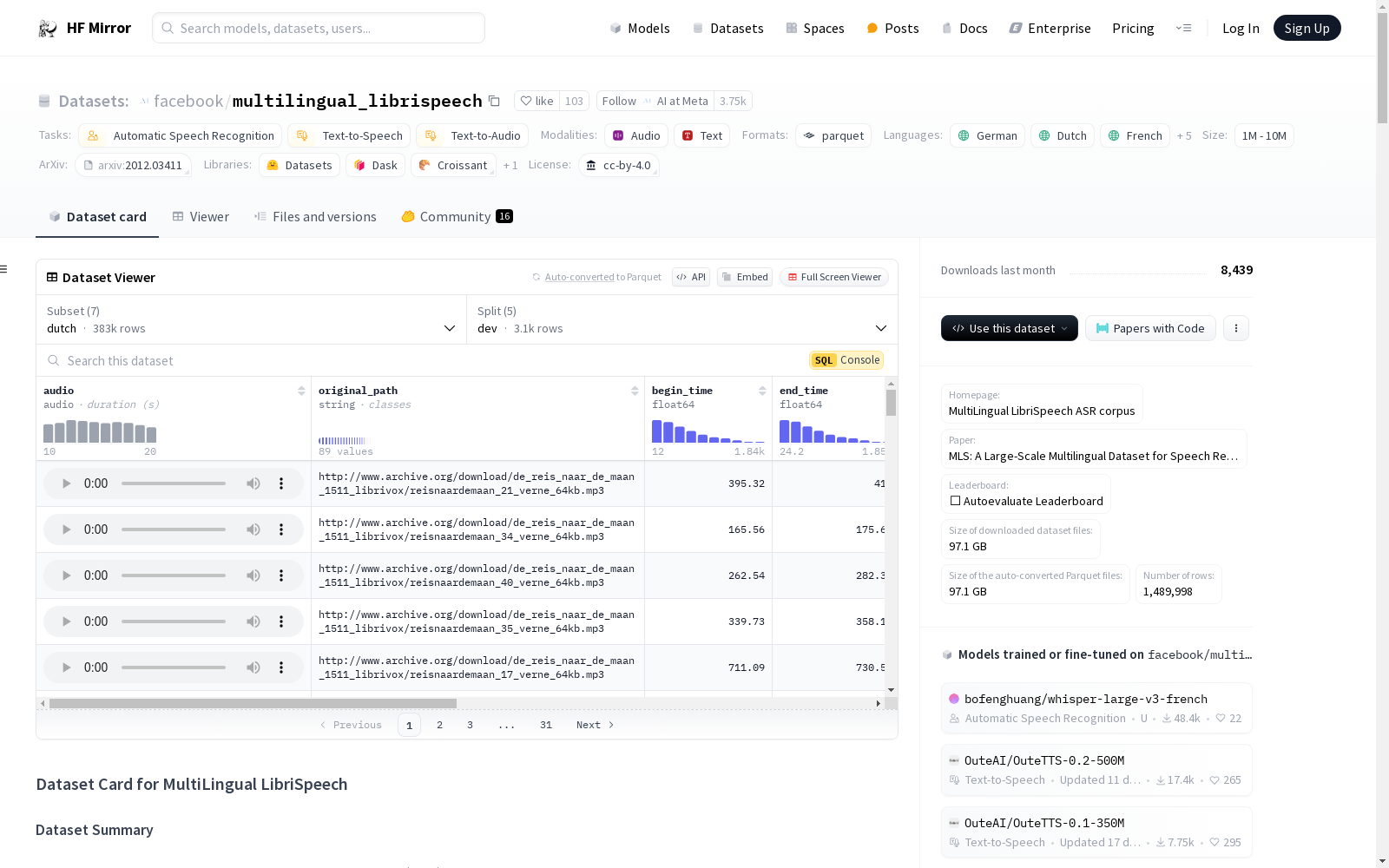
facebook/multilingual_librispeech
收藏Hugging Face2024-06-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/facebook/multilingual_librispeech
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: MultiLingual LibriSpeech
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
- expert-generated
language:
- de
- nl
- fr
- it
- es
- pt
- pl
license:
- cc-by-4.0
multilinguality:
- multilingual
paperswithcode_id: multilingual-librispeech
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
---
# Dataset Card for MultiLingual LibriSpeech
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [How to use](#how-to-use)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [MultiLingual LibriSpeech ASR corpus](http://www.openslr.org/94)
- **Repository:** [Needs More Information]
- **Paper:** [MLS: A Large-Scale Multilingual Dataset for Speech Research](https://arxiv.org/abs/2012.03411)
- **Leaderboard:** [🤗 Autoevaluate Leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=facebook%2Fmultilingual_librispeech&only_verified=0&task=automatic-speech-recognition&config=-unspecified-&split=-unspecified-&metric=wer)
### Dataset Summary
This is a streamable version of the Multilingual LibriSpeech (MLS) dataset.
