ssong1/llmperf-bedrock
收藏Hugging Face2024-01-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ssong1/llmperf-bedrock
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
---
Utilizing the [LLMPerf](https://github.com/ray-project/llmperf), we have benchmarked a selection of LLM inference providers.
Our analysis focuses on evaluating their performance, reliability, and efficiency under the following key metrics:
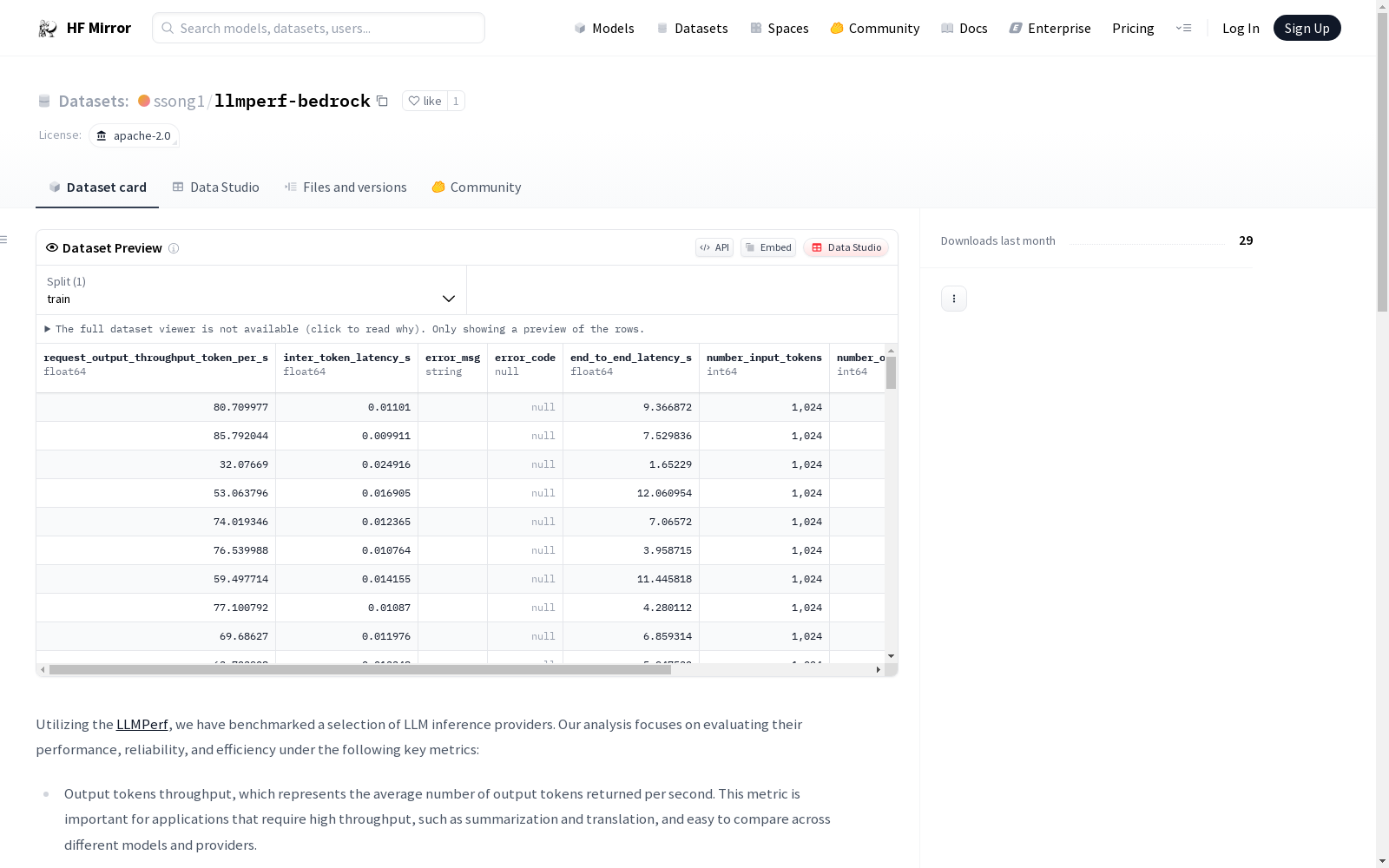
- Output tokens throughput, which represents the average number of output tokens returned per second. This metric is important for applications that require high throughput, such as summarization and translation, and easy to compare across different models and providers.
