oasst2-es-3k-topics
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/thinkPy/oasst2-es-3k-topics
下载链接
链接失效反馈官方服务:
资源简介:
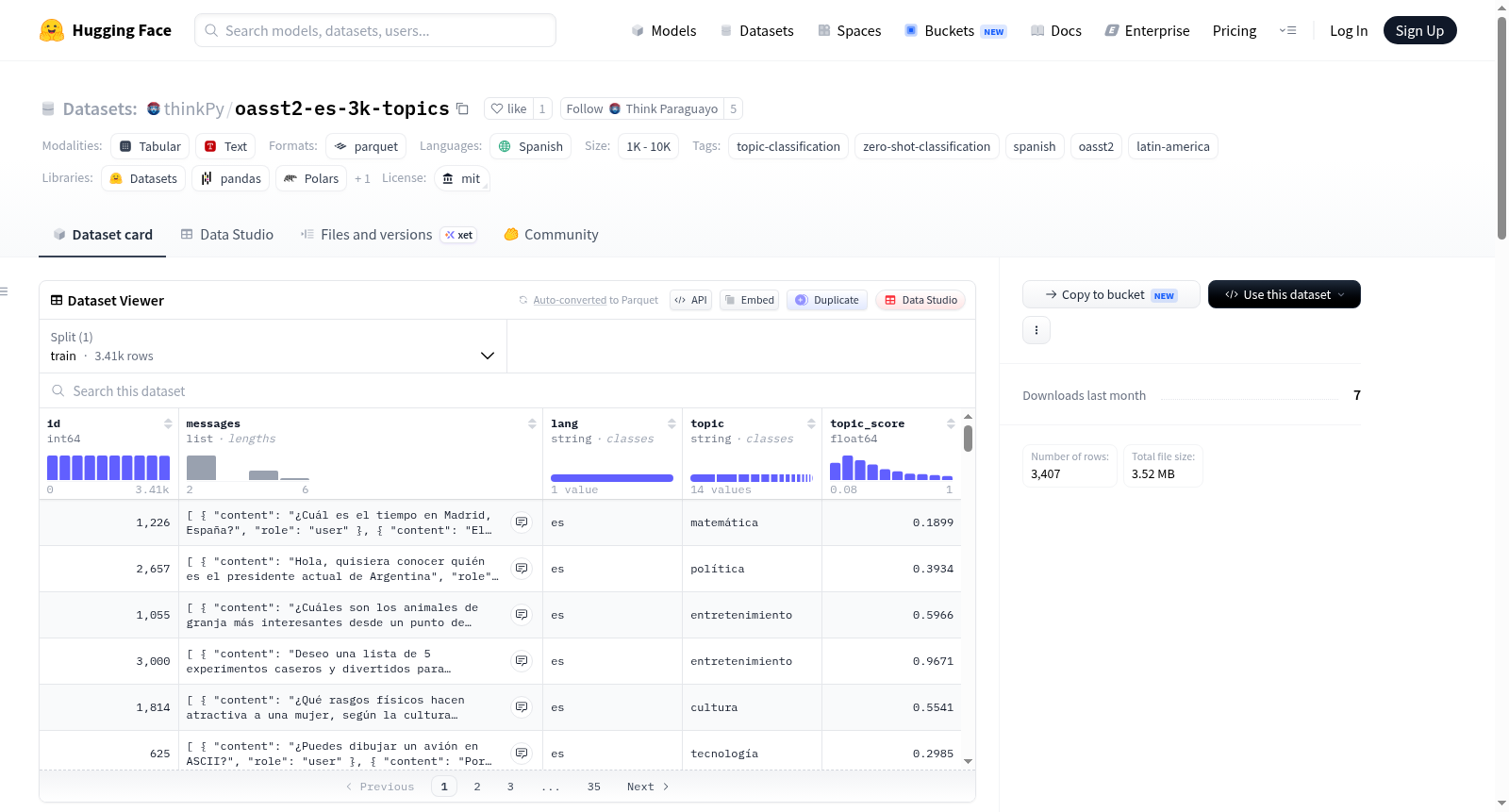
oasst2-short-es-topics 是一个西班牙语短对话数据集,其特点是包含了自动生成的主题分类标签。该数据集源自 thinkPy/oasst2-short-es(一个基于 OpenAssistant/oasst2 的西班牙语短对话数据集),通过对原始数据进行随机抽样(种子为42)并新增两个主题分类字段而构建。主题分类任务是通过零样本分类(自然语言推理)技术完成的,具体使用了 MoritzLaurer/mDeBERTa-v3-base-mnli-xnli 模型对对话中用户的第一条消息(截断至256个字符)进行分析。数据集共定义了14个涵盖广泛领域的主题,包括:技术、数学、科学、人文、历史、文化、政治、经济、健康、教育、社会、环境、娱乐和体育。每个数据样本包含以下字段:唯一标识符(id)、由用户和助手角色消息组成的对话列表(messages)、语言代码(lang,固定为‘es’)、预测的主题标签(topic)以及该预测的置信度分数(topic_score)。数据集规模为3,407个训练样本。该数据集主要适用于西班牙语的主题分类和零样本分类任务的研究与评估。需要注意的是,所有主题标签均为模型自动生成,可能存在错误,对于置信度分数较低的样本应谨慎使用。
oasst2-short-es-topics is a Spanish short dialogue dataset characterized by automatically generated topic classification labels. It originates from thinkPy/oasst2-short-es (a Spanish short dialogue dataset based on OpenAssistant/oasst2), constructed by randomly sampling the original data (with a seed of 42) and adding two topic classification fields. The topic classification task is completed through zero-shot classification (natural language inference) technology, specifically using the MoritzLaurer/mDeBERTa-v3-base-mnli-xnli model to analyze the users first message in the dialogue (truncated to 256 characters). The dataset defines 14 topics covering a wide range of fields, including: technology, mathematics, science, humanities, history, culture, politics, economics, health, education, society, environment, entertainment, and sports. Each data sample includes the following fields: unique identifier (id), a list of dialogues composed of user and assistant role messages (messages), language