Movie Facts and Fibs (MF2)
收藏arXiv2025-06-07 更新2025-06-10 收录
下载链接:
https://huggingface.co/datasets/sardinelab/MF2
下载链接
链接失效反馈官方服务:
资源简介:
MF2数据集是一个用于评估模型对完整电影(时长50-170分钟)理解程度的新基准。该数据集包含超过50部完整长度的、开放许可的电影,每部电影都配有一套手动构建的声明对——一个真实的(事实)和一个看似合理但错误的(谎言),共计超过850对。这些声明针对电影中的核心叙事元素,如角色动机和情绪、因果链和事件顺序,并引用人们无需重看电影就能回忆起的重要时刻。与多项选择题格式不同,我们采用二元声明评估协议:对于每对声明,模型必须正确识别出真实和错误的声明。这减少了答案排序等偏差,并能够更精确地评估推理能力。我们的实验表明,无论是开放权重还是封闭的顶级模型,其性能都远低于人类,突显了人类在记忆和推理关键叙事信息方面的优越能力,这是当前视觉-语言模型所缺乏的。
The MF2 dataset is a novel benchmark for evaluating models' understanding of full-length feature films with durations ranging from 50 to 170 minutes. This dataset includes over 50 full-length, openly licensed films, each paired with a manually constructed statement pair: one factual (true) statement and one plausible but incorrect (false/lie) statement, totaling more than 850 pairs. These statements target core narrative elements in the films, such as character motivations and emotions, causal chains and event sequences, and reference key moments that viewers can recall without re-watching the films. In contrast to multiple-choice question formats, we adopt a binary statement evaluation protocol: for each pair of statements, the model must correctly identify which one is true and which one is false. This reduces biases such as answer ordering, and enables more precise evaluation of model reasoning capabilities. Our experiments show that both open-weight and closed-weight state-of-the-art models perform far worse than humans, highlighting the superior human ability to memorize and reason about key narrative information, which current vision-language models lack.
