek-R1的推理轨迹。此外,使用了gpt-4o-mini来过滤错误的数学解决方案,从而提高了正确解决方案的保留率。
Bespoke-Stratos-17k is a reasoning dataset containing questions, reasoning traces and answers. This dataset was created by replicating and improving the Berkeley Sky-T1 data pipeline, using the SFT distilled data of DeepSeek-R1. It is used to train two models: Bespoke-Stratos-32B and Bespoke-Stratos-7B. Bespoke-Stratos-32B is a 32-billion-parameter reasoning model fine-tuned based on Qwen-2.5-32B-Instruct, while Bespoke-Stratos-7B is a 7-billion-parameter reasoning model fine-tuned based on Qwen-2.5-7B-Instruct. The dataset generation process used the Bespoke Curator tool, completed within 1.5 hours with a cost of $800. Compared with Sky-T1, Bespoke-Stratos-17k uses DeepSeek-R1 as the teacher reasoning model without reformatting its reasoning traces. Additionally, gpt-4o-mini was used to filter incorrect mathematical solutions, thereby improving the retention rate of correct solutions.
创建时间:
2025-01-21
搜集汇总
数据集介绍
构建方式
Bespoke-Stratos-17k数据集的构建基于对Berkeley Sky-T1数据管道的复现与改进,采用了DeepSeek-R1的SFT蒸馏数据。通过Bespoke Curator工具,研究团队在1.5小时内生成了包含17,000条推理数据的数据集,涵盖了问题、推理轨迹和答案。数据生成过程中,使用了拒绝采样技术,过滤掉推理轨迹中错误的解决方案,并通过Ray集群加速代码验证过程。此外,研究团队还引入了gpt-4o-mini模型来减少数学解决方案中的误判,显著提高了正确解决方案的保留率。
使用方法
Bespoke-Stratos-17k数据集主要用于训练和评估推理模型,如Bespoke-Stratos-32B和Bespoke-Stratos-7B。用户可以通过Hugging Face平台访问该数据集,并利用其提供的代码库进行数据生成和模型训练。数据集的使用方法包括加载数据、进行模型微调以及评估模型性能。研究团队还提供了详细的训练和评估代码,用户可以参考Sky-T1的代码库进行进一步的操作。此外,数据集的使用者还可以根据需求调整拒绝采样的参数,以优化模型的推理能力。
背景与挑战
背景概述
Bespoke-Stratos-17k数据集由Bespoke Labs于2025年创建,旨在通过改进Berkeley Sky-T1的数据管道,结合DeepSeek-R1的SFT蒸馏数据,生成一个包含问题、推理轨迹和答案的推理数据集。该数据集的核心研究问题在于提升大规模语言模型在复杂推理任务中的表现,特别是在数学、编程和科学领域的应用。Bespoke-Stratos-17k的创建不仅推动了推理模型的发展,还为相关领域的研究提供了高质量的训练数据,显著提升了模型在AIME、MATH500等基准测试中的表现。
当前挑战
Bespoke-Stratos-17k数据集在构建过程中面临多重挑战。首先,推理轨迹的生成和验证需要极高的准确性,尤其是在代码验证方面,传统的验证方法效率低下,需借助Ray集群加速处理。其次,数据集的构建依赖于复杂的拒绝采样技术,以过滤掉错误的推理轨迹,这一过程在数学问题的解决方案中尤为关键。此外,尽管DeepSeek-R1的推理轨迹格式较为规范,但仍需通过gpt-4o-mini等工具进一步优化,以减少误判并提高正确解决方案的保留率。这些挑战不仅考验了数据处理的技术能力,也对计算资源提出了较高要求。
常用场景
经典使用场景
Bespoke-Stratos-17k数据集在推理模型的训练和评估中展现了其经典应用场景。该数据集通过整合来自多个领域的数学、编程和科学问题,为模型提供了丰富的推理任务。特别是在训练Bespoke-Stratos-32B和Bespoke-Stratos-7B等大规模推理模型时,数据集中的问题、推理轨迹和答案被用于优化模型的推理能力,使其在复杂任务中表现出色。
解决学术问题
Bespoke-Stratos-17k数据集解决了推理模型在复杂任务中表现不佳的学术问题。通过引入高质量的推理轨迹和答案,数据集显著提升了模型在数学、编程和科学领域的推理能力。此外,数据集通过拒绝采样技术过滤错误推理轨迹,确保了训练数据的准确性,从而为推理模型的性能提升提供了可靠的数据支持。
实际应用
在实际应用中,Bespoke-Stratos-17k数据集被广泛用于开发高性能的推理模型,这些模型在教育、科研和工业领域具有重要价值。例如,在教育领域,基于该数据集训练的模型可以辅助学生解决复杂的数学和编程问题;在科研领域,模型能够加速科学问题的推理过程;在工业领域,推理模型则被用于优化自动化系统的决策能力。
数据集最近研究
最新研究方向
在人工智能领域,推理能力的提升一直是研究的热点之一。Bespoke-Stratos-17k数据集通过改进Berkeley Sky-T1的数据管道,结合DeepSeek-R1的SFT蒸馏数据,生成了一个包含问题、推理轨迹和答案的推理数据集。该数据集不仅用于训练Bespoke-Stratos-32B和Bespoke-Stratos-7B等推理模型,还在多个基准测试中展现了显著的性能提升。特别是在AIME2024和MATH500等数学推理任务中,Bespoke-Stratos-32B的表现远超Sky-T1-32B,显示出其在复杂推理任务中的强大能力。此外,通过引入gpt-4o-mini进行数学解决方案的过滤,进一步提高了数据集的准确性和可靠性。这些进展不仅推动了推理模型的发展,也为未来在科学、工程等领域的应用奠定了坚实的基础。
以上内容由遇见数据集搜集并总结生成


