Nexus-Gen训练数据集
收藏魔搭社区2026-06-07 更新2025-07-26 收录
下载链接:
https://modelscope.cn/datasets/DiffSynth-Studio/Nexus-Gen-Training-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
# Nexus-Gen Training Dataset
## Intruduction
This dataset contains the complete training data for [Nexus-Gen](https://www.modelscope.cn/models/DiffSynth-Studio/Nexus-GenV2), covering tasks including image understanding, generation, and editing. For details about training Nexus-Gen, please refer to the [tech report](https://arxiv.org/abs/2504.21356) and [github repo](https://github.com/modelscope/Nexus-Gen).
All annotations are unified into the [standard messages format](https://swift.readthedocs.io/en/latest/Customization/Custom-dataset.html), stored in JSONL files. A single annotation example includes:
* `images`: List of relative image paths, e.g. `["t2i/Flux/000055/000055_495587.png"]`
* `messages`: Messages for training the language model, e.g.
```json
[
{"role": "user", "content": "Generate an image according to the following description: A charming cartoon mouse with a light brown fur coat stands upright on its hind legs."},
{"role": "assistant", "content": "Here is an image based on the description: <image>"}
]
```
* id: Unique data identifier, e.g. `"EliGen_495587"`
* source: Sample source, e.g. `"EliGen"`
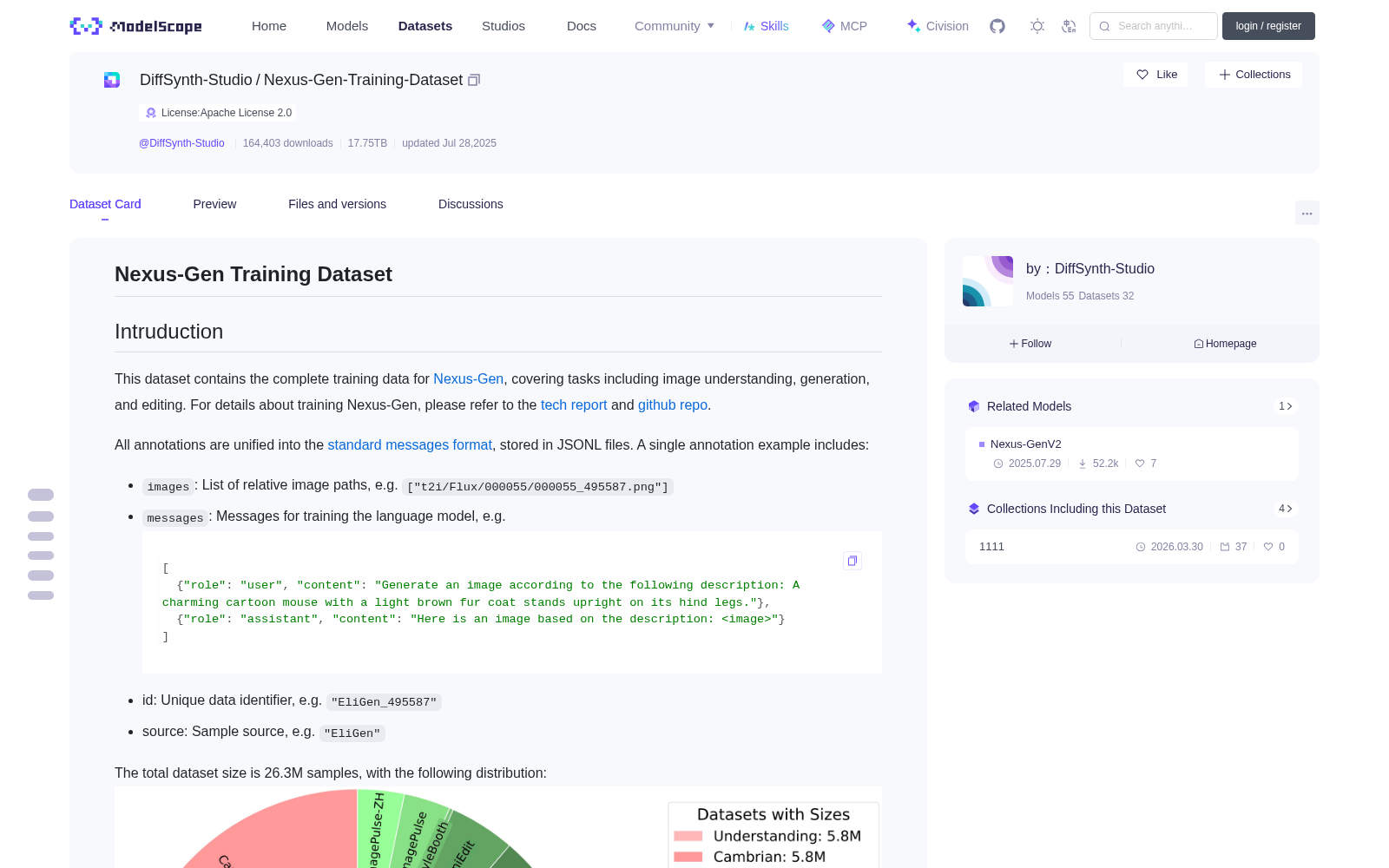
The total dataset size is 26.3M samples, with the following distribution:

To facilitate model training and open-source usage, we further partition the annotations into stage-level annotations and task-level annotations. Since annotation files are large, see ./previews for more sample annotations.