提供机构:
葡萄牙里斯本大学高级技术研究所, 葡萄牙电信研究所, 阿姆斯特丹大学ILLC, 阿姆斯特丹大学语言技术实验室, 西班牙国家研究委员会工业机器人与信息学研究所, 北卡罗来纳大学教堂山分校, 哥本哈根大学, 先锋人工智能中心, 赫瑞瓦特大学, 博尔赞-博尔扎诺自由大学, Unbabel, 阿姆斯特丹ELLIS单位, 里斯本ELLIS单位, 特伦托ELLIS单位, 巴塞罗那ELLIS单位
创建时间:
2025-06-07
原始信息汇总
数据集概述
基本信息
- 名称: sardinelab/MF2
- 许可证: CC BY-NC-SA 4.0
- 任务类别: 视觉问答 (Visual Question Answering)
- 语言: 英语 (en)
数据集特点
- 标签:
- 长电影理解 (Long Movie Understanding)
- 多模态 (Multimodal)
- 规模类别: 小于1K样本 (n<1K)
搜集汇总
数据集介绍
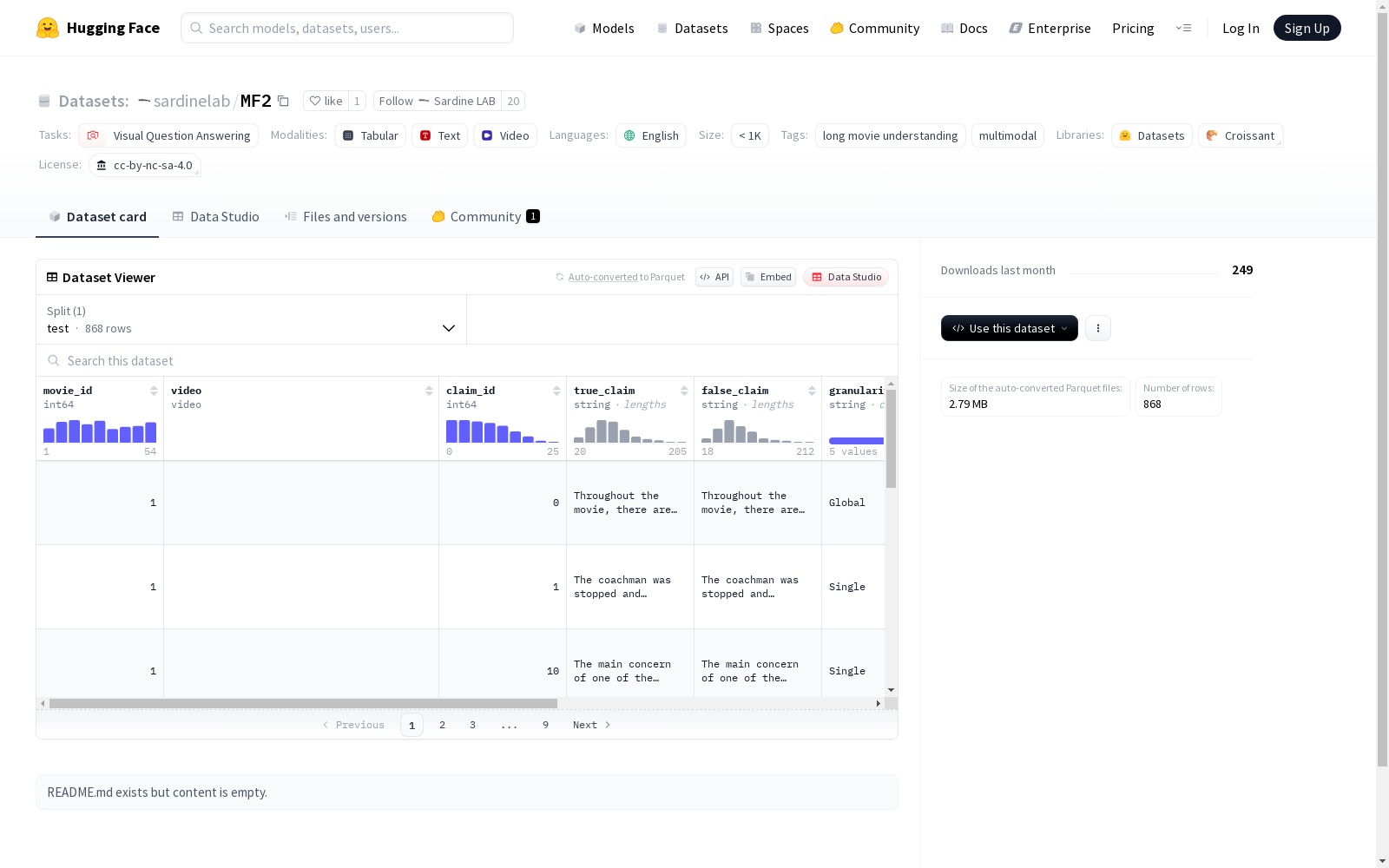
构建方式
Movie Facts and Fibs (MF2) 数据集的构建过程分为三个主要阶段:电影收集、数据标注和质量控制。首先,研究人员从互联网档案馆(Internet Archive)收集了53部开放许可的电影,这些电影的平均时长为88.33分钟,并配有字幕。随后,26名标注者观看了这些电影,手动构建了超过850对对比性声明对(claim pairs),每对声明包括一个真实陈述(fact)和一个看似合理但虚假的陈述(fib)。这些声明针对电影中的核心叙事元素,如角色动机、情感、因果关系和事件顺序。最后,通过人工评估和反馈机制,对声明对进行了质量控制,移除了104对低质量或模糊的声明对,确保了数据集的可靠性。
使用方法
MF2数据集的使用方法主要包括三个步骤:首先,模型接收电影的视频帧和字幕作为输入;其次,模型需要对每个声明对中的真实和虚假陈述进行二元分类;最后,通过对比模型的分类结果与人工标注的真实标签,评估模型的叙事理解能力。数据集支持多种输入模态(仅视频、仅字幕、视频加字幕等),并可扩展到其他模态如电影概要。评估指标包括配对准确率(pairwise accuracy)和标准准确率(standard accuracy),分别衡量模型对声明对的整体识别能力和单个声明的分类能力。
背景与挑战
背景概述
Movie Facts and Fibs (MF2) 数据集由Emmanouil Zaranis等研究人员于2025年创建,旨在评估视觉语言模型(VLMs)对长电影叙事理解的能力。该数据集包含53部开放授权的全长电影(时长50-170分钟),每部电影配有手动构建的真假声明对(共850对),聚焦于角色动机、情感、因果链等核心叙事元素。MF2的提出填补了现有视频理解基准的不足,特别是那些仅关注短片段或表面细节的数据集,为长视频理解领域提供了更严谨的评估框架。
当前挑战