code (lang, fixed as es), predicted topic label (topic), and the confidence score of that prediction (topic_score). The dataset size is 3,407 training samples. This dataset is primarily suitable for research and evaluation of Spanish topic classification and zero-shot classification tasks. It should be noted that all topic labels are automatically generated by the model and may contain errors; samples with low confidence scores should be used with caution.
创建时间:
2026-05-31
原始信息汇总
数据集概述:oasst2-es-3k-topics
该数据集提供约 3407 条西班牙语短对话,并附带自动标注的主题分类信息。
基本信息
- 语言: 西班牙语 (es)
- 许可证: MIT
- 数据集大小: 1K < n < 10K
- 来源数据集: thinkPy/oasst2-short-es (基于 OpenAssistant/oasst2 的西班牙语短对话版本)
数据特征
每条样本包含以下字段:
id(int64): 样本唯一标识符messages(list): 对话消息列表,包含角色 (role: user/assistant) 和内容 (content: string)lang(string): 语言,固定为 "es"topic(string): 自动分类的主题标签topic_score(float64): 主题分类的置信度分数
数据集划分
- 训练集 (train): 3407 条样本,大小约 6.57 MB
主题分类
使用零样本分类模型 MoritzLaurer/mDeBERTa-v3-base-mnli-xnli 对用户的第一条消息(截断至 256 字符)进行分类。共包含 14 个主题:
| 主题 | 描述 |
|---|---|
| tecnología | 编程、软件、硬件、人工智能 |
| matemática | 代数、统计学、微积分 |
| ciencia | 物理、化学、生物学、研究 |
| humanidades | 哲学、语言学、文学 |
| historia | 历史事件与人物 |
| cultura | 传统、艺术、音乐、美食 |
| política | 政府、国际关系 |
| economía | 金融、市场、创业 |
| salud | 医学、健康、营养 |
| educación | 教育学、学习、学术 |
| sociedad | 人际关系、伦理、日常生活 |
| medio ambiente | 生态、气候变化、自然 |
| entretenimiento | 电影、电子游戏、旅行 |
| deportes | 竞赛、体育项目、体育活动 |
数据样例 (JSON 格式)
json { "id": "0", "messages": [ {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."} ], "lang": "es", "topic": "cultura", "topic_score": 0.7231 }
使用方法(Python)
python from datasets import load_dataset
ds = load_dataset("thinkPy/oasst2-short-es-topics", split="train")
按主题筛选