The data archives were restructured from the original ones from [OpenSLR](http://www.openslr.org/94) to make it easier to stream.
MLS dataset is a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of
8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish.
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`, `speaker-identification`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active leaderboard which can be found at https://paperswithcode.com/dataset/multilingual-librispeech and ranks models based on their WER.
### Languages
The dataset is derived from read audiobooks from LibriVox and consists of 8 languages - English, German, Dutch, Spanish, French, Italian, Portuguese, Polish
### How to use
The `datasets` library allows you to load and pre-process your dataset in pure Python, at scale. The dataset can be downloaded and prepared in one call to your local drive by using the `load_dataset` function.
For example, to download the German config, simply specify the corresponding language config name (i.e., "german" for German):
```python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
```
Using the datasets library, you can also stream the dataset on-the-fly by adding a `streaming=True` argument to the `load_dataset` function call. Loading a dataset in streaming mode loads individual samples of the dataset at a time, rather than downloading the entire dataset to disk.
```python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
print(next(iter(mls)))
```
*Bonus*: create a [PyTorch dataloader](https://huggingface.co/docs/datasets/use_with_pytorch) directly with your own datasets (local/streamed).
Local:
```python
from datasets import load_dataset
from torch.utils.data.sampler import BatchSampler, RandomSampler
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
batch_sampler = BatchSampler(RandomSampler(mls), batch_size=32, drop_last=False)
dataloader = DataLoader(mls, batch_sampler=batch_sampler)
```
Streaming:
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
dataloader = DataLoader(mls, batch_size=32)
```
To find out more about loading and preparing audio datasets, head over to [hf.co/blog/audio-datasets](https://huggingface.co/blog/audio-datasets).
### Example scripts
Train your own CTC or Seq2Seq Automatic Speech Recognition models on MultiLingual Librispeech with `transformers` - [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition).
## Dataset Structure
### Data Instances
A typical data point comprises the path to the audio file, usually called `file` and its transcription, called `text`. Some additional information about the speaker and the passage which contains the transcription is provided.
```
{'file': '10900_6473_000030.flac',
'audio': {'path': '10900_6473_000030.flac',
'array': array([-1.52587891e-04, 6.10351562e-05, 0.00000000e+00, ...,
4.27246094e-04, 5.49316406e-04, 4.57763672e-04]),
'sampling_rate': 16000},
'text': 'więc czego chcecie odemnie spytałem wysłuchawszy tego zadziwiającego opowiadania broń nas stary człowieku broń zakrzyknęli równocześnie obaj posłowie\n',
'speaker_id': 10900,
'chapter_id': 6473,
'id': '10900_6473_000030'}
```
### Data Fields
- file: A filename .flac format.
- audio: A dictionary containing the audio filename, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- text: the transcription of the audio file.
- id: unique id of the data sample.
- speaker_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
- chapter_id: id of the audiobook chapter which includes the transcription.
### Data Splits
| | Train | Train.9h | Train.1h | Dev | Test |
| ----- | ------ | ----- | ---- | ---- | ---- |
| german | 469942 | 2194 | 241 | 3469 | 3394 |
| dutch | 374287 | 2153 | 234 | 3095 | 3075 |
| french | 258213 | 2167 | 241 | 2416 | 2426 |
| spanish | 220701 | 2110 | 233 | 2408 | 2385 |
| italian | 59623 | 2173 | 240 | 1248 | 1262 |
| portuguese | 37533 | 2116 | 236 | 826 | 871 |
| polish | 25043 | 2173 | 238 | 512 | 520 |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
Public Domain, Creative Commons Attribution 4.0 International Public License ([CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode))
### Citation Information
```
@article{Pratap2020MLSAL,
title={MLS: A Large-Scale Multilingual Dataset for Speech Research},
author={Vineel Pratap and Qiantong Xu and Anuroop Sriram and Gabriel Synnaeve and Ronan Collobert},
journal={ArXiv},
year={2020},
volume={abs/2012.03411}
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten)
and [@polinaeterna](https://github.com/polinaeterna) for adding this dataset.
