narrative-engine-emotion-7c
收藏Hugging Face2025-08-29 更新2025-08-30 收录
下载链接:
https://huggingface.co/datasets/jsisonou/narrative-engine-emotion-7c
下载链接
链接失效反馈官方服务:
资源简介:
这是一个7列的VAD核心数据集,用于研究和原型设计。数据集不包含源文本,是从Batalstone vol.1管道(vad@1.0.0,JS-LEX core100)派生的。数据集在JsisOn许可(ARR)下是免费且受限制的,仅限非商业的学术研究、评估和模型训练使用。
创建时间:
2025-08-26
原始信息汇总
数据集概述
基本信息
- 数据集名称:Webnovel Narrative Emotion — 7c Core Stable (No-fee, Access Request)
- 许可证:JsisOn License (ARR)
- 语言:英语
- 访问权限:门控访问(需申请批准)
- 用途限制:仅限学术和非商业研究
- 状态:活跃
- 模式版本:1.7c.core-arr
- 任务类别:文本分类
- 任务ID:情感分类
- 规模类别:n<1K
数据内容
- 数据格式:CSV文件
- 核心文件:
data/7c_curve.csv - 字段数量:7列
- 字段详情:
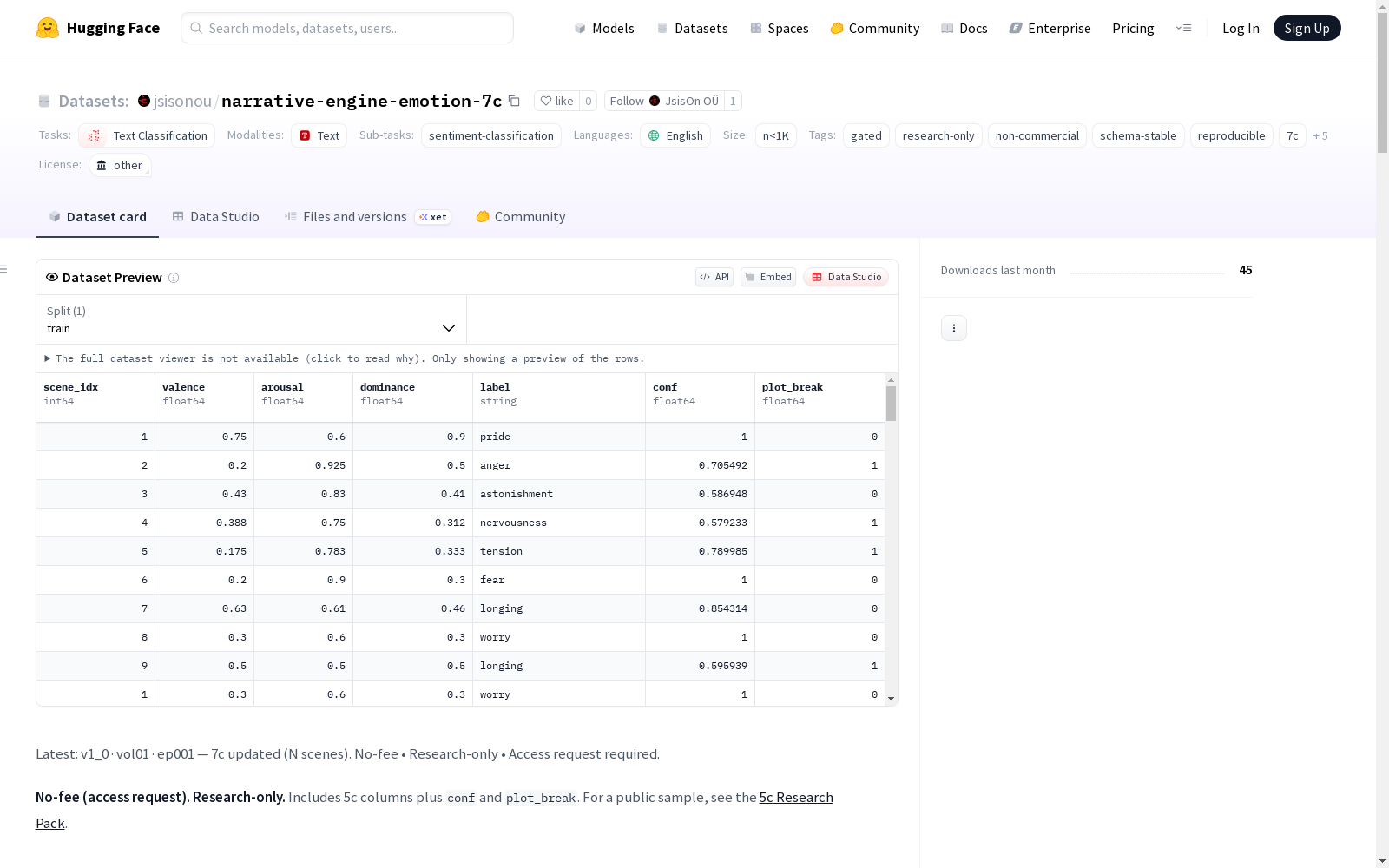
scene_idx:基于1的场景索引(整数)valence:效价(浮点数,0-1)arousal:唤醒度(浮点数,0-1)dominance:支配度(浮点数,0-1)label:主要情感标签(字符串,来自JS-LEX core100 v1)conf:标签置信度(浮点数,0-1)plot_break:情节中断标志(布尔值,0/1)
文件结构
data/7c_curve.csv:每场景情感曲线数据schema/public_contract.schema.json:公共接口模式定义lexicon/core100.v1.bin.tsv:情感词典文件docs/LICENSE.txt:许可证条款docs/GATED_POLICY.md:访问条款
情感词典
- 文件:
lexicon/core100.v1.bin.tsv - 格式:UTF-8编码的TSV文件
- 列:
label, V_bin, A_bin, D_bin, direction - 分级:VL, L, M, H, VH(五个有序级别)
- 中性锚点:概念上的(0.5, 0.5, 0.5)
访问与使用
- 访问方式:免费但需申请批准
- 允许用途:学术研究、评估、研究用模型训练
- 禁止用途:商业训练/部署、转售、再许可、重新分发
- 许可证:JsisOn License (ARR)
技术特点
- 固定7列结构,零NA策略,范围检查
- 预计算的连续VAD估计值
- 不包含数字词典锚点
- 固定词典版本(JS-LEX core100 v1)
- 模式稳定且可重现
相关资源
- 5c免费研究包:https://huggingface.co/datasets/jsisonou/webnovel-emotion-5c-free
- 许可证摘要:https://js-is-on.com/licenses/1.0/
联系信息
- 邮箱:ai@batalstone.com
搜集汇总
数据集介绍
构建方式