- Time to first token (TTFT), which represents the duration of time that LLM returns the first token. TTFT is especially important for streaming applications, such as chatbots.
### Time to First Token (seconds)
For streaming applications, the TTFT is how long before the LLM returns the first token.
| Framework | Model | Median | Mean | Min | Max | P25 | P75 | P95 | P99 |
|------------|------------------------------------------------------------------------------------------------------|---------|--------|-------|-------|-------|-------|-------|-------|
| bedrock | claude-instant-v1 | 1.21 | 1.29 | 1.12 | 2.19 | 1.17 | 1.27 | 1.89 | 2.17 |
### Output Tokens Throughput (tokens/s)
The output tokens throughput is measured as the average number of **output** tokens returned per second.
We collect results by sending 100 requests to each LLM inference provider, and calculate the mean output tokens throughput based on 100 requests.
A higher output tokens throughput indicates a higher throughput of the LLM inference provider.
| Framework | Model | Median | Mean | Min | Max | P25 | P75 | P95 | P99 |
|:------------|:----------------------------------------------|---------:|-------:|------:|------:|------:|------:|------:|------:|
| bedrock | claude-instant-v1 | 65.64 | 65.98 | 16.05 | 110.38 | 57.29 | 75.57 | 99.73 | 106.42 |
#### Run Configurations
testscript [token_benchmark_ray.py](https://github.com/ray-project/llmperf/blob/main/token_benchmark_ray.py)
For each provider, we perform:
- Total number of requests: 100
- Concurrency: 1
- Prompt's token length: 1024
- Expected output length: 1024
- Tested models: claude-instant-v1-100k
```
python token_benchmark_ray.py \
--model bedrock/anthropic.claude-instant-v1 \
--mean-input-tokens 1024 \
--stddev-input-tokens 0 \
--mean-output-tokens 1024 \
--stddev-output-tokens 100 \
--max-num-completed-requests 100 \
--num-concurrent-requests 1 \
--llm-api litellm
```
We ran the LLMPerf clients from an on-premise Kubernetes Bastion host.
The results were up-to-date of January 19, 2023, 3pm KST. You could find the detailed results in the [raw_data](https://huggingface.co/datasets/ssong1/llmperf-bedrock/tree/main/raw_data) folder.
#### Caveats and Disclaimers
- The endpoints provider backend might vary widely, so this is not a reflection on how the software runs on a particular hardware.
- The results may vary with time of day.
- The results (e.g. measurement of TTFT) depend on client location, and can also be biased by some providers lagging on the first token in order to increase ITL.