---
pretty_name: 多语言利布里语音语料库(MultiLingual LibriSpeech)
annotations_creators:
- 专家生成
language_creators:
- 众包
- 专家生成
language:
- 德语(de)
- 荷兰语(nl)
- 法语(fr)
- 意大利语(it)
- 西班牙语(es)
- 葡萄牙语(pt)
- 波兰语(pl)
license:
- CC-BY-4.0(知识共享署名4.0国际许可协议)
multilinguality:
- 多语言
paperswithcode_id: multilingual-librispeech
size_categories:
- 100K<n<1M
source_datasets:
- 原始数据集
task_categories:
- 自动语音识别(automatic-speech-recognition)
---
# 多语言利布里语音语料库数据集卡片
## 目录
- [数据集概述](#dataset-description)
- [数据集总结](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [涉及语言](#languages)
- [使用方法](#how-to-use)
- [数据集结构](#dataset-structure)
- [数据样本格式](#data-instances)
- [数据字段说明](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建逻辑](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息说明](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差分析](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [致谢](#contributions)
## 数据集概述
- **主页**:[多语言利布里语音自动语音识别语料库](http://www.openslr.org/94)
- **仓库**:[信息待补充]
- **论文**:[《MLS:面向语音研究的大规模多语言数据集》](https://arxiv.org/abs/2012.03411)
- **排行榜**:[🤗 Autoevaluate 排行榜](https://huggingface.co/spaces/autoevaluate/leaderboards?dataset=facebook%2Fmultilingual_librispeech&only_verified=0&task=automatic-speech-recognition&config=-unspecified-&split=-unspecified-&metric=wer)
### 数据集总结
本数据集为多语言利布里语音(MLS)语料库的流式加载版本。数据归档源自[OpenSLR](http://www.openslr.org/94)的原始归档,并进行了结构重构以简化流式加载流程。MLS语料库是适用于语音研究的大规模多语言语料,其数据来源于LibriVox有声书平台上的朗读音频,涵盖8种语言:英语、德语、荷兰语、西班牙语、法语、意大利语、葡萄牙语、波兰语。
### 支持任务与排行榜
- `automatic-speech-recognition`(自动语音识别,ASR)、`speaker-identification`(说话人识别):本数据集可用于训练自动语音识别模型,模型接收音频文件并将其转录为书面文本,最常用的评估指标为词错误率(WER)。该任务设有公开排行榜,可在https://paperswithcode.com/dataset/multilingual-librispeech查阅,排行榜基于模型的词错误率对模型进行排名。
### 涉及语言
本数据集源自LibriVox有声书平台的朗读音频,涵盖8种语言:英语、德语、荷兰语、西班牙语、法语、意大利语、葡萄牙语、波兰语。
### 使用方法
使用`datasets`库可在纯Python环境中规模化加载与预处理数据集。通过调用`load_dataset`函数,可一次性将数据集下载并准备至本地磁盘。例如,下载德语配置的数据集,只需指定对应的语言配置名称(即德语对应的`"german"`):
python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
使用`datasets`库时,还可通过在`load_dataset`函数调用中添加`streaming=True`参数实现实时流式加载数据集。流式加载模式下,数据集将逐个加载样本,而非将完整数据集下载至本地磁盘:
python
from datasets import load_dataset
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
print(next(iter(mls)))
*额外提示*:可直接为自定义数据集(本地/流式)创建[PyTorch数据加载器](https://huggingface.co/docs/datasets/use_with_pytorch)。
本地加载示例:
python
from datasets import load_dataset
from torch.utils.data.sampler import BatchSampler, RandomSampler
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train")
batch_sampler = BatchSampler(RandomSampler(mls), batch_size=32, drop_last=False)
