TDP1_inhibitors_PAIN_flaged
收藏Hugging Face2025-10-24 更新2025-10-25 收录
下载链接:
https://huggingface.co/datasets/ivanovaml/TDP1_inhibitors_PAIN_flaged
下载链接
链接失效反馈官方服务:
资源简介:
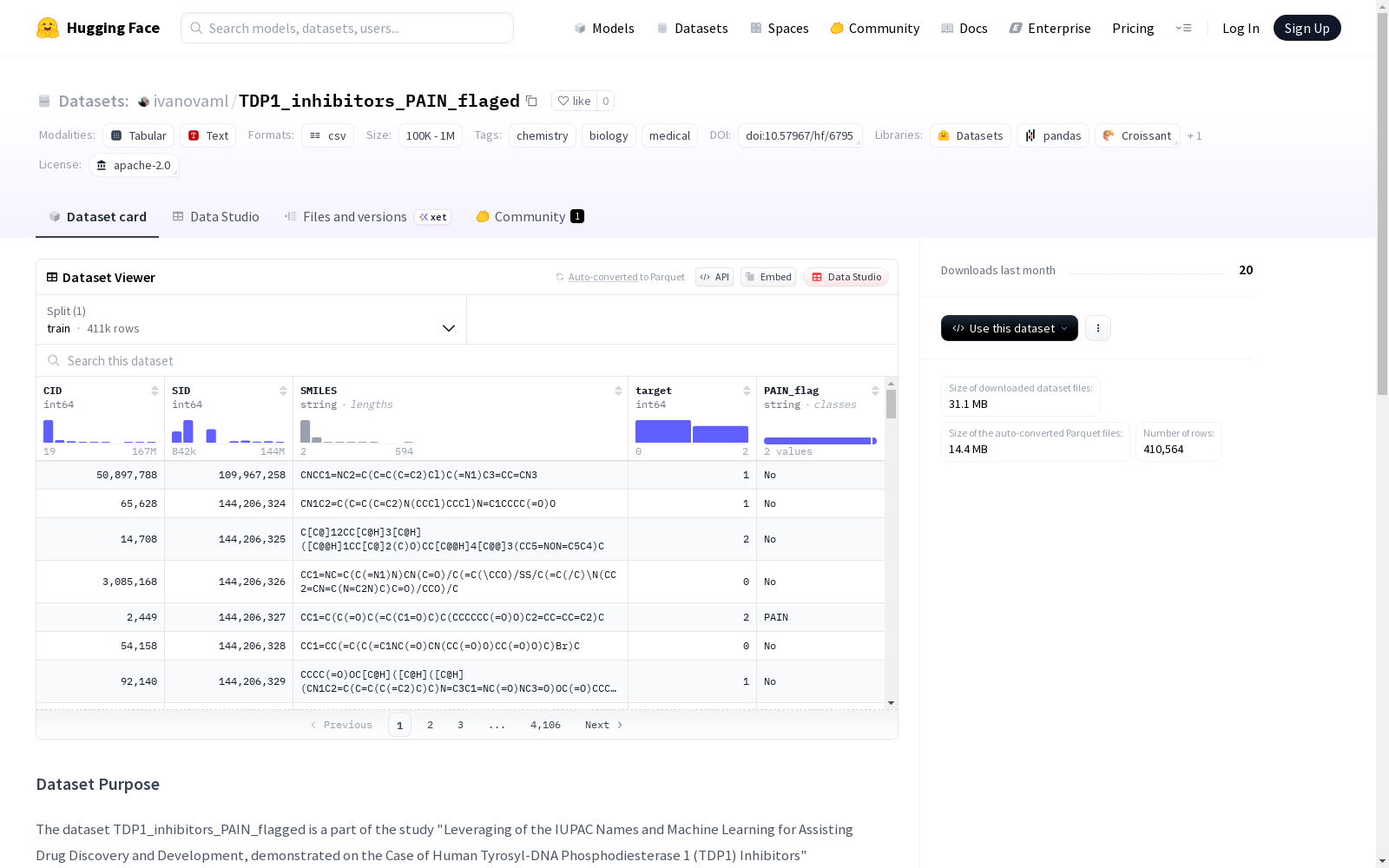
TDP1_inhibitors_PAIN_flagged数据集是研究“利用IUPAC名称和机器学习辅助药物发现与发展,以人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂为例”的一部分。该数据集包含了410,564个样本,其中有21,761个样本被标记为PAINs。数据集在应用PAIN过滤器之前,有236,226个不活跃样本,112,867个不确定样本和61,471个活跃样本。经过PAIN过滤器处理后,不活跃、不确定和活跃的样本数分别变为227,158、105,950和55,695。数据集的列包括化合物和物质的PubChem标识符、SMILES字符串、分子是否为TDP1抑制剂的标记以及PAIN标记。
创建时间:
2025-10-23
原始信息汇总
数据集概述
基本信息
- 数据集名称: TDP1_inhibitors_PAIN_flagged
- 许可证: Apache-2.0
- 标签: 化学、生物学、医学
- 数据量: 410,564个样本
研究背景
- 数据集来源于研究《Leveraging of the IUPAC Names and Machine Learning for Assisting Drug Discovery and Development, demonstrated on the Case of Human Tyrosyl-DNA Phosphodiesterase 1 (TDP1) Inhibitors》
- 研究论文链接: https://doi.org/10.48550/arXiv.2503.05591
数据来源
- 原始数据来自PubChem生物测定AID 686978
- 测定名称: "qHTS for Inhibitors of Human Tyrosyl-DNA Phosphodiesterase 1 (TDP1): qHTS in Cells in Absence of CPT"
- 数据链接: https://pubchem.ncbi.nlm.nih.gov/bioassay/686978
数据处理
- 已去除异构体
- 使用RDKit化学信息学工具进行PAINs过滤
- 源代码: https://github.com/articlesmli/IUPAC_ML_model_TDP1/blob/main/IUPAC_ML_model/PAINs_entire_data.ipynb
数据统计
PAINs分析
- PAINs标记样本: 21,761个
- 非PAINs样本: 388,803个
活性分布
应用PAIN过滤前
- 非活性: 236,226个
- 不确定: 112,867个
- 活性: 61,471个
非PAINs样本
- 非活性: 227,158个
- 不确定: 105,950个
- 活性: 55,695个
数据结构
数据集包含5个列:
- CID: PubChem化合物标识符
- SID: PubChem物质标识符
- SMILES: 化学结构表示
- target: 抑制活性标识(1: TDP1抑制剂, 0: 非抑制剂, 2: 不确定)
- PAIN flag: PAINs标记
搜集汇总
数据集介绍
构建方式
