corypaik/prost
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/corypaik/prost
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
extended:
- original
language_creators:
- expert-generated
language:
- en-US
license:
- apache-2.0
multilinguality:
- monolingual
paperswithcode_id: prost
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- multiple-choice-qa
- open-domain-qa
---
# PROST: Physical Reasoning about Objects Through Space and Time
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/nala-cub/prost
- **Paper:** https://arxiv.org/abs/2106.03634
- **Leaderboard:**
- **Point of Contact:** [Stéphane Aroca-Ouellette](mailto:stephane.aroca-ouellette@colorado.edu)
### Dataset Summary
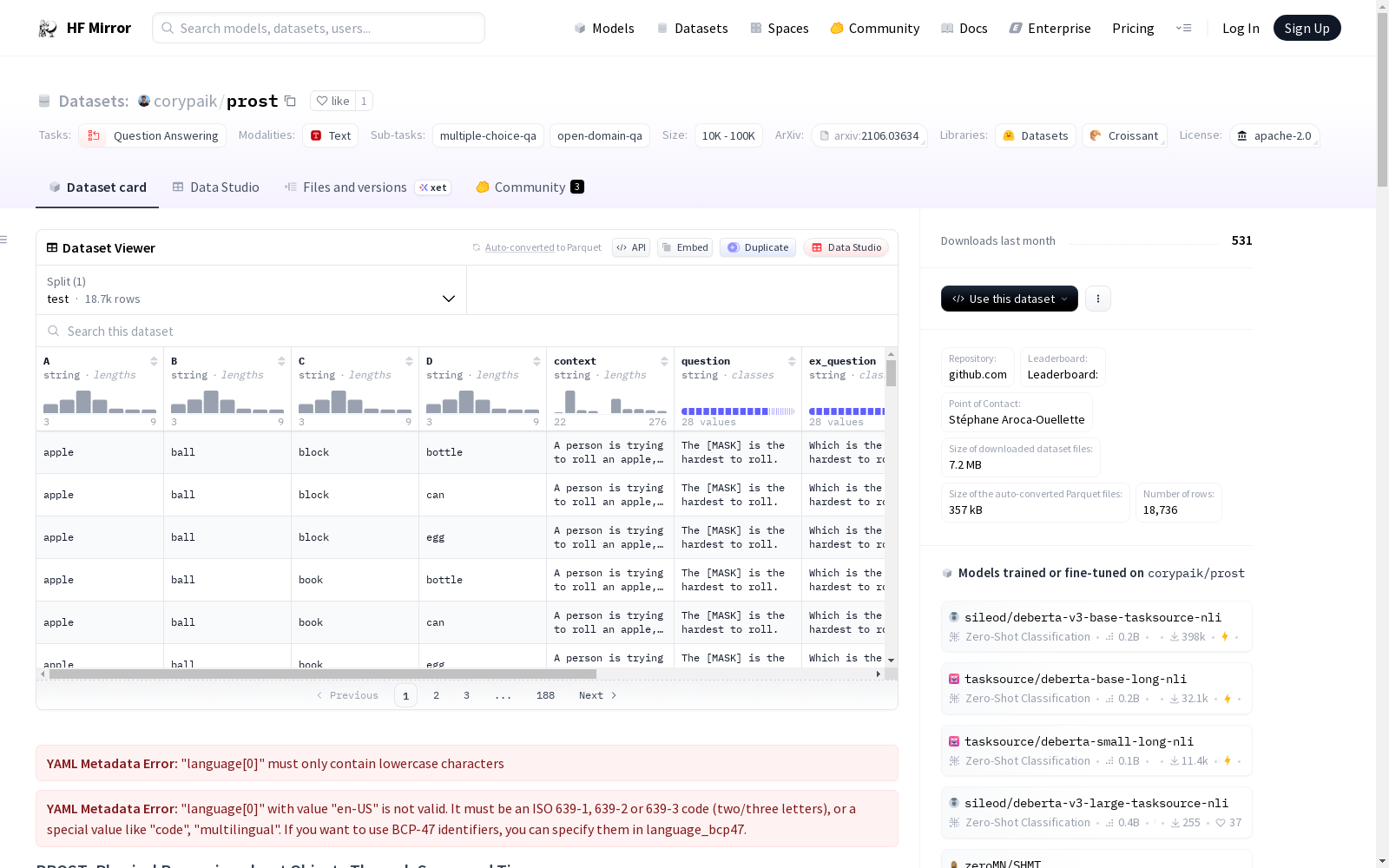
*Physical Reasoning about Objects Through Space and Time* (PROST) is a probing dataset to evaluate the ability of pretrained LMs to understand and reason about the physical world. PROST consists of 18,736 cloze-style multiple choice questions from 14 manually curated templates, covering 10 physical reasoning concepts: direction, mass, height, circumference, stackable, rollable, graspable, breakable, slideable, and bounceable.