dataloader = DataLoader(mls, batch_sampler=batch_sampler)
流式加载示例:
python
from datasets import load_dataset
from torch.utils.data import DataLoader
mls = load_dataset("facebook/multilingual_librispeech", "german", split="train", streaming=True)
dataloader = DataLoader(mls, batch_size=32)
如需了解更多关于音频数据集加载与预处理的内容,请访问[hf.co/blog/audio-datasets](https://huggingface.co/blog/audio-datasets)。
### 示例脚本
可借助`transformers`库在多语言利布里语音语料库上训练自定义的CTC(连接主义时间分类)或Seq2Seq(序列到序列)自动语音识别模型——[详见此处](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition)。
## 数据集结构
### 数据样本格式
典型的数据点包含音频文件路径(字段名为`file`)及其转录文本(字段名为`text`),同时还会提供说话人与包含该转录文本的章节的相关信息。
{'file': '10900_6473_000030.flac',
'audio': {'path': '10900_6473_000030.flac',
'array': array([-1.52587891e-04, 6.10351562e-05, 0.00000000e+00, ...,
4.27246094e-04, 5.49316406e-04, 4.57763672e-04]),
'sampling_rate': 16000},
'text': 'więc czego chcecie odemnie spytałem wysłuchawszy tego zadziwiającego opowiadania broń nas stary człowieku broń zakrzyknęli równocześnie obaj posłowie
',
'speaker_id': 10900,
'chapter_id': 6473,
'id': '10900_6473_000030'}
### 数据字段说明
- `file`:FLAC格式的文件名。
- `audio`:包含音频文件名、解码后的音频数组与采样率的字典。请注意,当访问音频列时:`dataset[0]["audio"]`会自动对音频文件进行解码并重采样至`dataset.features["audio"].sampling_rate`指定的采样率。对大量音频文件进行解码与重采样可能耗时较长,因此建议优先通过样本索引访问音频列,即始终优先使用`dataset[0]["audio"]`而非`dataset["audio"][0]`。
- `text`:音频文件的转录文本。
- `id`:数据样本的唯一标识符。
- `speaker_id`:说话人的唯一标识符,同一说话人ID可对应多个数据样本。
- `chapter_id`:包含该转录文本的有声书章节ID。
### 数据划分
| | 训练总集 | 9小时训练子集 | 1小时训练子集 | 验证集 | 测试集 |
| ----- | ------ | ----- | ---- | ---- | ---- |
| 德语 | 469942 | 2194 | 241 | 3469 | 3394 |
| 荷兰语 | 374287 | 2153 | 234 | 3095 | 3075 |
| 法语 | 258213 | 2167 | 241 | 2416 | 2426 |
| 西班牙语 | 220701 | 2110 | 233 | 2408 | 2385 |
| 意大利语 | 59623 | 2173 | 240 | 1248 | 1262 |
| 葡萄牙语 | 37533 | 2116 | 236 | 826 | 871 |
| 波兰语 | 25043 | 2173 | 238 | 512 | 520 |
## 数据集构建
### 构建逻辑
[信息待补充]
### 源数据
#### 初始数据收集与标准化
[信息待补充]
#### 源语言内容生产者是谁?
[信息待补充]
### 标注信息
#### 标注流程
[信息待补充]
#### 标注人员是谁?
[信息待补充]
### 个人与敏感信息说明
本数据集由在线捐赠语音数据的民众构成。请同意不尝试通过本数据集推断说话人的身份。
## 数据集使用注意事项
### 数据集的社会影响
[更多信息待补充]
### 偏差分析
[更多信息待补充]
### 其他已知局限性
[信息待补充]
## 附加信息
### 数据集维护者
[信息待补充]
### 许可信息
公有领域,知识共享署名4.0国际公共许可协议([CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode))
### 引用信息
@article{Pratap2020MLSAL,
title={MLS: A Large-Scale Multilingual Dataset for Speech Research},
author={Vineel Pratap and Qiantong Xu and Anuroop Sriram and Gabriel Synnaeve and Ronan Collobert},
journal={ArXiv},
year={2020},
volume={abs/2012.03411}
}