MF2数据集面临的挑战主要包括两方面:1) 领域问题挑战:当前VLMs在长视频叙事理解上表现不佳,尤其在整合跨场景信息和全局推理方面远逊于人类,凸显了模型在记忆与推理长时序信息上的局限性;2) 构建过程挑战:数据标注需人工识别电影关键叙事点并设计最小差异的对比声明对,同时需平衡单场景、多场景和全局推理的粒度,且需避免版权问题(仅使用1920-1970年的低曝光电影)。此外,评估协议采用二元声明对判别,要求模型同时识别真假声明,增加了任务复杂度。
常用场景
经典使用场景
在电影叙事理解研究中,MF2数据集通过对比性声明对(fact-fib pairs)的设计,为评估模型对长视频内容的深层次理解能力提供了独特场景。该数据集要求模型区分真实叙事元素与看似合理但虚假的陈述,特别聚焦于角色动机、情感变化、因果链条等核心叙事维度,从而检验模型是否具备跨场景整合信息的能力。例如在电影《小公主》中,模型需判断'莎拉为父亲保留的怀表最终归还'与'怀表被女校长没收'的真伪,这种设置有效规避了传统多选题的排序偏差问题。
解决学术问题
MF2解决了当前视频理解领域三大关键问题:其一,突破'大海捞针'式检索评估的局限,通过人工构建的叙事中心问题检验抽象理解能力;其二,采用开放式授权电影规避版权导致的复现难题,53部全长电影平均时长88分钟,显著长于现有基准(如CinePile的2.67分钟);其三,创新性使用二元声明评估协议,相比多选题形式更能精准测量推理能力。实验表明,当前最优模型Gemini 2.5 Pro的成对准确率(60.6%)仍显著低于人类水平(90.5%),揭示了现有视觉语言模型在长程叙事理解上的本质缺陷。
实际应用
该数据集的实际价值体现在智能影视分析系统的开发中。在自动化剧本摘要场景,模型需像人类观众那样捕捉关键转折点(如《血色街道》中画家犯罪的心理变化);在教育领域,可构建基于电影情节的因果推理测试题;在流媒体平台,能实现细粒度内容标签生成(识别'全局型'主题如《相逢圣路易》中的家庭价值观)。特别值得注意的是,当结合字幕输入时,模型准确率提升12.4%(如InternVL3-72B从43.8%升至51.3%),证明多模态融合对实际应用的必要性。
数据集最近研究
最新研究方向
近年来,Movie Facts and Fibs (MF2) 数据集在长视频理解领域引起了广泛关注,特别是在评估视觉语言模型(VLMs)对电影叙事深度理解的能力方面。该数据集通过手动构建的真实与虚假声明对(fact-fib pairs),聚焦于角色动机、情感变化、因果链和事件顺序等核心叙事元素,为模型提供了更具挑战性的评估基准。前沿研究主要集中在如何提升模型在长视频中的全局推理能力、多场景信息整合能力以及情感理解能力。热点事件包括Gemini 2.5 Pro和GPT-4o等闭源模型与开源模型(如InternVL3、LLaVA-Video)的性能对比,揭示了当前模型与人类在叙事理解上的显著差距。MF2的推出不仅推动了长视频理解技术的发展,还为教育、影视分析等实际应用场景提供了重要的研究工具。
相关研究论文
- 1Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding葡萄牙里斯本大学高级技术研究所, 葡萄牙电信研究所, 阿姆斯特丹大学ILLC, 阿姆斯特丹大学语言技术实验室, 西班牙国家研究委员会工业机器人与信息学研究所, 北卡罗来纳大学教堂山分校, 哥本哈根大学, 先锋人工智能中心, 赫瑞瓦特大学, 博尔赞-博尔扎诺自由大学, Unbabel, 阿姆斯特丹ELLIS单位, 里斯本ELLIS单位, 特伦托ELLIS单位, 巴塞罗那ELLIS单位 · 2025年
以上内容由遇见数据集搜集并总结生成