### Stage-Level Annotations
1. `autoregressive_model_pretraining_26.3M.jsonl`: Includes all 26.3 million training samples for pretraining the autoregressive model.
2. `autoregressive_model_aes_finetuning_4.3M.jsonl`: This subset is used for quality fine-tuning of the autoregressive model. Image generation samples are restricted to high-quality subsets, while image editing samples primarily come from the ImagePulse subset.
3. `generation_decoder_1.7M.jsonl`: Subset used to train Nexus-Gen’s generation decoder, containing only high-quality image generation samples.
4. `editing_decoder_0.85M.jsonl`: Subset used to train Nexus-Gen’s editing decoder, exclusively sourced from the ImagePulse image editing dataset.
### Task Level Annotations
1. `image_understanding_5.8M.jsonl`: This task is structured with multimodal inputs (image-text pairs) and text-only outputs, which serves as a direct indicator of model’s chat and understanding ability. While MLLMs inherently possess such cross-modal reasoning capabilities, this task is still critical during training to prevent capacity degradation. We adopt [Cambrian-7M](https://huggingface.co/datasets/nyu-visionx/Cambrian-10M) as the data source, a comprehensive dataset spanning multiple domains including optical character recognition, general visual question answering, language, counting, code, math and science tasks. To improve data quality, we re-annotate the answers for all samples with Qwen2.5-VL-72B.
2. `image_generation_13.3M.jsonl`: The input for this task is the textual description, and the output is an image. Our data sources comprise [Journey DB](https://huggingface.co/datasets/JourneyDB/JourneyDB), [AnyWord](https://modelscope.cn/datasets/iic/AnyWord-3M/summary), [Laion-High-Resolution](https://huggingface.co/datasets/laion/laion-high-resolution), [EliGen TrainSet](https://modelscope.cn/datasets/DiffSynth-Studio/EliGenTrainSet), [FLUX-Aes](https://huggingface.co/datasets/gogoduan/flux_laion_aes), [FLUX-T2I](https://huggingface.co/datasets/jackyhate/text-to-image-2M) and [Blip3o-60K](https://huggingface.co/datasets/BLIP3o/BLIP3o-60k). To enhance annotation diversity, we employ a dual-captioning paradigm via Qwen2.5-VL-72B, generating both concise captions and elaborate descriptions for each image. During training, we stochastically sample these annotations with stratified ratios (20\% concise vs. 80\% elaborate) to balance brevity and contextual granularity.
3. `image_editing_6.3M.jsonl`: The input for editing task consists of an image and its corresponding editing instruction, and the output denotes the edited image. Our data sources encompass datasets such as [HQ-Edit](https://huggingface.co/datasets/UCSC-VLAA/HQ-Edit), [UltraEdit](https://huggingface.co/datasets/BleachNick/UltraEdit), [OmniEdit](https://huggingface.co/datasets/TIGER-Lab/OmniEdit-Filtered-1.2M), [StyleBooth](https://ali-vilab.github.io/stylebooth-page/) and [ImagePulse](https://modelscope.cn/collections/ImagePulse----tulvmaidong-7c3b8283a43e40).