- The results is only a proxy of the system capabilities and is also impacted by the existing system load and provider traffic.
- The results may not correlate with users’ workloads.
---
许可证:Apache-2.0
---
本研究依托[LLMPerf](https://github.com/ray-project/llmperf)工具,对多款大语言模型(Large Language Model, LLM)推理服务提供商开展了基准测试。本次分析聚焦于通过以下核心指标评估各提供商的性能、可靠性与运行效率:
- 输出Token吞吐量(Output tokens throughput):即每秒返回的平均输出Token数量。该指标对于摘要生成、机器翻译等高吞吐量需求场景至关重要,同时便于在不同模型与提供商间进行横向对比。
- 首Token返回时延(Time to First Token, TTFT):即大语言模型返回首个Token所需的时长,对于聊天机器人等流式应用场景尤为关键。
### 首Token返回时延(秒)
对于流式应用而言,TTFT指大语言模型返回首个Token前的等待时长。
| 框架 | 模型 | 中位数 | 均值 | 最小值 | 最大值 | P25分位数 | P75分位数 | P95分位数 | P99分位数 |
|------------|------------------------------------------------------------------------------------------------------|---------|--------|-------|-------|-------|-------|-------|-------|
| bedrock | claude-instant-v1 | 1.21 | 1.29 | 1.12 | 2.19 | 1.17 | 1.27 | 1.89 | 2.17 |
### 输出Token吞吐量(Token/秒)
输出Token吞吐量指每秒返回的平均输出Token数量。本次测试通过向每家大语言模型推理服务提供商发送100次请求,基于这100次请求的结果计算平均输出Token吞吐量。输出Token吞吐量越高,代表该推理服务提供商的吞吐量性能越强。
| 框架 | 模型 | 中位数 | 均值 | 最小值 | 最大值 | P25分位数 | P75分位数 | P95分位数 | P99分位数 |
|:------------|:----------------------------------------------|---------:|-------:|------:|------:|------:|------:|------:|------:|
| bedrock | claude-instant-v1 | 65.64 | 65.98 | 16.05 | 110.38 | 57.29 | 75.57 | 99.73 | 106.42 |
#### 测试运行配置
测试脚本为[token_benchmark_ray.py](https://github.com/ray-project/llmperf/blob/main/token_benchmark_ray.py)
针对每家服务提供商,本次测试执行以下配置:
- 总请求数:100
- 并发请求数:1
- 输入Prompt的Token长度:1024
- 预期输出Token长度:1024
- 测试模型:claude-instant-v1-100k
python token_benchmark_ray.py
--model bedrock/anthropic.claude-instant-v1
--mean-input-tokens 1024
--stddev-input-tokens 0
--mean-output-tokens 1024
--stddev-output-tokens 100
--max-num-completed-requests 100
--num-concurrent-requests 1
--llm-api litellm
本次测试的LLMPerf客户端部署于本地Kubernetes堡垒主机上。测试结果的截止更新时间为韩国标准时间2023年1月19日15:00,详细测试结果可参见[raw_data](https://huggingface.co/datasets/ssong1/llmperf-bedrock/tree/main/raw_data)文件夹。
#### 测试说明与免责声明
- 各服务提供商的后端基础设施差异较大,因此本测试结果无法反映软件在特定硬件环境下的实际运行表现。
- 测试结果可能随当日时段不同而产生波动。
- 测试结果(如首Token返回时延的测量值)受客户端地理位置影响,部分提供商还可能通过延迟返回首Token以提升令牌间间隔时长(ITL),进而导致测试结果存在偏差。
- 本次测试结果仅为系统性能的近似表征,同时会受当前系统负载与提供商服务流量的影响。
- 测试结果可能与用户自身的业务负载不具备直接相关性。
提供机构:
ssong1
原始信息汇总
数据集概述
该数据集通过使用LLMPerf对一系列LLM推理提供商进行基准测试,重点关注以下关键指标:
- 输出令牌吞吐量:表示每秒返回的平均输出令牌数。该指标对于需要高吞吐量的应用(如摘要和翻译)非常重要,且易于在不同模型和提供商之间进行比较。
- 首次令牌时间(TTFT):表示LLM返回第一个令牌所需的时间。TTFT对于流式应用(如聊天机器人)尤为重要。
首次令牌时间(TTFT)
对于流式应用,TTFT是LLM返回第一个令牌所需的时间。
| 框架 | 模型 | 中位数 | 平均值 | 最小值 | 最大值 | P25 | P75 | P95 | P99 |
