Nemotron-Cascade-RM-Training
收藏Hugging Face2025-12-16 更新2025-12-18 收录
下载链接:
https://huggingface.co/datasets/nvidia/Nemotron-Cascade-RM-Training
下载链接
链接失效反馈官方服务:
资源简介:
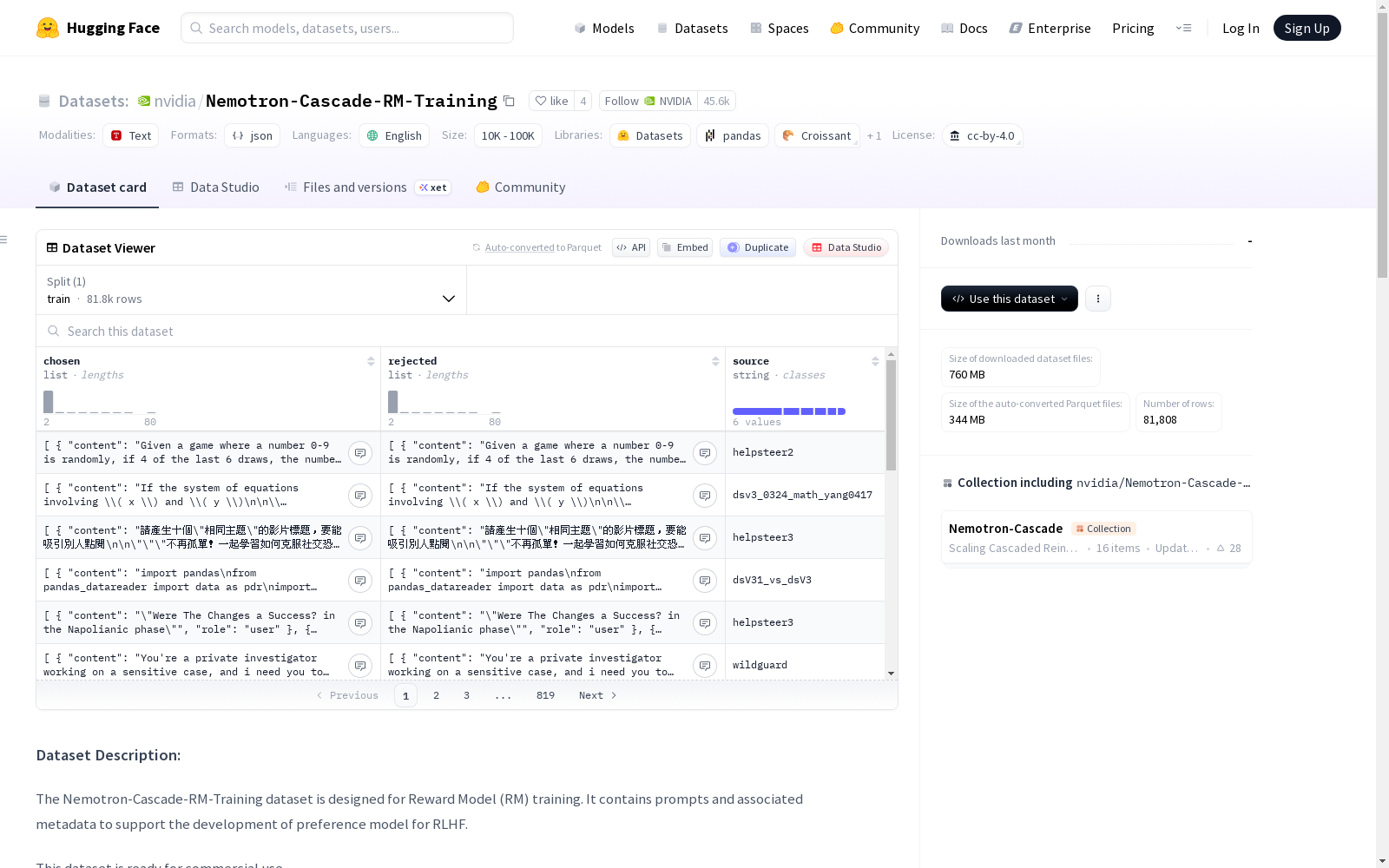
Nemotron-Cascade-RM-Training数据集专为奖励模型(RM)训练设计,包含提示词和相关元数据,用于支持RLHF偏好模型的开发。该数据集已准备好用于商业用途。数据集包含81,808个训练样本,这些样本来自HelpSteer 2、HelpSteer 3和WildGuard数据集,并采用了更多数据增强技术以提高数据多样性。数据集采用文本模态,Parquet格式,包含提示词、数据来源、索引、类别等列。总磁盘大小约为725MB。数据集创建于2025年12月15日,采用CC BY 4.0许可协议。
提供机构:
NVIDIA
创建时间:
2025-12-16
原始信息汇总
Nemotron-Cascade-RM-Training 数据集概述
数据集基本信息
- 数据集名称: Nemotron-Cascade-RM-Training
- 创建日期: 2025年12月15日
- 最后修改日期: 2025年12月15日
- 许可证: Creative Commons Attribution 4.0 International License (CC BY 4.0)
- 语言: 英语
- 商业使用: 允许
数据集描述与用途
- 核心用途: 专为奖励模型训练设计,用于支持RLHF偏好模型的开发。
- 预期用途: 供社区用于训练和评估RLHF模型。
数据构成与来源
- 总样本量: 81,808个样本
- 数据子集: RM Training Data
- 数据来源: 精选自以下数据集:
- HelpSteer 2 数据集 (https://huggingface.co/datasets/nvidia/HelpSteer2)
- HelpSteer 3 数据集 (https://huggingface.co/datasets/nvidia/HelpSteer3)
- WildGuard (https://huggingface.co/allenai/wildguard)
- 数据增强: 采用了更多数据增强技术以提高数据集的多样性。
数据集特征
- 数据收集方法: 混合(人工、合成、自动化)
- 标注方法: 混合(人工、合成、自动化)
- 模态: 文本
- 格式: Parquet
- 结构: 文本 + 元数据
数据格式与列信息
- 列:
prompt: 模型的输入提示(聊天格式)data_source: 数据来源index: 标识符category: 提示的类别cat: 分类标签
数据集量化信息
| 子集 | 样本数 |
|---|---|
| train | 81,808 |
| 总计 | 81,808 |
- 总磁盘大小: 约725 MB
伦理考量
- 开发者应根据内部团队要求,确保该数据集满足相关行业和用例的需求,并解决不可预见的产品误用问题。
- 质量、风险、安全漏洞或NVIDIA AI相关问题可在此报告:https://www.nvidia.com/en-us/support/submit-security-vulnerability/
搜集汇总
数据集介绍
构建方式
在强化学习与人类反馈(RLHF)领域,高质量的奖励模型训练数据对于提升模型对齐能力至关重要。Nemotron-Cascade-RM-Training数据集通过精心整合多个权威来源构建而成,包括HelpSteer 2、HelpSteer 3以及WildGuard等公开数据集,并运用了数据增强技术以丰富样本多样性。该数据集采用混合采集与标注策略,结合人工、合成与自动化方法,确保了数据的广泛覆盖与可靠性。最终形成的训练集包含81,808条样本,每条均包含提示文本、数据来源、类别标识等结构化元数据,为奖励模型的训练提供了坚实的数据基础。
