GenQA
收藏Hugging Face2024-06-21 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tomg-group-umd/GenQA
下载链接
链接失效反馈官方服务:
资源简介:
GenQA数据集包含超过1000万个经过清理和去重的指令样本,这些样本是从少数精心设计的提示中生成的。该数据集专为大规模LLM微调设计,包含多个涵盖不同主题的分割。每个实例模拟了人类用户与LLM虚拟助手之间的对话,格式统一,适用于单轮和多轮对话。数据集主要用于学术和研究目的,旨在推进LLM微调实践的知识。
The GenQA dataset contains over 10 million cleaned and deduplicated instruction samples generated from a small number of meticulously designed prompts. This dataset is specifically tailored for large-scale LLM fine-tuning, and includes multiple splits covering diverse topics. Each instance simulates a conversation between a human user and an LLM-powered virtual assistant, with a unified format compatible with both single-turn and multi-turn dialogues. The dataset is primarily intended for academic and research purposes, aiming to advance the knowledge of LLM fine-tuning practices.
创建时间:
2024-06-13
原始信息汇总
数据集概述
数据集信息
特征
- text: 包含内容和角色信息。
- content: 字符串类型
- role: 字符串类型
- prompt: 字符串类型
- template: 字符串类型
- idx: 整数类型
- category: 字符串类型
分割
- code: 868523270 字节,513483 个样本
- dialog: 2699180502 字节,819154 个样本
- general: 389512191 字节,304920 个样本
- math: 944242317 字节,515509 个样本
- mmlu: 4603359859 字节,2409841 个样本
- multiple_choice: 570290204 字节,372610 个样本
- writing: 2998330544 字节,932362 个样本
- academic: 8753888424 字节,4210076 个样本
- task: 2222907706 字节,1004179 个样本
大小
- 下载大小: 10125117516 字节
- 数据集大小: 24050235017 字节
配置
- default: 包含多个分割的数据文件路径
数据集详情
数据集描述
- 语言: 英语
- 许可证: Creative Commons NonCommercial (CC BY-NC 4.0)
用途
- 直接使用: 适用于工业规模微调实践的开放研究
- 超出范围使用: 不适用于需要验证事实准确性的应用或任何恶意或不道德的活动
数据集结构
- 字段:
- text: 包含实际训练文本(输入和输出)
- prompt: 指定指令生成的要求
- template: 可选的提示模板类型描述
- category: 将代码数据分为编码、库和 Markdown