## How To Use
We provide a script to unzip the images from tar files to subfolders in `./images`:
```python
import os
import subprocess
from tqdm import tqdm
import multiprocessing
from functools import partial
source_tar_dir = "tars"
target_image_dir = "images"
sub_dirs = ['vqa', 'edit', 't2i/Anyword', 't2i/Blip3o', 't2i/Flux', 't2i/JourneyDB', 't2i/Laion']
tar_bases = [os.path.join(source_tar_dir, sub_dir) for sub_dir in sub_dirs]
image_bases = [os.path.join(target_image_dir, sub_dir) for sub_dir in sub_dirs]
for img_dir in image_bases:
os.makedirs(img_dir, exist_ok=True)
def unpack_tar(tar_path, dest_dir):
cmd = [
"tar",
"xf",
tar_path,
"-C", dest_dir
]
subprocess.run(cmd, check=True, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
return os.path.join(dest_dir, os.path.basename(tar_path).replace('.tar', ''))
all_tar_files = []
for tar_base, img_base in zip(tar_bases, image_bases):
files = [f for f in os.listdir(tar_base) if f.endswith('.tar')]
all_tar_files.extend([(os.path.join(tar_base, f), img_base) for f in files])
def process_tar(args):
return unpack_tar(args[0], args[1])
num_processes = min(50, multiprocessing.cpu_count())
with multiprocessing.Pool() as pool:
results = []
with tqdm(total=len(all_tar_files), desc="Unpacking TAR files") as pbar:
for res in pool.imap_unordered(process_tar, all_tar_files):
pbar.update(1)
results.append(res)
print(f"\nAll TAR files unpacked to: {target_image_dir}")
print(f"Total unpacked folders: {len(results)}")
```
Furthermore, you can verify file correctness using the following code and inject your absolute path into the annotations:
```python
import os
import random
import json
from tqdm import tqdm
def read_jsonl(file_path, num_samples=None):
print(f"reading from {file_path}")
data_list = []
samples = 0
with open(file_path, 'r', encoding='utf-8') as file:
for line in tqdm(file):
data = json.loads(line.strip())
data_list.append(data)
samples += 1
if num_samples is not None and samples >= num_samples:
break
print(f"read {len(data_list)} samples")
return data_list
def save_jsonl(data, file_path):
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
print(f'saving to {file_path}')
with open(file_path, 'w', encoding='utf-8') as file:
for item in tqdm(data, desc='Saving', total=len(data)):
json.dump(item, file, ensure_ascii=False)
file.write('\n')
print(f'saved {len(data)} samples')
# path to the images directory
images_path = "path_to_your_data/images"
# path to annotations
input_jsonl = 'stage_level_annotations/editing_decoder_0.85M.jsonl'
output_jsonl = 'stage_level_annotations/editing_decoder_0.85M_abs_path.jsonl'
preview_jsonl = 'previews/editing_decoder_0.85M_abs_path_preview1k.jsonl'
datas = read_jsonl(input_jsonl)
for data in tqdm(datas):
if 'images' in data:
images = [os.path.join(images_path, image) for image in data['images']]
data['images'] = images
save_jsonl(datas, output_jsonl)
random.shuffle(datas)
preview_set = datas[:1000]
for data in preview_set:
if 'images' in data:
for image in images:
assert os.path.exists(image), f"Image path {image} does not exist"
save_jsonl(preview_set, preview_jsonl)
```
### Citation
```
@misc{zhang2025nexusgenunifiedimageunderstanding,
