MUIRBENCH
收藏Hugging Face2024-06-18 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MUIRBENCH/MUIRBENCH
下载链接
链接失效反馈官方服务:
资源简介:
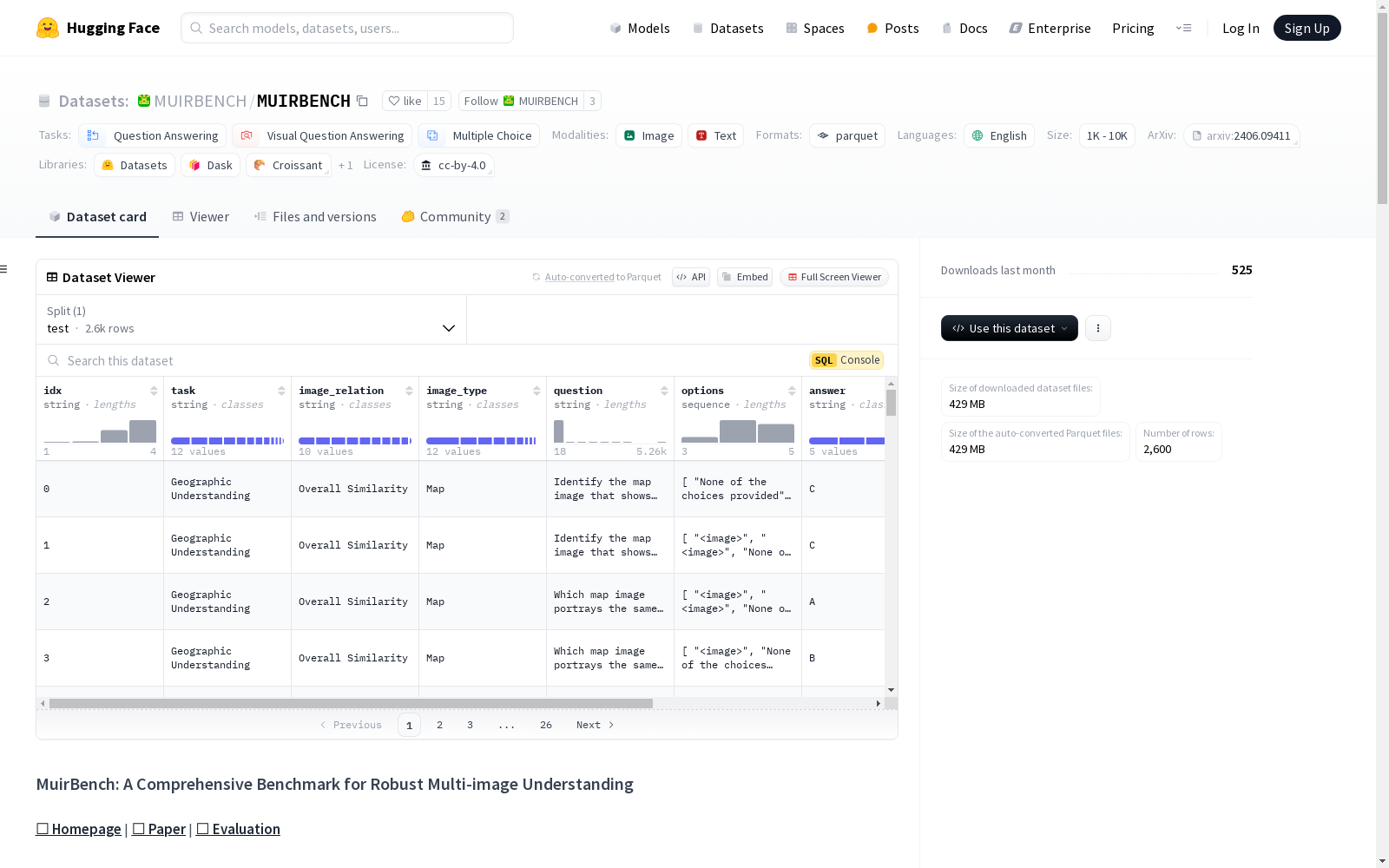
MuirBench是一个包含多种任务类别的数据集,主要包括问答、视觉问答和多选题。数据集包含的样本数量在1000到10000之间,适用于进行问答和视觉问答任务的研究和测试。数据集的特征包括索引、任务类型、图像关系、图像类型、问题、选项、答案以及相关的图像列表。
创建时间:
2024-06-06
原始信息汇总
MuirBench 数据集概述
基本信息
- 语言: 英语
- 许可: CC-BY-4.0
- 数据规模: 1K<n<10K
- 任务类别:
- 问答
- 视觉问答
- 多选题
- 数据集名称: MuirBench
数据集详情
- 特征:
idx: 字符串task: 字符串image_relation: 字符串image_type: 字符串question: 字符串options: 字符串序列answer: 字符串image_list: 图像序列counterpart_idx: 字符串
- 分割:
test: 2600个样本,2280382684.8字节
- 下载大小: 429440985字节
- 数据集大小: 2280382684.8字节
配置
- 配置名称: default
- 数据文件:
split: testpath: data/test-*
- 数据文件:
数据集介绍
- 包含图像数量: 11,264张
- 包含问题数量: 2,600个多选题
- 评估任务: 12种多图像理解任务
- 图像关系: 10种多样化的多图像关系
- 不可回答实例: 通过三种主要方式创建不可回答实例,以提供模型鲁棒性评估
评估结果
- 评估模型: 20个近期多模态大型语言模型(LLMs)
- 最佳模型表现: GPT-4o和Gemini Pro分别达到68.0%和49.3%的准确率
- 开源模型表现: 基于单图像训练的多模态LLMs在多图像问题上准确率低于33.3%
搜集汇总
数据集介绍
构建方式
MuirBench数据集的构建基于多图像理解任务,涵盖了11,264张图像和2,600道多项选择题。该数据集通过12种多图像理解任务进行评估,包括地理理解、图表理解和视觉检索等。为了增强模型的鲁棒性,数据集还引入了不可回答的实例变体,通过三种主要方式生成这些变体,确保模型在多图像场景下的表现得到全面测试。
特点
MuirBench数据集的特点在于其多样性和复杂性。它不仅包含10种不同的多图像关系,如叙事性和互补性,还通过不可回答的实例变体提供了对模型的严格评估。数据集的多图像任务设计使得模型需要超越单一图像的理解能力,从而在更广泛的应用场景中表现出色。此外,数据集的图像和问题均来源于已建立的图像数据集,确保了数据的可靠性和多样性。
使用方法
