ultrachat-es-30k-topics
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/thinkPy/ultrachat-es-30k-topics
下载链接
链接失效反馈官方服务:
资源简介:
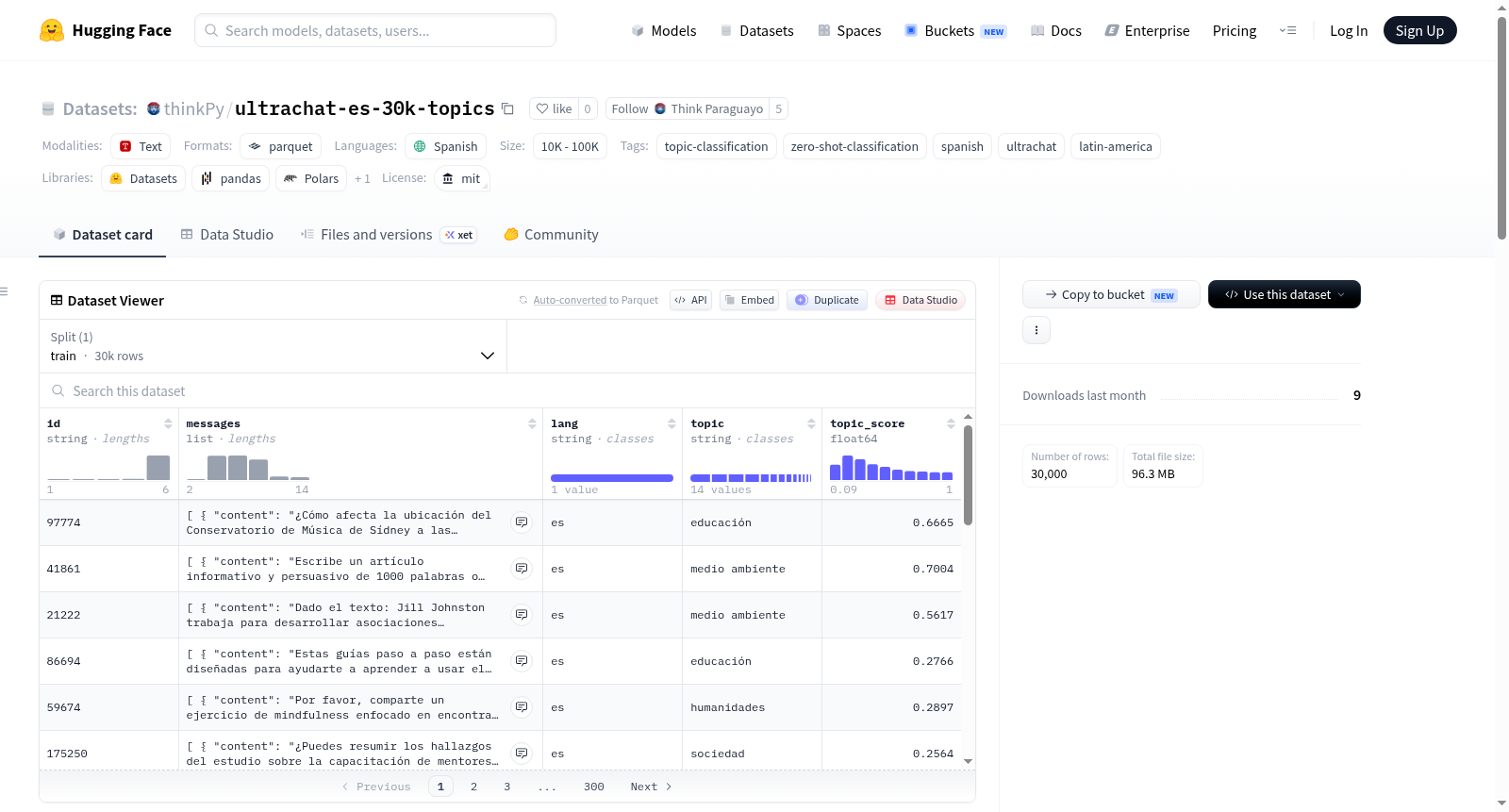
ultrachat-es-30k-topics 是一个包含 30,000 个西班牙语对话的数据集,每个对话都通过零样本分类方法自动标注了主题标签。该数据集源自 latam-gpt/es-ultrachat(后者是 HuggingFaceH4/ultrachat_200k 数据集的机器翻译版本,使用 Llama 3.1 70B 模型翻译成西班牙语)。本数据集从中随机采样了 30,000 个示例,并新增了两个关键字段:`topic`(主题)和 `topic_score`(主题分类置信度得分)。主题分类基于每个对话中用户的第一条消息(截断至 256 个字符),使用 MoritzLaurer/mDeBERTa-v3-base-mnli-xnli 模型进行零样本自然语言推理分类。涵盖的主题共 13 类,包括:技术、数学、科学、人文、历史、文化、政治、经济、健康、教育、社会、环境、娱乐。每个数据样本包含对话 ID、由用户和助手角色组成的消息列表、语言标识(es)、预测的主题以及对应的置信度分数。该数据集适用于西班牙语对话的主题分类模型训练、评估,或作为零样本/少样本学习任务的基准。需要注意的是,主题分类是自动生成的,可能存在错误;且原始内容源自英语,经翻译而来,对拉丁美洲文化的代表性有限。
ultrachat-es-30k-topics is a dataset containing 30,000 Spanish dialogues, each automatically annotated with topic labels using a zero-shot classification method. The dataset is derived from latam-gpt/es-ultrachat (which is a machine-translated version of the HuggingFaceH4/ultrachat_200k dataset, translated into Spanish using the Llama 3.1 70B model). This dataset randomly samples 30,000 examples from it and adds two key fields: `topic` (topic) and `topic_score` (topic classification confidence score). Topic classification is based on the users first message in each dialogue (truncated to 256 characters), using the MoritzLaurer/mDeBERTa-v3-base-mnli-xnli model for zero-shot natural language inference classification. It covers 13 topic categories, including: technology, mathematics, science, humanities, history, culture, politics, economics, health, education, society, environment, and entertainment. Each data sample includes a dialogue ID, a list of messages with user and assistant roles, a language identifier (es), a predicted topic, and the corresponding confidence score. The dataset is suitable for training and evaluating topic