title={Nexus-Gen: Unified Image Understanding, Generation, and Editing via Prefilled Autoregression in Shared Embedding Space},
author={Hong Zhang and Zhongjie Duan and Xingjun Wang and Yuze Zhao and Weiyi Lu and Zhipeng Di and Yixuan Xu and Yingda Chen and Yu Zhang},
year={2025},
eprint={2504.21356},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.21356},
}
```
# Nexus-Gen 训练数据集
## 引言
本数据集为[Nexus-Gen](https://www.modelscope.cn/models/DiffSynth-Studio/Nexus-GenV2)提供完整训练数据,涵盖图像理解、生成与编辑三类任务。如需了解Nexus-Gen的训练细节,请参阅其[技术报告](https://arxiv.org/abs/2504.21356)及[GitHub仓库](https://github.com/modelscope/Nexus-Gen)。
所有标注均统一为**标准消息格式(standard messages format)**,存储于JSONL文件中。单条标注示例包含以下字段:
* `images`:图像相对路径列表,例如`["t2i/Flux/000055/000055_495587.png"]`
* `messages`:用于训练大语言模型(Large Language Model,LLM)的对话消息,例如:
json
[
{"role": "user", "content": "请根据以下描述生成图像:一只拥有浅棕色皮毛的可爱卡通小鼠直立站在后腿上。"},
{"role": "assistant", "content": "以下是基于该描述生成的图像:<image>"}
]
* `id`:唯一数据标识符,例如`"EliGen_495587"`
* `source`:样本来源,例如`"EliGen"`
本数据集总规模为2630万条样本,数据分布如下:

为便于模型训练与开源使用,我们进一步将标注划分为**阶段级标注**与**任务级标注**。由于标注文件体积较大,更多样本标注示例请查看`./previews`目录。
### 阶段级标注
1. `autoregressive_model_pretraining_26.3M.jsonl`:包含全部2630万条训练样本,用于自回归模型的预训练。
2. `autoregressive_model_aes_finetuning_4.3M.jsonl`:该子集用于自回归模型的质量微调。其中图像生成样本限定为高质量子集,图像编辑样本主要源自ImagePulse子集。
3. `generation_decoder_1.7M.jsonl`:用于训练Nexus-Gen生成解码器的子集,仅包含高质量图像生成样本。
4. `editing_decoder_0.85M.jsonl`:用于训练Nexus-Gen编辑解码器的子集,全部数据均源自ImagePulse图像编辑数据集。
### 任务级标注
1. `image_understanding_5.8M.jsonl`:该任务采用多模态输入(图像-文本对)与纯文本输出,可直接反映模型的对话与理解能力。尽管多模态大语言模型(Multimodal Large Language Model,MLLM)天生具备此类跨模态推理能力,但该任务在训练中仍至关重要,可防止模型能力退化。我们采用[Cambrian-7M](https://huggingface.co/datasets/nyu-visionx/Cambrian-10M)作为数据源,该数据集涵盖光学字符识别、通用视觉问答、语言、计数、代码、数学与科学任务等多个领域。为提升数据质量,我们使用Qwen2.5-VL-72B对所有样本的答案进行了重新标注。
2. `image_generation_13.3M.jsonl`:该任务的输入为文本描述,输出为图像。我们的数据源包括[Journey DB](https://huggingface.co/datasets/JourneyDB/JourneyDB)、[AnyWord](https://modelscope.cn/datasets/iic/AnyWord-3M/summary)、[Laion-High-Resolution](https://huggingface.co/datasets/laion/laion-high-resolution)、[EliGen TrainSet](https://modelscope.cn/datasets/DiffSynth-Studio/EliGenTrainSet)、[FLUX-Aes](https://huggingface.co/datasets/gogoduan/flux_laion_aes)、[FLUX-T2I](https://huggingface.co/datasets/jackyhate/text-to-image-2M)以及[Blip3o-60K](https://huggingface.co/datasets/BLIP3o/BLIP3o-60k)。为增强标注多样性,我们采用Qwen2.5-VL-72B实现双标注范式,为每张图像生成简洁标题与详细描述。训练过程中,我们按分层比例随机采样这些标注(20%简洁标题 vs 80%详细描述),以平衡简洁性与上下文细节丰富度。
3. `image_editing_6.3M.jsonl`:该编辑任务的输入为图像及其对应的编辑指令,输出为编辑后的图像。我们的数据源包括[HQ-Edit](https://huggingface.co/datasets/UCSC-VLAA/HQ-Edit)、[UltraEdit](https://huggingface.co/datasets/BleachNick/UltraEdit)、[OmniEdit](https://huggingface.co/datasets/TIGER-Lab/OmniEdit-Filtered-1.2M)、[StyleBooth](https://ali-vilab.github.io/stylebooth-page/)以及[ImagePulse](https://modelscope.cn/collections/ImagePulse----tulvmaidong-7c3b8283a43e40)。
## 使用方法
我们提供了一段脚本,用于将tar压缩包中的图像解压至`./images`目录下的子文件夹中:
python
import os
import subprocess
from tqdm import tqdm
import multiprocessing
from functools import partial
source_tar_dir = "tars"
target_image_dir = "images"
sub_dirs = ['vqa', 'edit', 't2i/Anyword', 't2i/Blip3o', 't2i/Flux', 't2i/JourneyDB', 't2i/Laion']
tar_bases = [os.path.join(source_tar_dir, sub_dir) for sub_dir in sub_dirs]