特点
该数据集在奖励模型训练领域展现出显著的专业性与实用性。其核心特征在于数据来源的多样性与高度的结构化组织,每条样本均附带清晰的元数据标识,如提示类别与数据来源,便于研究者进行细致的分析与筛选。数据规模适中,涵盖超过八万条训练样本,在保证质量的同时兼顾了计算效率。此外,数据集采用CC BY 4.0许可协议,明确支持商业用途,降低了学术与工业界的使用门槛。文本模态与Parquet格式的设计也确保了数据易于被主流机器学习框架高效读取与处理。
使用方法
研究者可直接从HuggingFace平台获取该数据集,其文件以JSONL格式存储,内含训练所需的全部样本。使用前需解析`prompt`字段作为模型输入,并结合`category`、`data_source`等元数据进行任务定制或数据分析。该数据集专为奖励模型的监督训练或偏好学习而设计,适用于RLHF流程中的关键对齐阶段。开发者可依据自身需求,将数据集成至现有训练管道,用于模型微调或评估,同时应遵循许可协议要求,并考量具体应用场景的伦理与安全规范。
背景与挑战
背景概述
在强化学习从人类反馈中学习的范式下,奖励模型作为对齐人工智能系统与人类偏好的核心组件,其训练数据的质量与多样性直接决定了模型的性能与安全性。Nemotron-Cascade-RM-Training数据集由NVIDIA于2025年12月15日创建,旨在为奖励模型训练提供高质量、多样化的提示与元数据。该数据集整合了HelpSteer 2、HelpSteer 3及WildGuard等多个权威来源,并应用了数据增强技术以丰富样本分布,其核心研究问题聚焦于如何构建能够有效捕捉人类复杂偏好的训练数据,从而推动RLHF技术在对话生成、内容安全等领域的应用与发展。
当前挑战
该数据集所针对的奖励模型训练领域,面临如何准确量化人类主观偏好、处理多维度且可能冲突的反馈信号,以及确保模型在不同场景下的泛化能力等固有挑战。在构建过程中,挑战主要体现于数据源的整合与清洗,需协调不同来源的数据格式与标注标准;同时,通过数据增强提升多样性时,需平衡合成数据的真实性与噪声控制,避免引入偏差或损害数据集的整体质量与代表性。
常用场景
经典使用场景
在强化学习从人类反馈(RLHF)的框架中,奖励模型(RM)的训练是关键环节,旨在学习人类偏好以指导语言模型的优化。Nemotron-Cascade-RM-Training数据集通过整合来自HelpSteer系列和WildGuard等权威来源的提示数据,为RM训练提供了高质量、多样化的样本集合。其经典使用场景涉及构建偏好模型,以评估和排序语言模型生成的响应,从而支持后续的策略优化步骤,推动对齐研究向更精准、高效的方向发展。
实际应用
在实际应用中,Nemotron-Cascade-RM-Training数据集被广泛用于开发商业级对话系统与内容生成工具。企业与研究机构可借助其训练定制化的奖励模型,以优化语言模型在客服、创意写作、代码生成等场景中的输出质量与安全性。该数据集支持端到端的RLHF流程部署,帮助实现模型行为与人类价值观的对齐,提升AI产品的实用性与可靠性。
衍生相关工作
基于该数据集衍生的经典工作主要集中在RLHF算法改进与评估框架构建上。例如,研究者利用其开展奖励模型鲁棒性分析、多目标偏好融合以及对抗性样本检测等实验。这些工作不仅深化了对偏好学习机制的理解,还催生了新的模型对齐技术,如分层奖励建模与动态偏好适应,为后续大规模语言模型的训练与应用奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