classification models for Spanish dialogues, or as a benchmark for zero-shot/few-shot learning tasks. It should be noted that the topic classification is automatically generated and may contain errors; moreover, the original content is from English and has been translated, with limited representation of Latin American culture.
创建时间:
2026-05-31
原始信息汇总
数据集概述
ultrachat-es-30k-topics 是一个包含 30,000 条西班牙语对话的子集,每条对话都经过自动主题分类标注。该数据集来源于 latam-gpt/es-ultrachat,后者是使用 Llama 3.1 70B 对 HuggingFaceH4/ultrachat_200k 进行自动翻译得到的西班牙语版本。
数据规模与划分
- 训练集:30,000 条示例
- 字节数:197,704,577
- 下载大小:96,263,022 字节
- 数据集总大小:197,704,577 字节
数据特征
每条数据包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
id |
string | 唯一标识符 |
messages |
list[dict] | 对话消息列表,每条消息包含 content(内容)和 role(角色) |
lang |
string | 语言(固定为 es) |
topic |
string | 自动分类的主题标签 |
topic_score |
float64 | 主题分类的置信度分数 |
主题分类
使用 MoritzLaurer/mDeBERTa-v3-base-mnli-xnli 模型,基于用户的第一条消息(截取前 256 个字符)进行零样本主题分类。
可用的 13 个主题
| 主题 | 描述 |
|---|---|
tecnología |
编程、软件、硬件、人工智能 |
matemática |
代数、统计学、微积分 |
ciencia |
物理、化学、生物、研究 |
humanidades |
哲学、语言学、文学 |
historia |
历史事件和历史人物 |
cultura |
传统、艺术、音乐、美食 |
política |
政府、国际关系 |
economía |
金融、市场、创业 |
salud |
医学、健康、营养 |
educación |
教育学、学习、学术 |
sociedad |
人际关系、伦理、日常生活 |
medio ambiente |
生态学、气候变化、自然 |
entretenimiento |
体育、电影、电子游戏、旅行 |
数据来源
原始数据为 latam-gpt/es-ultrachat 的随机样本(随机种子 seed=42),并额外添加了两列主题分类信息。
使用示例
python from datasets import load_dataset
ds = load_dataset("thinkPy/ultrachat-es-30k-topics", split="train")
按主题过滤
ds_cultura = ds.filter(lambda x: x["topic"] == "cultura")
按置信度过滤
ds_alta_confianza = ds.filter(lambda x: x["topic_score"] >= 0.5)
限制与注意事项
- 主题分类为自动完成,在文本模糊或过短的情况下可能存在错误。
- 内容源于英文翻译,对拉丁美洲文化的代表性有限。
- 对于
topic_score较低的示例应谨慎处理。
搜集汇总
数据集介绍
构建方式
ultrachat-es-30k-topics数据集源于latam-gpt/es-ultrachat,后者是通过Llama 3.1 70B模型将HuggingFaceH4/ultrachat_200k英语对话自动翻译为西班牙语而生成的。在此基础上,本数据集随机抽取30,000条样本(种子为42),并利用MoritzLaurer/mDeBERTa-v3-base-mnli-xnli模型对用户首条消息进行零样本分类(NLI),截断至256个字符后,自动标注所属主题及其置信度得分,最终形成兼具对话内容与主题标签的结构化数据。