### Supported Tasks and Leaderboards
The task is multiple choice question answering, but you can formulate it multiple ways. You can use `context` and `question` to form cloze style questions, or `context` and `ex_question` as multiple choice question answering. See the [GitHub](https://github.com/nala-cub/prost) repo for examples using GPT-1, GPT-2, BERT, RoBERTa, ALBERT, T5, and UnifiedQA.
### Languages
The text in the dataset is in English. The associated BCP-47 code is `en-US`.
## Dataset Structure
### Data Instances
An example looks like this:
```json
{
"A": "glass",
"B": "pillow",
"C": "coin",
"D": "ball",
"context": "A person drops a glass, a pillow, a coin, and a ball from a balcony.",
"ex_question": "Which object is the most likely to break?",
"group": "breaking",
"label": 0,
"name": "breaking_1",
"question": "The [MASK] is the most likely to break."
}
```
### Data Fields
- `A`: Option A (0)
- `B`: Option B (1)
- `C`: Option C (2)
- `D`: Option D (3)
- `context`: Context for the question
- `question`: A cloze style continuation of the context.
- `ex_question`: A multiple-choice style question.
- `group`: The question group, e.g. *bouncing*
- `label`: A ClassLabel indication the correct option
- `name':` The template identifier.
### Data Splits
The dataset contains 18,736 examples for testing.
## Dataset Creation
### Curation Rationale
PROST is designed to avoid models succeeding in unintended ways. First, PROST provides no training data, so as to probe models in a zero-shot fashion. This prevents models from succeeding through spurious correlations between testing and training, and encourages success through a true understanding of and reasoning about the concepts at hand. Second, we manually write templates for all questions in an effort to prevent models from having seen the exact same sentences in their training data. Finally, it focuses on a small set of well defined, objective concepts that only require a small vocabulary. This allows researchers to focus more on the quality of training data rather than on size of it.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
PROST is licensed under the Apache 2.0 license.
### Citation Information
```
@inproceedings{aroca-ouellette-etal-2021-prost,
title = "{PROST}: {P}hysical Reasoning about Objects through Space and Time",
author = "Aroca-Ouellette, St{\'e}phane and
Paik, Cory and
Roncone, Alessandro and
Kann, Katharina",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.404",
