AgentPublic/travail-emploi
收藏Hugging Face2026-05-08 更新2025-05-31 收录
下载链接:
https://hf-mirror.com/datasets/AgentPublic/travail-emploi
下载链接
链接失效反馈官方服务:
资源简介:
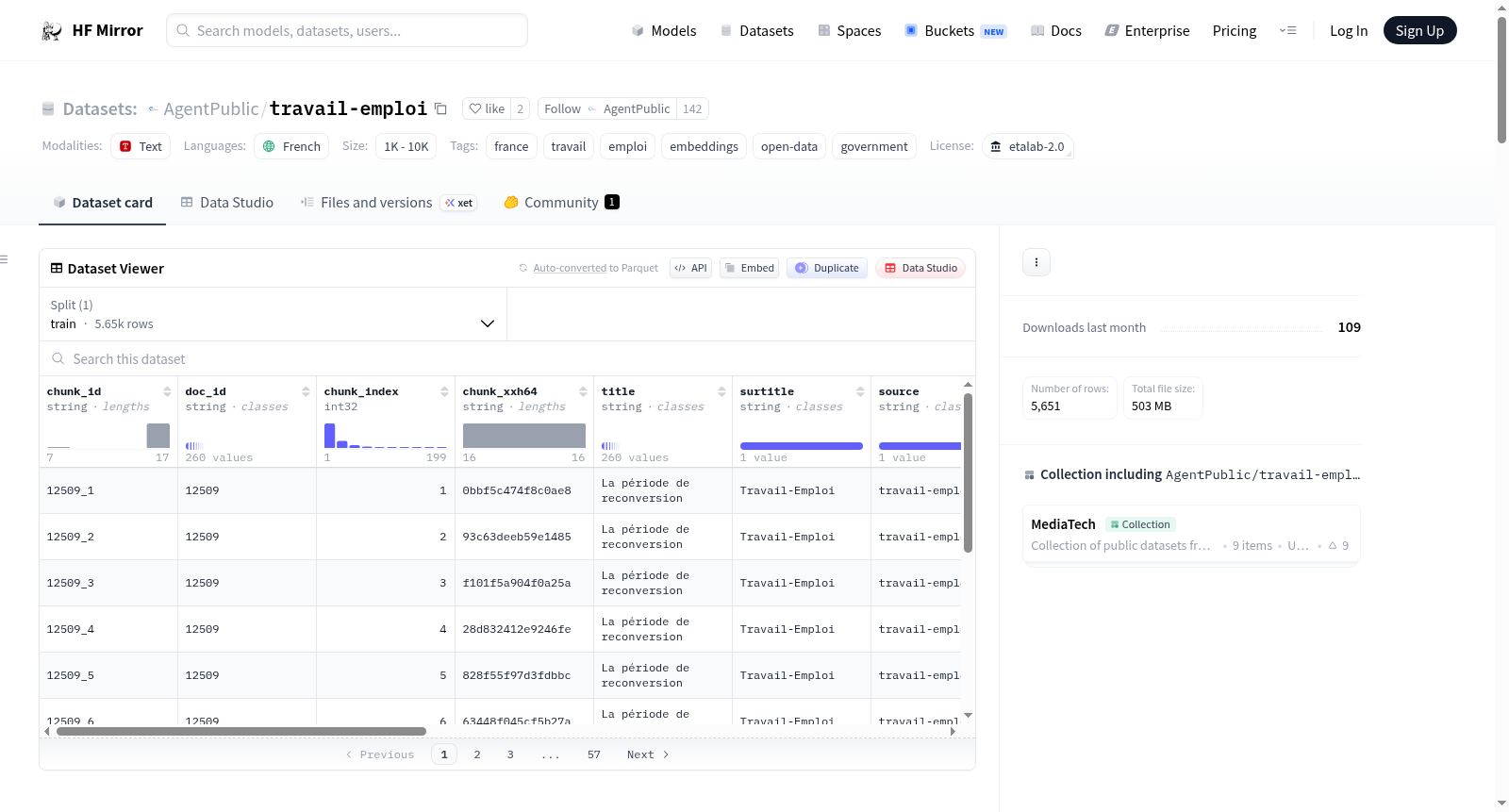
法国劳动与就业部官方网站数据集(Travail Emploi),包含了从官方网站提取的关于就业、劳动法和行政程序的官方实用信息表的经过处理和嵌入的版本。数据集以Parquet格式提供,包含了标题、简介、发布日期、原始文章URL、上下文、文本内容以及使用BAAI/bge-m3模型生成的嵌入向量。
The French Minister of Labor and Employments website Dataset (Travail Emploi) includes a processed and embedded version of public practical information sheets extracted from the official website related to employment, labor law, and administrative procedures. The dataset is provided in Parquet format and includes title, introduction, publication date, original article URL, context, text content, and embedding vectors generated using the BAAI/bge-m3 model.