在药物发现领域,TDP1_inhibitors_PAIN_flagged数据集的构建源于对高通量筛选数据的系统整理。该数据集源自PubChem生物测定AID 686978,专注于人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的定量高通量筛选。原始数据经过异构体去除处理,并应用了PAIN(泛化筛选干扰化合物)标记策略,但未直接剔除这些样本,从而保留了数据的完整性。通过RDKit化学信息学工具和过滤目录方法,对410,564个样本进行了精确标注,确保了数据在化学和生物学背景下的可靠性。
特点
该数据集在药物化学研究中展现出显著特点,涵盖超过41万条样本,其中21,761条被标记为PAIN化合物,反映了真实筛选环境中干扰物的存在。数据包含五个关键列:PubChem化合物标识符(CID)、物质标识符(SID)、SMILES字符串、TDP1抑制活性标签(活性、非活性或不确定)以及PAIN标记状态。这种多维度结构支持对抑制剂效价的深入分析,同时PAIN标记的保留为研究筛选假阳性提供了独特视角,增强了数据集在机器学习应用中的实用价值。
使用方法
在药物开发应用中,该数据集可通过标准化学信息学流程进行高效利用。用户首先利用RDKit库加载SMILES数据,进行分子结构验证和预处理;随后,基于PAIN标记列可灵活过滤或分析潜在干扰化合物,以优化模型训练。数据集的活性标签支持分类任务,如构建TDP1抑制剂预测模型,同时CID和SID标识符便于与PubChem数据库交叉引用,扩展外部验证。开源代码库提供了完整处理示例,确保研究可重现性,适用于从基础化合物筛选到高级机器学习项目的多种场景。
背景与挑战
背景概述
在药物发现领域,针对特定靶点的高通量筛选技术已成为识别先导化合物的关键手段。TDP1_inhibitors_PAIN_flaged数据集源于2025年发表的跨学科研究,由科研团队基于PubChem生物测定数据库AID 686978构建,专注于人类酪氨酰-DNA磷酸二酯酶1(TDP1)抑制剂的系统性分析。该数据集通过整合化学信息学与机器学习方法,旨在解决抗癌药物研发中DNA修复机制靶向抑制剂的精准识别问题,为优化药物设计流程提供了重要数据支撑。
当前挑战
该数据集核心挑战在于应对药物发现中化合物类药性评估的复杂性:其一,领域问题层面需克服TDP1抑制剂活性预测中生物测定数据的高噪声干扰,以及类药化合物与泛筛选干扰化合物(PAINS)的区分难题;其二,构建过程中面临化学结构异构体去重、多维度生物活性标注一致性校验,以及基于IUPAC命名规则的分子表征转换等技术障碍,这些因素共同制约着数据质量的提升与模型泛化能力的实现。
常用场景
经典使用场景
在药物发现领域,TDP1_inhibitors_PAIN_flagged数据集被广泛用于构建机器学习模型,以识别人类酪氨酰-DNA磷酸二酯酶1(TDP1)的潜在抑制剂。通过结合IUPAC命名法和SMILES表示,该数据集支持化合物活性预测任务,帮助研究人员从高通量筛选数据中筛选出具有生物活性的候选分子,从而加速先导化合物的优化过程。
衍生相关工作
该数据集衍生了多项经典研究,包括基于IUPAC名称的机器学习模型开发,以及针对PAINs过滤方法的优化工作。相关成果发表在药物化学与计算生物学领域,促进了泛筛选干扰化合物识别技术的标准化,并为类似靶点的抑制剂发现提供了可复用的框架。
数据集最近研究
最新研究方向
在药物发现领域,TDP1_inhibitors_PAIN_flaged数据集正推动前沿研究聚焦于利用IUPAC命名与机器学习方法优化抗癌药物开发流程。该数据集通过整合人类酪氨酰-DNA磷酸二酯酶1抑制剂的高通量筛选数据,并结合PAINS过滤机制识别潜在假阳性化合物,为构建更可靠的虚拟筛选模型提供关键支持。当前研究热点涉及开发多任务学习框架以同时预测化合物活性与结构警示,相关成果已应用于提升DNA损伤修复靶向药物的设计效率,显著加速了精准医疗中靶点验证与先导化合物优化的进程。
以上内容由遇见数据集搜集并总结生成