pages = "4597--4608",
}
```
### Contributions
Thanks to [@corypaik](https://github.com/corypaik) for adding this dataset.
annotations_creators:
- 专家生成
extended:
- 原始
language_creators:
- 专家生成
language:
- en-US(美式英语)
license:
- Apache-2.0
multilinguality:
- 单语言
paperswithcode_id: prost
size_categories:
- 10K<n<100K
source_datasets:
- 原始
task_categories:
- 问答
task_ids:
- 多项选择问答
- 开放域问答
---
# PROST:基于时空的物体物理推理
## 目录
- [目录](#table-of-contents)
- [数据集概述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言说明](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集策展人](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献](#contributions)
## 数据集概述
- **主页:** 无
- **代码仓库:** https://github.com/nala-cub/prost
- **相关论文:** https://arxiv.org/abs/2106.03634
- **排行榜:** 无
- **联系人:** [Stéphane Aroca-Ouellette](mailto:stephane.aroca-ouellette@colorado.edu)
### 数据集摘要
*基于时空的物体物理推理*(PROST)是一款探针数据集,用于评估预训练大语言模型(Large Language Model,LLM)理解与推理物理世界的能力。PROST包含18736道完形填空式多项选择题,源自14个人工精心设计的模板,涵盖10项物理推理概念:方向、质量、高度、周长、可堆叠性、可滚动性、可抓握性、易碎性、可滑动性与可弹跳性。
### 支持任务与排行榜
本任务为多项选择问答,也可通过多种方式构建任务形式。你可以使用`context`(上下文)与`question`(问题)组合为完形填空式问题,或使用`context`与`ex_question`(完整问题)完成多项选择问答。可参考[GitHub](https://github.com/nala-cub/prost)仓库中针对GPT-1、GPT-2、BERT、RoBERTa、ALBERT、T5与UnifiedQA的使用示例。
### 语言说明
本数据集文本语言为英语,对应的BCP-47语言代码为`en-US`。
## 数据集结构
### 数据实例
一个数据实例如所示:
json
{
"A": "glass",
"B": "pillow",
"C": "coin",
"D": "ball",
"context": "一名行人从阳台丢下玻璃杯、枕头、硬币与球。",
"ex_question": "以下哪个物体最有可能碎裂?",
"group": "breaking",
"label": 0,
"name": "breaking_1",
"question": "最有可能碎裂的[MASK]是。"
}
### 数据字段
- `A`: 选项A(对应标签0)
- `B`: 选项B(对应标签1)
- `C`: 选项C(对应标签2)
- `D`: 选项D(对应标签3)
- `context`: 问题上下文
- `question`: 上下文的完形填空式续写问题
- `ex_question`: 完整的多项选择式问题
- `group`: 问题所属组别,例如*bouncing*(弹跳类)
- `label`: 指示正确选项的分类标签(ClassLabel)
- `name`: 模板标识符。
### 数据划分
本数据集包含18736条测试样本。
## 数据集构建
### 构建初衷
PROST旨在避免模型通过非预期方式完成任务。首先,PROST未提供训练数据,以零样本(Zero-shot)方式对模型进行探针测试,这可防止模型通过测试集与训练集之间的虚假关联获得正确结果,促使模型依靠对目标概念的真正理解与推理取得成功。其次,我们手动编写所有问题的模板,以避免模型在训练数据中见过完全相同的句子。最后,本数据集聚焦于一组少量定义明确、客观的概念,仅需少量基础词汇,这使得研究人员可将精力更多集中于训练数据的质量而非规模。
### 源数据
#### 初始数据收集与标准化
【需补充更多信息】
#### 源语言生成者是谁?
【需补充更多信息】
### 注释
#### 注释流程
【需补充更多信息】
#### 注释人员是谁?
【需补充更多信息】
### 个人与敏感信息
【需补充更多信息】
## 数据使用注意事项
### 数据集的社会影响
【需补充更多信息】
### 偏差讨论
【需补充更多信息】
### 其他已知局限性
【需补充更多信息】
## 附加信息
### 数据集策展人
【需补充更多信息】
### 许可信息
PROST采用Apache 2.0许可协议。
### 引用信息
@inproceedings{aroca-ouellette-etal-2021-prost,
title = "{PROST}: {P}hysical Reasoning about Objects through Space and Time",
