有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
file)及其转录文本(text),以及说话者信息和章节信息。file: 音频文件名,格式为.flac。audio: 包含音频文件名、解码后的音频数组和采样率。text: 音频文件的转录文本。id: 数据样本的唯一ID。speaker_id: 说话者的唯一ID。chapter_id: 包含转录的音频书章节的ID。datasets库可以加载和预处理数据集。数据集可以通过load_dataset函数下载并准备到本地驱动器。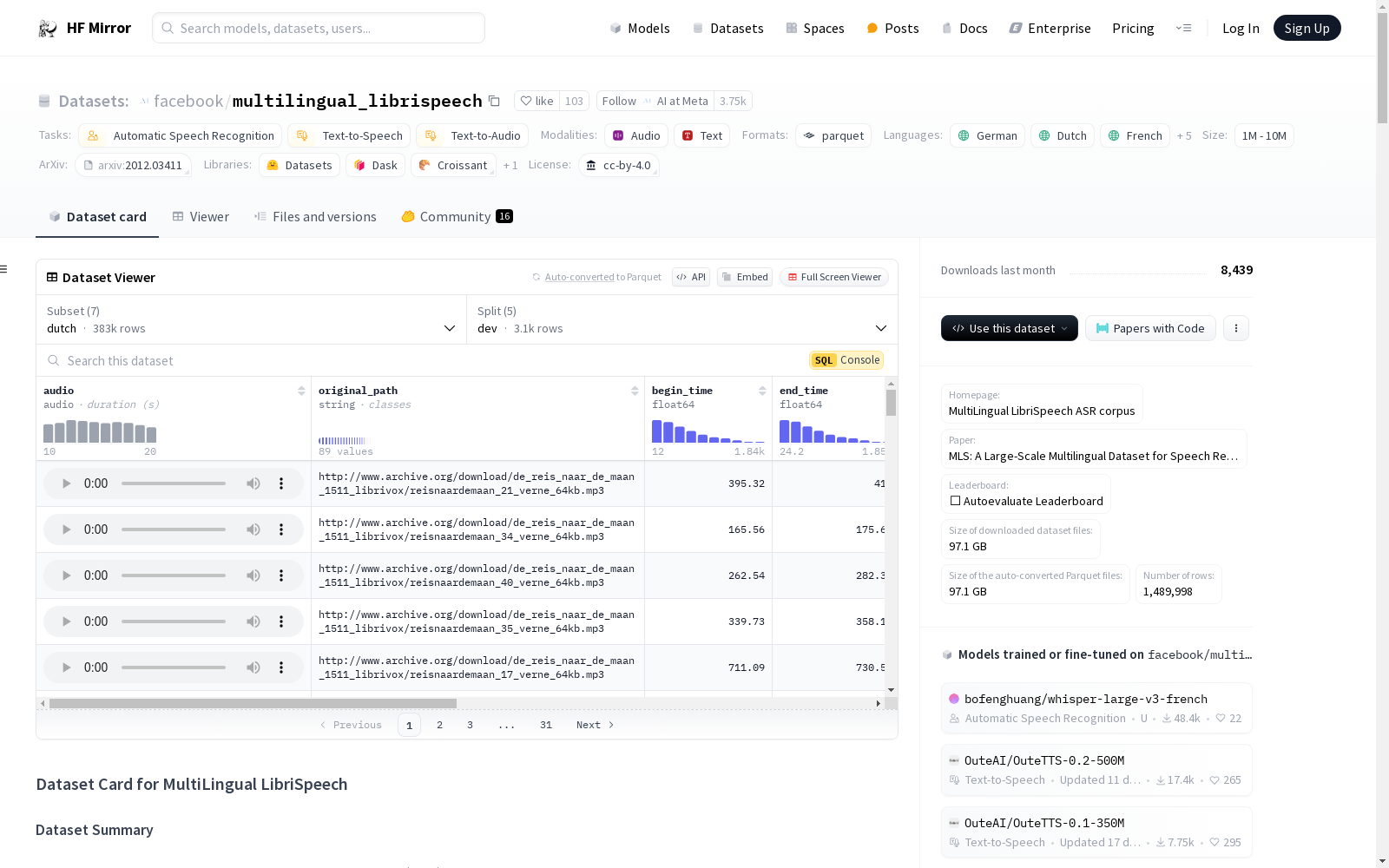
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
FEVER
FEVER(Fact Extraction and VERification)数据集是一个用于事实验证任务的数据集,包含超过185,000个标注的声明,这些声明需要从维基百科中提取证据进行验证。数据集的目标是帮助开发和评估自动事实验证系统。
fever.ai 收录
AISHELL/AISHELL-1
Aishell是一个开源的中文普通话语音语料库,由北京壳壳科技有限公司发布。数据集包含了来自中国不同口音地区的400人的录音,录音在安静的室内环境中使用高保真麦克风进行,并下采样至16kHz。通过专业的语音标注和严格的质量检查,手动转录的准确率超过95%。该数据集免费供学术使用,旨在为语音识别领域的新研究人员提供适量的数据。
hugging_face 收录
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录
LinkedIn Salary Insights Dataset
LinkedIn Salary Insights Dataset 提供了全球范围内的薪资数据,包括不同职位、行业、地理位置和经验水平的薪资信息。该数据集旨在帮助用户了解薪资趋势和市场行情,支持职业规划和薪资谈判。
www.linkedin.com 收录