数据集创建
- 创建理由: 展示自主编写指令数据集的有效性,并生成与商业指令集规模相当的研究指令数据集
- 源数据: 包含用户和助手之间模拟对话的问答对
- 数据收集和处理: 使用 Gemini 语言模型编写问题并去重,所有阶段使用 Python 完成
偏差、风险和限制
- 风险: 数据集可能包含事实不准确性,未手动检查事实正确性
- 建议: 用户应意识到潜在的事实不准确性,并在使用数据集时验证关键信息,减轻任何潜在偏差和错误
搜集汇总
数据集介绍
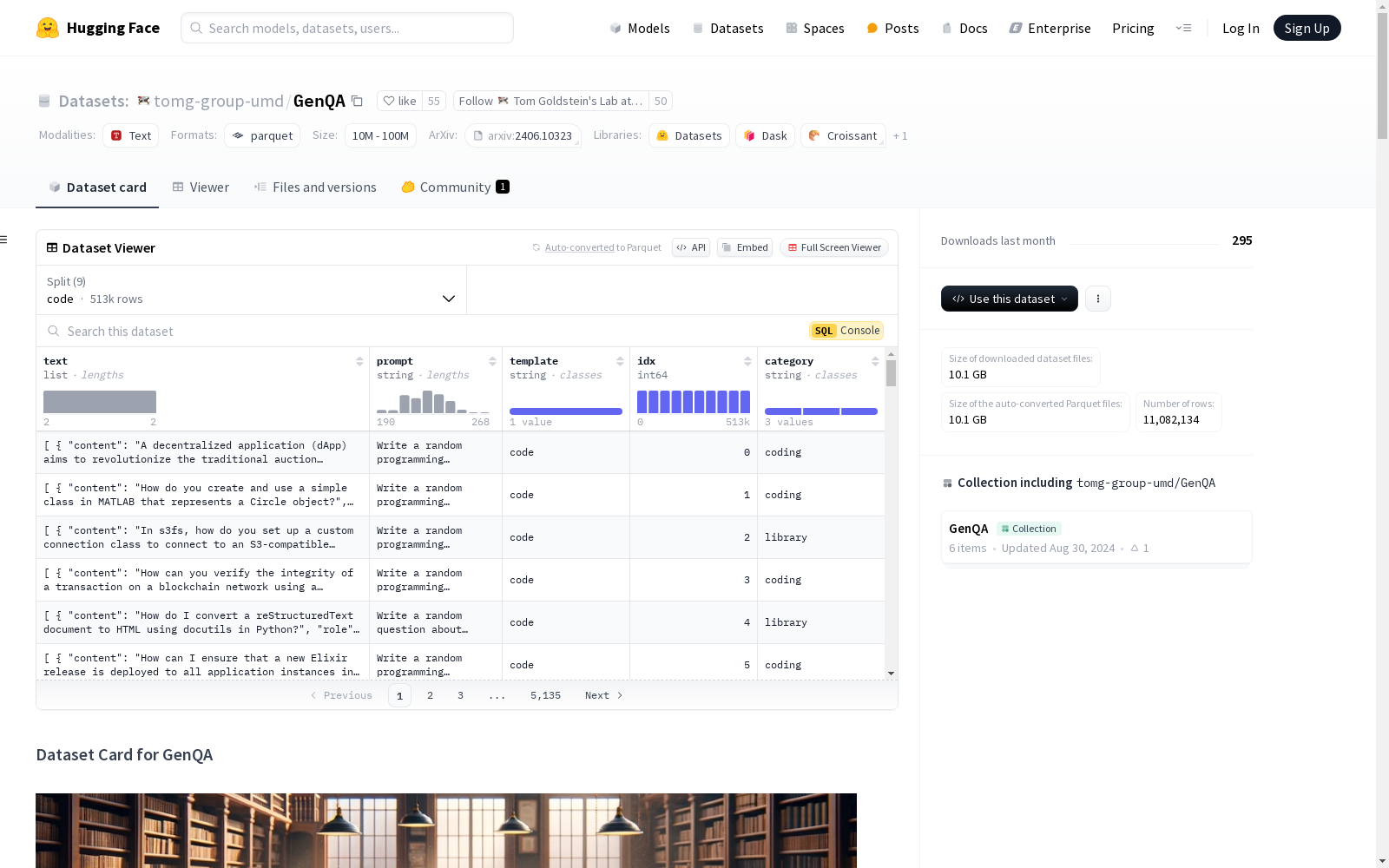
构建方式
GenQA数据集的构建基于精心设计的提示工程,通过大规模语言模型(LLM)自主生成超过1000万条经过清理和去重的指令样本。这些样本通过单一提示生成,避免了复杂多阶段流程的依赖,展示了提示工程在生成高质量训练数据方面的潜力。数据集的构建过程完全自动化,未依赖人工标注或外部问题输入,确保了数据的多样性和规模。
特点
GenQA数据集以其规模庞大和多样性著称,涵盖了代码、对话、数学、学术等多个领域的分割。每个样本包含用户与虚拟助手之间的模拟对话,支持单轮和多轮对话格式,且所有对话均采用统一的JSON格式存储,便于与现有工具库(如Hugging Face的Transformers)兼容。数据集还通过类别字段对数据进行了细分,便于用户根据需求选择特定领域的数据。
使用方法
GenQA数据集可通过Hugging Face的`datasets`库轻松加载和使用。用户只需几行代码即可下载并选择特定分割(如学术或对话),随后可直接用于模型训练或研究分析。数据集的多轮对话格式与Transformers库的聊天模板兼容,支持快速集成到现有工作流中。由于其规模和质量,该数据集特别适合用于大规模语言模型的微调和开放研究。
背景与挑战
背景概述
GenQA数据集由马里兰大学的研究团队于2024年创建,旨在通过精心设计的提示工程生成大规模、多样化的指令样本,以支持大规模语言模型的微调研究。该数据集包含超过1000万条经过清理和去重的指令样本,涵盖了代码、对话、数学、学术等多个领域。GenQA的独特之处在于其完全由大型语言模型自主生成,无需依赖人类标注或复杂的多阶段流程。这一创新方法不仅降低了数据生成的成本,还为语言模型的研究提供了新的数据来源,推动了该领域的发展。
当前挑战
GenQA数据集面临的主要挑战包括数据质量的保证和多样性的平衡。尽管提示工程能够生成大量样本,但如何确保这些样本在语义上的准确性和逻辑上的连贯性仍然是一个难题。此外,数据集中可能存在事实性错误,这要求研究人员在使用时进行额外的验证和修正。在构建过程中,研究人员还需应对数据去重和格式统一的技术挑战,以确保数据集的一致性和可用性。这些挑战不仅影响了数据集的直接应用,也对未来类似数据集的构建提出了更高的要求。
常用场景
经典使用场景
GenQA数据集在自然语言处理领域中被广泛用于大规模语言模型的微调任务。其多样化的指令样本涵盖了代码生成、对话系统、数学问题解答、学术写作等多个领域,为研究人员提供了一个丰富的训练资源。通过使用这些样本,研究人员可以有效地提升模型在特定任务上的表现,尤其是在多轮对话和复杂指令理解方面。
实际应用
在实际应用中,GenQA数据集被广泛用于开发智能对话系统、自动代码生成工具以及教育领域的智能辅导系统。例如,基于该数据集训练的模型可以用于生成高质量的代码片段,或为学生提供个性化的数学问题解答。此外,该数据集还可用于增强现有语言模型的多轮对话能力,提升用户体验。
衍生相关工作
GenQA数据集的推出催生了一系列相关研究,特别是在自动指令生成和模型微调领域。许多研究团队基于该数据集开发了新的微调算法,探索了如何通过少量提示生成高质量的训练数据。此外,该数据集还被用于评估不同模型在多任务学习中的表现,推动了多模态语言模型的研究进展。
以上内容由遇见数据集搜集并总结生成