author = "Aroca-Ouellette, Stéphane and
Paik, Cory and
Roncone, Alessandro and
Kann, Katharina",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.404",
pages = "4597--4608",
}
### 贡献
感谢[@corypaik](https://github.com/corypaik)贡献本数据集。
提供机构:
corypaik
原始信息汇总
数据集概述
数据集名称
- 名称: PROST: Physical Reasoning about Objects Through Space and Time
数据集描述
- 描述: PROST是一个用于评估预训练语言模型理解和推理物理世界能力的探测数据集。它包含18,736个填空式多项选择题,来自14个手动筛选的模板,涵盖10个物理推理概念。
支持的任务和排行榜
- 任务: 多项选择问答
- 任务形式: 使用
context和question形成填空式问题,或使用context和ex_question作为多项选择问答。
语言
- 语言: 英语 (
en-US)
数据集结构
- 数据实例: 每个实例包含选项A、B、C、D,上下文
context,问题question和ex_question,问题组group,正确选项标签label,以及模板标识name。 - 数据字段: 包括选项、上下文、问题、问题组、正确选项标签和模板标识。
- 数据分割: 数据集包含18,736个测试实例。
数据集创建
- 许可证: Apache 2.0
- 数据集创建理由: 设计用于避免模型以非预期方式成功,通过零样本测试和手动编写模板来评估模型对物理概念的理解和推理能力。
其他信息
- 许可证信息: 数据集根据Apache 2.0许可证发布。
- 引用信息: 提供了一个引用参考,用于学术引用。
搜集汇总
数据集介绍
构建方式
在物理推理研究领域,PROST数据集的构建体现了严谨的科学设计理念。该数据集通过专家精心设计的14个手动模板,生成了18,736个填空式多项选择题,覆盖了方向、质量、高度等10个核心物理概念。构建过程强调零样本评估,避免提供训练数据,从而防止模型通过训练与测试间的虚假关联获得成功。所有问题模板均为人工撰写,旨在确保模型无法在预训练数据中找到完全相同的句子,进而迫使模型依赖对物理概念的深层理解进行推理。
特点
PROST数据集在物理常识推理任务中展现出独特优势。其问题设计聚焦于一组定义明确、客观且仅需有限词汇的物理概念,如可滚动性、可抓握性等,这有助于研究者更关注训练数据的质量而非规模。数据集采用填空与多项选择两种问题表述形式,提供了灵活的评估框架。所有实例均用于测试,规模介于一万至十万之间,为模型零样本推理能力提供了标准化、可复现的基准。
使用方法
该数据集主要用于评估预训练语言模型对物理世界的理解和推理能力。使用者可依据`context`与`question`字段构建填空式问题,或结合`context`与`ex_question`进行多项选择题回答。数据以JSON格式组织,每个实例包含四个选项、上下文、问题文本、概念分组及正确答案标签。研究人员可直接加载数据集,利用现有模型进行预测,并通过`label`字段验证模型性能,从而深入探究模型物理常识的掌握程度。
背景与挑战
背景概述
在人工智能领域,物理常识推理是衡量模型是否具备类人智能的关键维度。PROST数据集由Stéphane Aroca-Ouellette、Cory Paik等研究人员于2021年创建,旨在系统评估预训练语言模型对物理世界的理解与推理能力。该数据集聚焦于物体在时空中的物理属性,涵盖方向、质量、高度等十个核心概念,通过精心设计的填空式多选题,挑战模型在零样本设置下的推理性能。其诞生推动了认知科学与自然语言处理的交叉研究,为探索模型是否真正掌握物理规律提供了标准化基准。
当前挑战
PROST数据集致力于解决物理常识推理这一核心领域问题,其挑战在于模型需超越表面语言模式,深入理解物体属性与物理规律的动态交互。构建过程中的挑战尤为显著:为确保评估的纯净性,数据集采用零样本设计,完全避免训练数据,从而消除模型通过虚假关联取巧的可能性;同时,所有问题模板均需人工精心编写,以防止模型从预训练语料中直接记忆答案,这对模板的多样性与概念覆盖提出了极高要求。此外,如何在有限词汇范围内精确表达复杂物理概念,并保持问题的客观性与一致性,亦是构建中的关键难点。
常用场景
经典使用场景
在自然语言处理领域,物理推理能力是评估预训练语言模型认知深度的关键维度。PROST数据集通过精心设计的完形填空式多项选择题,为研究者提供了一个零样本测试平台,用以探究模型对物体物理属性的理解。该数据集覆盖方向、质量、高度等十个核心概念,其经典使用场景在于系统性地评估模型在无需额外训练数据的情况下,能否基于常识进行物理世界推理,从而揭示模型内在的知识表征局限。
实际应用
在实际应用层面,PROST数据集所针对的物理推理能力是具身智能与机器人交互的核心基础。例如,在家庭服务机器人场景中,系统需判断物体的可抓握性、易碎性或可滚动性,以安全地执行抓取、搬运等任务。该数据集可为这类系统的自然语言接口提供评估标准,确保机器人能够依据物理常识做出合理决策,从而提升其在复杂动态环境中的适应性与可靠性。
衍生相关工作
围绕PROST数据集,已衍生出一系列探索物理推理前沿的工作。例如,研究团队利用GPT、BERT、RoBERTa等模型在该数据集上进行零样本测试,系统分析了不同架构的物理常识表征差异。这些工作进一步催生了针对物理知识注入的模型改进方法,如结合外部知识库或强化学习框架,以增强模型对物理规律的隐式学习能力,推动了认知推理与语言建模的交叉领域进展。
以上内容由遇见数据集搜集并总结生成


