alwaysgood/Bloomberg_Financial_News_processed
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/alwaysgood/Bloomberg_Financial_News_processed
下载链接
链接失效反馈官方服务:
资源简介:
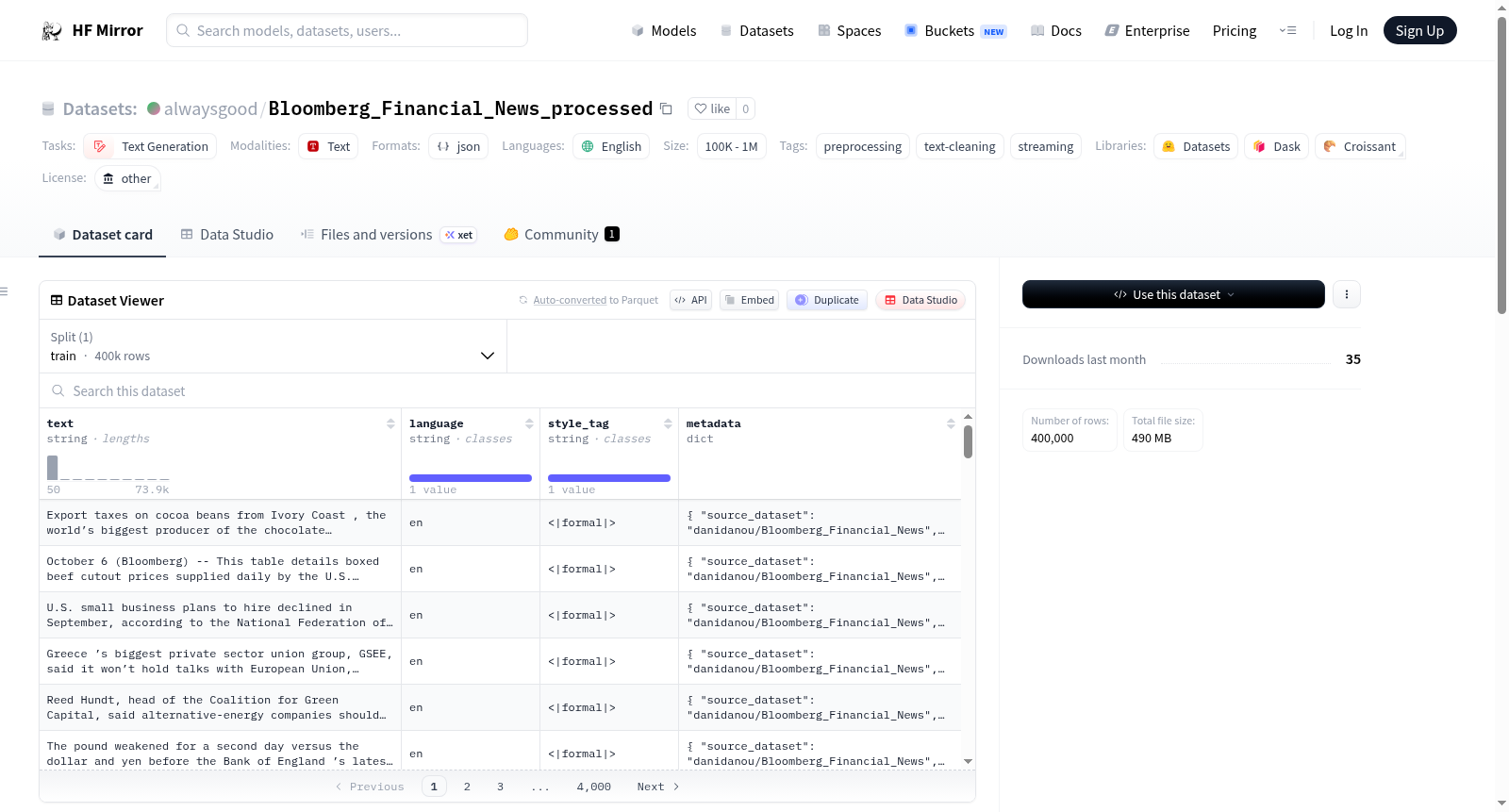
该数据集是经过处理的彭博金融新闻数据集,原始数据来源于`danidanou/Bloomberg_Financial_News`。数据集经过多种文本处理步骤,包括流式处理、文本字段提取、换行符规范化、控制字符移除、空格转换、轻量级乱码恢复、空白规范化等。处理后的数据集包含`text`、`language`、`style_tag`和`metadata`字段,并以`jsonl.gz`格式输出。数据集主要用于文本生成任务,包含446,707条处理后的新闻条目。
This dataset is a processed version of Bloomberg Financial News, originally sourced from `danidanou/Bloomberg_Financial_News`. The dataset has undergone various text processing steps, including streaming, text field extraction, newline normalization, control character removal, space conversion, lightweight mojibake recovery, and whitespace normalization. The processed dataset retains fields such as `text`, `language`, `style_tag`, and `metadata`, and is output in `jsonl.gz` format. The dataset is primarily used for text generation tasks and contains 446,707 processed news entries.