### 致谢
感谢[@patrickvonplaten](https://github.com/patrickvonplaten)与[@polinaeterna](https://github.com/polinaeterna)贡献本数据集。
提供机构:
facebook
原始信息汇总
数据集概述
数据集名称
- 名称: MultiLingual LibriSpeech
- 别名: MLS
数据集描述
- 摘要: MultiLingual LibriSpeech (MLS) 是一个适用于语音研究的大型多语言语料库,源自LibriVox的朗读有声书,包含8种语言:英语、德语、荷兰语、西班牙语、法语、意大利语、葡萄牙语、波兰语。
- 语言: 德语、荷兰语、法语、意大利语、西班牙语、葡萄牙语、波兰语
- 许可证: CC-BY-4.0
- 多语言性: 多语言
- 大小: 100K<n<1M
- 源数据集: 原始数据
- 任务类别: 自动语音识别
数据集结构
- 数据实例: 每个数据点包含音频文件路径(
file)及其转录文本(text),以及说话者信息和章节信息。 - 数据字段:
file: 音频文件名,格式为.flac。audio: 包含音频文件名、解码后的音频数组和采样率。text: 音频文件的转录文本。id: 数据样本的唯一ID。speaker_id: 说话者的唯一ID。chapter_id: 包含转录的音频书章节的ID。
- 数据分割: 数据集被分割为训练集、开发集和测试集,不同语言的数据量有所不同。
使用方法
- 使用
datasets库可以加载和预处理数据集。数据集可以通过load_dataset函数下载并准备到本地驱动器。 - 示例代码展示了如何加载特定语言配置的数据集,并支持流式加载。
支持的任务和排行榜
- 任务: 自动语音识别、说话者识别
- 评估指标: 词错误率(WER)
- 排行榜: 可在Papers With Code查看,根据WER排名。
数据集创建
- 许可证信息: 遵循Creative Commons Attribution 4.0 International Public License (CC-BY-4.0)。
- 引用信息: 引用时请使用提供的文献信息。
- 贡献者: 感谢@patrickvonplaten和@polinaeterna的贡献。
搜集汇总
数据集介绍
构建方式
MultiLingual LibriSpeech数据集的构建基于LibriVox项目中的有声读物,涵盖了8种语言,包括英语、德语、荷兰语、西班牙语、法语、意大利语、葡萄牙语和波兰语。数据集的音频文件和对应的转录文本由专家生成,部分语言的转录工作通过众包完成。数据集的结构经过重新组织,以便于流式加载,同时保留了原始音频文件的详细信息,如音频时长、说话者ID和章节ID等。
使用方法
使用MultiLingual LibriSpeech数据集时,可以通过Hugging Face的`datasets`库进行加载和预处理。用户可以选择特定的语言配置(如德语、法语等),并通过`load_dataset`函数下载数据集。此外,数据集支持流式加载,用户可以在不下载整个数据集的情况下逐个加载样本。数据集还提供了与PyTorch的集成,用户可以直接创建PyTorch数据加载器,便于在深度学习模型中使用。
背景与挑战
背景概述
MultiLingual LibriSpeech(MLS)数据集是由Facebook AI研究院于2020年发布的一个大规模多语言语音数据集,旨在推动自动语音识别(ASR)和文本到语音(TTS)等领域的研究。该数据集源自LibriVox项目中的有声读物,涵盖了英语、德语、荷兰语、西班牙语、法语、意大利语、葡萄牙语和波兰语等8种语言,总计约6000小时的语音数据。MLS数据集的发布为多语言语音处理研究提供了丰富的资源,尤其在跨语言语音识别和多语言语音合成方面具有重要意义。
当前挑战
MLS数据集在构建过程中面临多重挑战。首先,多语言数据的整合与标注需要克服语言间的差异,确保数据质量的一致性。其次,数据集的规模庞大,处理和存储这些数据对计算资源提出了较高要求。此外,不同语言的语音特性各异,如何在模型训练中有效处理这些差异也是一个重要挑战。最后,数据集的使用需考虑隐私保护问题,确保不泄露说话者的个人信息。
常用场景
经典使用场景
MultiLingual LibriSpeech数据集的经典使用场景主要集中在自动语音识别(ASR)和文本到语音(TTS)任务上。该数据集包含多种语言的语音和对应的文本转录,适用于训练和评估多语言语音识别模型。通过使用该数据集,研究者可以开发出能够在多种语言环境下工作的语音识别系统,从而推动跨语言语音技术的进步。
解决学术问题
MultiLingual LibriSpeech数据集解决了多语言语音识别中的关键学术问题,如跨语言语音识别模型的训练和评估。该数据集通过提供多种语言的语音和文本对,使得研究者能够探索如何在不同语言之间共享和迁移语音识别知识,从而提高模型的泛化能力和鲁棒性。这对于推动多语言语音识别技术的发展具有重要意义。
实际应用
MultiLingual LibriSpeech数据集在实际应用中具有广泛的潜力,特别是在多语言语音识别和语音合成领域。例如,它可以用于开发支持多种语言的智能语音助手、语音翻译系统以及语音到文本的转录服务。这些应用不仅能够提升用户体验,还能在跨文化交流和全球市场中发挥重要作用。
数据集最近研究
最新研究方向
在多语言语音识别领域,facebook/multilingual_librispeech数据集的最新研究方向主要集中在提升跨语言语音识别的准确性和鲁棒性。该数据集涵盖了多种语言,为研究人员提供了丰富的资源,以探索如何在不同语言之间共享和迁移语音识别模型。前沿研究包括多语言模型的联合训练、跨语言知识迁移以及低资源语言的语音识别增强。这些研究不仅推动了语音识别技术的发展,还为全球范围内的语音技术应用提供了更广泛的支持,尤其是在资源有限的环境中。
以上内容由遇见数据集搜集并总结生成