image_bases = [os.path.join(target_image_dir, sub_dir) for sub_dir in sub_dirs]
for img_dir in image_bases:
os.makedirs(img_dir, exist_ok=True)
def unpack_tar(tar_path, dest_dir):
cmd = [
"tar",
"xf",
tar_path,
"-C", dest_dir
]
subprocess.run(cmd, check=True, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
return os.path.join(dest_dir, os.path.basename(tar_path).replace('.tar', ''))
all_tar_files = []
for tar_base, img_base in zip(tar_bases, image_bases):
files = [f for f in os.listdir(tar_base) if f.endswith('.tar')]
all_tar_files.extend([(os.path.join(tar_base, f), img_base) for f in files])
def process_tar(args):
return unpack_tar(args[0], args[1])
num_processes = min(50, multiprocessing.cpu_count())
with multiprocessing.Pool() as pool:
results = []
with tqdm(total=len(all_tar_files), desc="Unpacking TAR files") as pbar:
for res in pool.imap_unordered(process_tar, all_tar_files):
pbar.update(1)
results.append(res)
print(f"
All TAR files unpacked to: {target_image_dir}")
print(f"Total unpacked folders: {len(results)}")
此外,你可以使用以下代码验证文件正确性,并将图像路径替换为本地绝对路径以注入标注文件中:
python
import os
import random
import json
from tqdm import tqdm
def read_jsonl(file_path, num_samples=None):
print(f"reading from {file_path}")
data_list = []
samples = 0
with open(file_path, 'r', encoding='utf-8') as file:
for line in tqdm(file):
data = json.loads(line.strip())
data_list.append(data)
samples += 1
if num_samples is not None and samples >= num_samples:
break
print(f"read {len(data_list)} samples")
return data_list
def save_jsonl(data, file_path):
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
print(f'saving to {file_path}')
with open(file_path, 'w', encoding='utf-8') as file:
for item in tqdm(data, desc='Saving', total=len(data)):
json.dump(item, file, ensure_ascii=False)
file.write('
')
print(f'saved {len(data)} samples')
# path to the images directory
images_path = "path_to_your_data/images"
# path to annotations
input_jsonl = 'stage_level_annotations/editing_decoder_0.85M.jsonl'
output_jsonl = 'stage_level_annotations/editing_decoder_0.85M_abs_path.jsonl'
preview_jsonl = 'previews/editing_decoder_0.85M_abs_path_preview1k.jsonl'
datas = read_jsonl(input_jsonl)
for data in tqdm(datas):
if 'images' in data:
images = [os.path.join(images_path, image) for image in data['images']]
data['images'] = images
save_jsonl(datas, output_jsonl)
random.shuffle(datas)
preview_set = datas[:1000]
for data in preview_set:
if 'images' in data:
for image in images:
assert os.path.exists(image), f"Image path {image} does not exist"
save_jsonl(preview_set, preview_jsonl)
## 引用
bibtex
@misc{zhang2025nexusgenunifiedimageunderstanding,
title={Nexus-Gen: Unified Image Understanding, Generation, and Editing via Prefilled Autoregression in Shared Embedding Space},
author={Hong Zhang and Zhongjie Duan and Xingjun Wang and Yuze Zhao and Weiyi Lu and Zhipeng Di and Yixuan Xu and Yingda Chen and Yu Zhang},
year={2025},
eprint={2504.21356},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.21356},
}
提供机构:
maas
创建时间:
2025-07-17
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于训练Nexus-Gen模型的完整训练数据,涵盖图像理解、生成和编辑三大任务。它包含2630万个样本,所有标注均以标准消息格式统一存储在JSONL文件中。
以上内容由遇见数据集搜集并总结生成