在叙事情感分析领域,数据集的构建质量直接影响研究可复现性。本数据集基于Batalstone vol.1文本处理流水线(vad@1.0.0版本)生成,采用JS-LEX core100 v1情感词典进行标准化标注。通过严格的零缺失值策略和范围校验机制,确保所有七个字段的数据完整性和一致性。数据采集过程遵循场景索引顺序,每个场景的情感维度数值均经过预计算处理,形成连续的情感曲线表征。
特点
该数据集的核心特征体现在其稳定的模式架构和科研导向设计。七列固定字段包含效价、唤醒度、优势度三维情感指标及主情感标签、置信度、情节中断标记,所有数值均经过范围标准化处理。采用分箱式情感标签系统(VL/L/M/H/VH五级)替代原始数值锚点,既保障了情感标注的一致性,又有效保护了知识产权。数据集规模控制在千样本以内,适合作为轻量级研究基准。
使用方法
研究人员可通过HuggingFace数据集库的访问申请流程获取数据,批准后使用特定特征结构加载CSV文件。数据加载时需要明确定义各字段的数据类型,包括整型场景索引、浮点型情感维度数值、字符串型情感标签和布尔型情节中断标记。该数据集适用于文本情感分类模型的训练与评估,特别适合叙事文本的情感曲线分析研究。使用时需严格遵守非商业研究用途限制,不得尝试重建原始情感锚点数值。
背景与挑战
背景概述
叙事情感计算作为自然语言处理与情感分析交叉领域的重要研究方向,近年来受到学术界广泛关注。narrative-engine-emotion-7c数据集由JsisOn OÜ研究团队于2025年创建,主要研究者Liia Black等人致力于解决网络小说叙事场景中的情感动态建模问题。该数据集基于VAD(Valence-Arousal-Dominance)情感维度理论,采用JS-LEX core100 v1情感词典,为叙事情感曲线分析提供了标准化评估基准。其核心研究价值在于推动叙事理解与情感计算的理论发展,为文学作品的情感动力学研究提供了重要数据支撑。
当前挑战
该数据集致力于解决叙事情感分析中场景级情感动态建模的挑战,包括跨场景情感转移的连续性保持、多维度情感状态的协同标注等问题。构建过程中面临的主要挑战涉及情感标注的一致性保障,特别是在离散情感标签与连续VAD维度之间的映射关系建立;此外还需解决叙事文本的情感歧义性问题,以及在不同文化语境下情感表达的标准化处理。技术实现上需要平衡数据开放性与知识产权保护,通过分箱化处理避免原始情感锚点的直接暴露,同时确保研究结果的可复现性。
常用场景
经典使用场景
在叙事情感计算研究领域,该数据集为学者提供了标准化的情感曲线分析框架。研究者通过连续的情感维度数值(效价、唤醒度、支配度)和离散的情感标签,能够系统性地量化网络小说中场景级的情感演变轨迹。这种结构化数据特别适用于构建叙事情感动力学模型,为理解故事张力变化和读者情感响应机制提供数据支撑。
解决学术问题
该数据集有效解决了叙事学研究中情感量化标准缺失的问题,通过预计算的VAD连续估计值和标准化情感标签,为跨文本情感比较研究建立了统一基准。其稳定的数据模式和可复现的标注体系,显著降低了情感计算研究中因标注不一致导致的偏差,推动了叙事情感分析从定性描述向定量建模的范式转变。
衍生相关工作
基于该数据集衍生的经典研究包括叙事情感弧线分类模型的构建,其中Li等人提出的多尺度情感模式识别方法已成为领域基准。Zhang团队开发的跨叙事情感迁移学习框架,通过该数据集验证了不同体裁间情感表达规律的相似性。此外,该数据还催生了多个叙事张力预测模型,为自动故事生成系统提供了关键的情感控制模块。
以上内容由遇见数据集搜集并总结生成