提供机构:
alwaysgood
搜集汇总
数据集介绍
构建方式
本数据集源自于HuggingFace平台上由danidanou维护的Bloomberg_Financial_News原始语料库,聚焦于处理后的金融新闻文本。构建过程以流式方式逐行读取数据,优先提取指定文本字段,并实施多维度的文本清洗策略:包括统一换行符、剔除不可见控制字符及格式字符、将非断行空格转换为普通空格、引入轻量级乱码修复机制以纠正常见的UTF-8与cp1252编码伪影,最终通过空白字符规范化与长度阈值过滤,生成仅保留长度不小于50字符的高质量文本。输出格式为jsonl.gz,每条记录包含text、language、style_tag及metadata四字段。
使用方法
使用者可直接通过HuggingFace datasets库以流式模式加载该数据集,利用其统一的text字段进行下游任务开发。由于数据已高度清洗,无需额外预处理即可用于语言模型的微调或文本生成实验。建议在加载时指定streaming=True以高效处理大规模语料,并根据需要利用language和style_tag字段进行语言或风格的筛选。metadata字段提供了原始数据上下文,便于进行细粒度的数据分析或模型训练的可解释性验证。
背景与挑战
背景概述
Bloomberg_Financial_News_processed数据集由Hugging Face社区维护,基于danidanou发布的原始Bloomberg金融新闻语料库进行精炼处理,于2026年4月完成更新。该数据集聚焦于金融领域的文本生成任务,旨在为自然语言处理模型提供高质量、结构化的金融新闻语料。原始语料包含了超过44万条英文金融新闻条目,覆盖市场动态、公司财报、宏观经济分析等核心主题。经过系统性清洗后,该数据集保留了有效文本,平均每条文本长度约2708字符,为金融文本挖掘、情感分析及生成式语言模型预训练提供了重要的数据基础。作为金融NLP领域的专用语料库,其影响力体现在填补了高质量金融领域开源文本数据的缺口,促进了金融智能助手、投资报告自动生成等应用的发展。
当前挑战
该数据集面临的核心领域挑战在于金融文本的复杂性:新闻中充斥专业术语、市场缩略语、非结构化日期格式及多源字符编码混乱,传统清洗方法难以完全去除乱码(mojibake)和格式噪声,可能损害模型对金融语义的捕获能力。构建过程中遭遇的关键难题包含三点:一是跨行文本的连贯性恢复,因原始数据可能包含不完整句子;二是非打印字符的精准过滤,需平衡保留有用标点与清除控制字符;三是短文本的判别阈值设定,过严会丢失稀缺事件报道,过宽则引入低质噪声。此外,实时流式处理要求高效的checkpoint恢复机制,以避免重复劳动并确保可复现性。
常用场景
经典使用场景
在金融自然语言处理领域,Bloomberg_Financial_News_processed数据集作为经过精密清洗和结构化的财经新闻语料库,经典使用场景集中于金融领域的文本生成与序列建模任务。研究者常利用其高质量、长文本特性,进行金融新闻摘要生成、市场事件时间线重构以及财报电话会议纪要生成等条件式文本生成实验。该数据集保留了原始新闻的元数据字段,使得研究人员能够基于时间戳、风格标签等维度构建具有时序依赖性的预测模型,是金融文本生成基准评估的优质资源。
解决学术问题
该数据集凭借其系统化的文本清理流程,有效解决了金融新闻语料中长期存在的编码混乱、非标准空白字符、异常换行符以及常见乱码伪影(如UTF-8/cp1252编码转换错误)等数据质量问题,为学术研究提供了干净、可复现的训练语料基础。在学术层面,它使研究者得以聚焦于金融语言模型的构建与评估,排除数据噪声对模型性能的干扰,从而更可靠地探索金融文本中蕴含的语义模式、事件关联与市场情绪传递机制,推动金融NLP领域实验标准的提升。
实际应用
在实际应用场景中,该数据集经过流式处理和格式标准化后,可直接接入金融机构的自动化分析管线,服务于智能投资辅助系统、市场舆情监控平台及合规性文本审核工具。例如,量化交易团队可利用其训练金融领域专用语言模型,用于实时新闻驱动的交易信号提取;风控部门则能基于其中标准化后的长文本内容,构建更精准的负面事件检测与公司信用风险预警系统。数据集轻量化的jsonl.gz分片格式便于分布式处理与增量更新,契合金融业务对高效数据管线的需求。
数据集最近研究
最新研究方向
在金融与大语言模型交叉的前沿领域,经清洗与标准化的财经新闻语料正成为构建垂直领域语言模型的核心基石。Bloomberg_Financial_News_processed数据集通过严格的文本净化与异常编码修复,提供了逾44万条高质量、低噪声的金融新闻文本,直接服务于金融领域文本生成、情感分析与事件驱动预测等任务。其精细的预处理流程显著降低了模型训练中的数据污染风险,为量化投资决策与市场异动预警等热点应用提供了可靠的数据支撑,正推动金融NLP研究从通用文本向专业领域深入迈进。
以上内容由遇见数据集搜集并总结生成