特点
该数据集涵盖13个预设主题类别,包括技术、数学、科学、人文学科、历史、文化、政治、经济、健康、教育、社会、环境及娱乐,每个对话均关联一个主题标签及对应的置信度分数(topic_score)。所有对话语言为西班牙语,且采用与原始UltraChat一致的对话结构,包含用户与助手的多轮消息。数据以标准化JSON格式存储,便于直接加载与筛选,同时提供基于主题和置信度的高效过滤功能。
使用方法
使用Hugging Face的datasets库可轻松加载该数据集:ds = load_dataset('thinkPy/ultrachat-es-30k-topics', split='train')。随后,可通过filter方法按主题筛选对话(如ds.filter(lambda x: x['topic'] == 'cultura')),或基于置信度阈值过滤低质量样本(如ds.filter(lambda x: x['topic_score'] >= 0.5))。数据字段包括对话ID、消息列表、语言、主题及得分,适用于西班牙语主题分类、零样本学习评估及对话系统研究等场景。
背景与挑战
背景概述
自然语言处理领域中,多轮对话数据集的构建与主题分类任务密切相关,对于提升对话系统的领域适应性与语义理解能力具有关键作用。ultrachat-es-30k-topics数据集由thinkPy团队于2024年创建,源自latam-gpt/es-ultrachat,后者为HuggingFaceH4/ultrachat_200k的西班牙语机器翻译版本。该数据集选取3万条西班牙语对话样本,利用MoritzLaurer/mDeBERTa-v3-base-mnli-xnli模型进行零样本主题分类,涵盖技术、数学、科学、人文等13个主题,为西班牙语对话主题分类和零样本学习研究提供了标注资源,尤其适用于拉丁美洲语境下的多轮对话分析。
当前挑战
该数据集面临的核心挑战包括:首先,主题分类依赖自动标注而非人工校验,在语义模糊或短文本场景下易产生错误,影响下游任务可靠性;其次,数据源自英语对话的机器翻译,存在文化背景偏移问题,难以充分反映拉丁美洲本土的交流习惯与价值观;此外,部分样本的topic_score较低,如何有效筛选高置信度数据以提升模型鲁棒性仍是关键难点;构建过程中还需处理多语言零样本分类的泛化瓶颈,以及从大规模对话中高效提取主题标签的计算开销。
常用场景
经典使用场景
在西班牙语自然语言处理领域,该数据集可作为主题分类与零样本分类任务的基准测试集。其核心经典用法在于利用自动标注的13个主题标签,评估和微调针对西班牙语预训练语言模型的分类性能。研究者可基于用户首轮对话内容进行主题预测,并通过与内置的topic_score置信度分数对比,验证分类模型的鲁棒性与准确性。此外,该数据集也可用于多轮对话中的意图识别研究,借助对话上下文探索主题在交互过程中的动态演变规律。
衍生相关工作
该数据集的诞生直接源自对UltraChat大型对话数据集的多语言扩展与主题增强,其衍生工作已推动了两项重要研究方向。一方面,研究者基于此数据集构建了首个面向西班牙语的对话主题分类基线模型,例如利用mDeBERTa进行零样本学习和提示微调。另一方面,该数据集催生了针对拉丁美洲文化特殊性的主题适配研究,通过增补地域性标签或融合本地语料,提升了模型对文化多样性的包容能力。此外,其自动标注方法也被借鉴用于其他低资源语言的对话语料增强,促进了多语言对话系统领域的交叉创新。
数据集最近研究
最新研究方向
当前,针对低资源语言的多轮对话数据集构建成为自然语言处理领域的前沿热点,尤其是西班牙语等广泛使用但高质量标注数据相对稀缺的语言。ultrachat-es-30k-topics数据集应运而生,它从大规模英西机器翻译对话中精选3万条样本,并利用零样本分类模型自动标注13个语义主题,为西班牙语对话系统的主题感知微调与评估提供了重要资源。该数据集与拉美地区人工智能研究热潮紧密相连,其开放许可协议降低了非英语社区参与大语言模型研究的门槛,推动了多语言对话理解、跨文化话题建模以及低资源场景下零样本分类技术的交叉探索。
以上内容由遇见数据集搜集并总结生成