提供机构:
AgentPublic
搜集汇总
数据集介绍
构建方式
该数据集源自法国劳动与就业部官方网站(travail-emploi.gouv.fr)的公开实用信息表,原始数据从政府Social Gouv GitHub仓库获取。构建过程中,首先从JSON文件中提取基本字段如标题、介绍、日期和URL,同时生成唯一哈希标识块及其索引。针对文本内容,采用Langchain的RecursiveCharacterTextSplitter工具,基于BAAI/bge-m3分词器,以1024字符为块大小且无重叠的方式进行语义切分,形成连贯的文本片段。随后,利用BAAI/bge-m3嵌入模型对每个文本块进行向量化,生成嵌入向量并以JSON数组字符串形式存储,从而构建一个语义就绪的结构化数据集。
使用方法
用户可通过HuggingFace的datasets库加载数据集,并利用pandas将嵌入向量从JSON字符串解析为列表或NumPy数组,以便集成至向量数据库或RAG流水线。若默认分块策略不适用,可参考官方GitHub教程将数据重组为原始未分块形态。此外,官方提供了从HuggingFace加载数据集并构建检索增强生成管道的逐步指南。加载时需确保安装PyArrow库,使用load_dataset或pd.read_parquet读取Parquet文件,再通过json.loads转换嵌入列,灵活应用于语义搜索、问答系统等下游任务。
背景与挑战
背景概述
该数据集由法国数字事务局(Etalab)与MediaTech项目团队于2024年创建,旨在将法国劳动与就业部官方网站(travail-emploi.gouv.fr)上的公开实用信息页转化为结构化的语义向量数据。核心研究问题聚焦于如何通过自然语言处理技术,提升政府行政程序信息的可检索性与可访问性,为公民提供更高效的劳动法与就业政策查询服务。作为开放数据运动与公共服务数字化的重要成果,该数据集为检索增强生成(RAG)流水线提供了高质量的领域语料,推动了法语行政文本的语义搜索与智能问答系统的发展。
当前挑战
该数据集面临的挑战首先生于领域层面:法国劳动与就业法规体系庞杂,官方文本涉及大量法律术语、嵌套条款及程序性描述,语义粒度难以统一,现有的切片策略可能破坏语境连贯性,影响检索精度。构建过程中亦遭遇技术难题:原始JSON数据字段异构(如sid与pubID的映射),需设计鲁棒的字段提取与清洗流程;基于BAAI/bge-m3模型的嵌入生成虽提升了语义表征,但无重叠切片(chunk_size=1024)可能导致跨片段信息遗漏,同时嵌入向量的存储与解析(字符串化列表)增加了下游使用的计算开销。
常用场景
经典使用场景
在法国劳动与就业政策研究领域,travail-emploi数据集作为官方发布的语义增强型知识库,主要用于构建基于检索增强生成(RAG)架构的智能问答系统。研究人员通过调用其中经BAAI/bge-m3模型向量化的文本块,能够高效实现劳动法规、行政程序等专业信息的语义检索。该数据集天然适配于需要精准理解法语劳动法条文的场景,例如为劳动者提供个性化劳动合同条款解析、为雇主生成合规性检查清单,或为法律从业者快速定位判例中的关键程序节点。其结构化字段(如chunk_text与embeddings_bge-m3)的协同设计,使得跨文档的知识联结与上下文感知推理成为可能,显著降低了传统关键词匹配带来的信息碎片化问题。
解决学术问题
该数据集系统性地回应了法国公共信息数字化进程中两大核心学术挑战:如何将非结构化政务文本转化为机器可理解的语义单元,以及如何保障开放数据在复杂法律检索中的可迁移性。通过引入递归字符切分与多语言嵌入技术,研究界首次获得了覆盖法国劳动法典十二条目的标准化工件,有效缓解了以往研究因数据来源分散导致的结论偏差问题。基于此数据集,学者得以量化分析行政文件中的信息密度分布特征,验证法律条款与实务指南之间的语义对齐程度,并构建起从规章文本到市民理解的全链路认知模型。这些进展为欧盟数字服务法案下的政务AI合规性评估提供了方法论参考,也推动了自然语言处理技术在法规解释性这一交叉领域的理论深化。
实际应用
该数据集已在法国公共数字服务生态中落地多项实质性应用,最典型的是集成至政务问答引擎Albert的底层知识库,支撑公民就裁员补偿计算、学徒合同续签等高频问题获取即时且权威的文本级回复。初创企业利用其嵌入向量库开发劳动法合规审计工具,可自动比对《劳动法典》条款与企业内部政策文本,实时标记15类常见合规缺口。教育机构则将其作为法语法律术语教学资源,通过语义相似度计算辅助留学生理解“licenciement économique”与“rupture conventionnelle”等概念间的层级关系。此外,地方政府部门在修订地方就业条例时,常借助该数据集进行跨辖区的法规差异分析,以提升政策制定的协调性。
数据集最近研究
最新研究方向
该数据集聚焦于法国劳动与就业领域官方信息的语义化处理与向量化检索,代表了公共数据开放与自然语言处理交叉领域的前沿方向。通过采用BAAI/bge-m3嵌入模型对结构化文本进行分块与向量化,travail-emploi数据集为检索增强生成(RAG)流水线提供了高质量的知识基底。在法国政府推动数字政务透明化与智能化的背景下,该数据集不仅服务于行政程序语义搜索的落地应用,还推动了开源公共数据在求职、劳动法规咨询等热点场景中的高效利用。其方法论上的分块策略与嵌入向量存储设计,为构建可复现的政务问答系统及知识图谱奠定了重要基础,对促进政府数据资产的可发现性与可计算性具有深远意义。
以上内容由遇见数据集搜集并总结生成