|---|---|---|---|---|---|---|---|---|---|
| bedrock | claude-instant-v1 | 1.21 | 1.29 | 1.12 | 2.19 | 1.17 | 1.27 | 1.89 | 2.17 |
输出令牌吞吐量(tokens/s)
输出令牌吞吐量是每秒返回的平均输出令牌数。通过向每个LLM推理提供商发送100个请求并计算100个请求的平均输出令牌吞吐量来收集结果。输出令牌吞吐量越高,表示LLM推理提供商的吞吐量越高。
| 框架 | 模型 | 中位数 | 平均值 | 最小值 | 最大值 | P25 | P75 | P95 | P99 |
|---|---|---|---|---|---|---|---|---|---|
| bedrock | claude-instant-v1 | 65.64 | 65.98 | 16.05 | 110.38 | 57.29 | 75.57 | 99.73 | 106.42 |
运行配置
测试脚本为token_benchmark_ray.py。
对于每个提供商,执行以下配置:
- 总请求数:100
- 并发数:1
- 提示令牌长度:1024
- 预期输出长度:1024
- 测试模型:claude-instant-v1-100k
python python token_benchmark_ray.py --model bedrock/anthropic.claude-instant-v1 --mean-input-tokens 1024 --stddev-input-tokens 0 --mean-output-tokens 1024 --stddev-output-tokens 100 --max-num-completed-requests 100 --num-concurrent-requests 1 --llm-api litellm
测试结果截至2023年1月19日,3pm KST。详细结果可在raw_data文件夹中找到。
注意事项和免责声明
- 提供商的后端可能差异很大,因此结果不代表软件在特定硬件上的运行情况。
- 结果可能随时间变化。
- 结果(如TTFT的测量)取决于客户端位置,并可能受某些提供商在第一个令牌上延迟以增加ITL的影响。
- 结果仅是系统能力的代理,并受现有系统负载和提供商流量的影响。
- 结果可能与用户的工作负载不相关。
搜集汇总
数据集介绍
构建方式
ssong1/llmperf-bedrock数据集是基于LLMPerf框架构建的,其核心在于评估不同LLM推理服务提供者的性能、可靠性和效率。数据集通过执行100次请求,针对claude-instant-v1模型,在单线程并发条件下,以1024个token的输入长度和预期输出长度,进行输出tokens吞吐量和首次响应时间的测量,从而构建起一个涵盖多个性能指标的详实数据集。
特点
本数据集的特点在于其详尽的性能指标,包括输出tokens吞吐量和中位数、平均数、最小值、最大值以及不同百分位数的时间至首token。这些数据不仅反映了LLM推理服务提供者的即时性能,还揭示了其在不同负载和条件下的稳定性。数据集的构建考虑了实际应用场景,如流应用和需要高吞吐量的应用,使其具有广泛的适用性和参考价值。
使用方法
使用该数据集时,用户可以通过运行token_benchmark_ray.py脚本,配置相应的模型、输入输出token长度、请求次数等参数,来复现和验证数据集的性能指标。数据集的原始结果存储在raw_data文件夹中,用户可以根据需要对数据进行进一步分析。同时,用户需注意结果可能受到服务端后端变化、时间、地理位置等因素的影响,因此在使用时应结合实际应用场景进行解读。
背景与挑战
背景概述
ssong1/llmperf-bedrock数据集,是在机器学习领域,特别是在大型语言模型性能评估领域的一项重要工作。该数据集由使用LLMPerf工具进行基准测试的一系列LLM推理提供者组成,旨在评估它们的性能、可靠性和效率。创建于2023年,由相关研究人员和机构基于Apache-2.0协议公开,其核心研究问题聚焦于大型语言模型在不同场景下的响应速度和输出效率,对推动该领域的技术发展和应用具有重要意义。
当前挑战
该数据集在构建和应用过程中面临的挑战主要包括:如何准确量化大型语言模型在实时应用中的响应速度(TTFT),以及如何评估其输出效率(Output Tokens Throughput)。此外,测试结果的变异性,如时间、地点、系统负载等因素的影响,也为数据集的准确性和可靠性带来了挑战。在模型评估过程中,还需考虑测试脚本和运行配置的合理性和准确性,以确保评估结果的公正性和有效性。
常用场景
经典使用场景
在人工智能领域,尤其是自然语言处理任务中,对语言模型的性能评估至关重要。ssong1/llmperf-bedrock数据集提供了一个衡量大型语言模型(LLM)推理性能的基准,包括输出令牌吞吐量和首次返回令牌时间(TTFT)。该数据集的经典使用场景在于,研究人员可以通过这些指标对不同的LLM推理服务提供商进行比较,以优化模型选择和部署策略。
衍生相关工作
基于ssong1/llmperf-bedrock数据集的研究成果,已经衍生出了一系列相关工作,包括对LLM性能影响因素的深入分析、模型性能优化策略的研究以及新型性能评估指标的开发。这些研究进一步推动了LLM技术的进步,为相关领域的研究提供了新的视角和方法论。
数据集最近研究
最新研究方向
在自然语言处理领域,ssong1/llmperf-bedrock数据集的构建旨在通过量化大型语言模型(LLM)推理提供商的性能、可靠性和效率,推进相关技术的优化与发展。该数据集最近的研究方向聚焦于输出令牌吞吐量和首次令牌响应时间这两个关键指标,对于实时应用如聊天机器人以及高吞吐量需求的应用如摘要和翻译具有重要意义。通过精确评估不同框架和模型在这些指标上的表现,研究为优化LLM的即时响应性能和系统负载管理提供了实证基础,对于提升用户体验和系统资源利用效率具有显著影响和意义。
以上内容由遇见数据集搜集并总结生成