MuirBench数据集的使用方法主要包括下载数据集文件并加载到支持多模态任务的模型中进行评估。用户可以通过HuggingFace平台获取数据集的测试集,路径为`data/test-*`。数据集支持多种任务类型,如问答、视觉问答和多项选择,用户可以根据需要选择相应的任务进行模型训练和测试。此外,数据集的评估结果可以通过GitHub上的评估工具进行复现,帮助用户更好地理解模型在多图像理解任务中的表现。
背景与挑战
背景概述
MuirBench数据集由南加州大学的Fei Wang和宾夕法尼亚大学的Xingyu Fu等研究人员于2024年提出,旨在为多图像理解任务提供一个全面的基准测试。该数据集包含11,264张图像和2,600道多项选择题,涵盖了12种多图像理解能力,如地理理解、图表理解和视觉检索等。与以往仅关注单图像问题的基准不同,MuirBench通过引入10种多样化的多图像关系(如叙事性和互补性等),进一步扩展了多模态模型的应用场景。该数据集的发布为多模态大语言模型(LLMs)的研究提供了新的挑战和机遇,推动了相关领域的技术进步。
当前挑战
MuirBench数据集在解决多图像理解问题时面临多重挑战。首先,现有的多模态大语言模型在处理多图像问题时表现不佳,即使是表现最佳的模型如GPT-4o和Gemini Pro,其准确率也仅为68.0%和49.3%。其次,开源的多模态模型在单图像训练数据上难以泛化到多图像问题,准确率普遍低于33.3%。此外,数据集的构建过程中,研究人员需要处理复杂的多图像关系,并生成不可回答的实例以增强模型的鲁棒性。这些挑战不仅揭示了当前模型的局限性,也为未来多模态模型的发展指明了方向。
常用场景
经典使用场景
MuirBench数据集主要用于评估多图像理解任务中的模型性能,特别是在多图像关系、地理理解、图表理解等复杂场景下的表现。通过提供2600个多项选择题和11264张图像,该数据集能够全面测试模型在多图像环境下的推理能力。
衍生相关工作
MuirBench的发布催生了一系列相关研究工作,特别是在多模态大语言模型的改进方面。许多研究团队基于该数据集开发了新的模型架构和训练方法,以提升模型在多图像理解任务中的表现。此外,该数据集还促进了多模态模型在跨领域应用中的探索。
数据集最近研究
最新研究方向
近年来,多模态大语言模型(LLMs)在单图像理解任务中取得了显著进展,但在多图像理解领域仍面临巨大挑战。MuirBench作为一个包含11,264张图像和2,600道多选题的基准测试,专注于评估模型在12种多图像理解任务中的表现,如地理理解、图表理解和视觉检索等。该数据集通过引入不可回答实例变体,进一步增强了评估的鲁棒性。研究表明,即使是表现最佳的模型如GPT-4o和Gemini Pro,在MuirBench上的准确率也仅为68.0%和49.3%,而开源的多模态LLMs在单图像训练下的泛化能力较差,准确率普遍低于33.3%。这些结果凸显了MuirBench在推动多模态LLMs超越单图像理解、探索多图像关系理解方面的重要作用,为未来模型改进提供了潜在的研究方向。
以上内容由遇见数据集搜集并总结生成