ds_cultura = ds.filter(lambda x: x["topic"] == "cultura")
按置信度筛选
ds_alta_confianza = ds.filter(lambda x: x["topic_score"] >= 0.5)
注意事项
- 主题分类为自动生成,可能包含错误,尤其是对于内容模糊或过短的文本。
- 置信度较低的样本 (
topic_score较低) 应谨慎使用。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,主题分类任务是理解对话语料语义内涵的关键环节。oasst2-es-3k-topics数据集源自thinkPy/oasst2-short-es,后者则是对OpenAssistant/oasst2中西班牙语短对话的精炼提取。为赋予每条对话一个主题标签,研究者采用零样本分类技术,利用MoritzLaurer/mDeBERTa-v3-base-mnli-xnli模型对用户首条消息进行推理,文本截断至256字符,从而自动化生成涵盖科技、数学、人文等十四个主题类别的标注信息,并附有置信度评分以表征分类可靠性。
特点
该数据集最引人注目的特质在于其多维度信息融合的结构。每条样本不仅包含完整的用户与助手对话内容及语言标识,还额外携带了主题标签与对应的分类置信度分数,使得研究者能够依据置信度阈值灵活筛选高质量子集。主题覆盖范围广泛且具有清晰的定义描述,从技术领域到日常生活场景,为西班牙语对话系统的主题检测、意图识别等任务提供了坚实的监督信号。数据集包含3407条训练样本,规模适中,既保证了统计意义,又便于快速迭代实验。
使用方法
借助Hugging Face的datasets库,用户可轻松加载该数据集并开展下游任务。通过load_dataset函数指定拆分即可获取完整训练集,随后可利用filter方法按主题字段筛选特定领域样本,例如仅保留文化类对话;亦可依据topic_score字段设置置信度阈值,保留高可靠性条目以提升模型训练质量。此外,数据集的schema清晰定义了id、messages、lang、topic及topic_score等字段,便于与现有数据处理管线无缝集成,适用于西班牙语文本分类、对话理解及零样本学习等研究场景。
背景与挑战
背景概述
在自然语言处理领域,多语言对话系统的主题分类是理解和组织用户意图的重要任务。oasst2-es-3k-topics数据集由thinkPy团队于2023年创建,基于OpenAssistant的oasst2西班牙语对话子集,针对短对话进行主题标注。该数据集聚焦于零样本主题分类问题,通过引入mDeBERTa-v3模型自动生成14个预定义主题的标签,涵盖技术、数学、科学、人文、历史、文化、政治、经济、健康、教育、社会、环境、娱乐和体育等领域。它为西班牙语对话的主题建模提供了标准化的基准资源,尤其适用于拉丁美洲地区的语言处理研究,推动了零样本分类方法在低资源语言中的应用。
当前挑战
该数据集面临的核心挑战包括:领域问题层面,对话主题分类需处理西班牙语中词汇歧义、语境依赖及口语化表达带来的语义理解困难,尤其是零样本场景下模型对未见主题的泛化能力不足;构建过程层面,自动标注依赖的mDeBERTa-v3模型在文本截断至256字符时可能丢失关键上下文信息,导致主题误判,且短对话中缺乏足够线索进一步加剧了分类不确定性。此外,主题分类的置信度评分(topic_score)未能完全反映错误标签的风险,尤其在低分数样本中需人工校验,而数据集规模仅3407条样本也限制了其作为训练集的可靠性。
常用场景
经典使用场景
oasst2-es-3k-topics数据集汇聚了西班牙语短对话,并借助零样本分类技术为每条对话标注了涵盖科技、数学、科学、人文等十四类主题。这一精细化的主题标签设计,使其成为训练和评估西班牙语对话系统主题理解能力的理想资源。研究者可基于该数据集进行多类别文本分类模型的微调,或将其作为基准数据,检验模型在低资源语言场景下识别用户意图的准确性。此外,通过筛选高置信度样本,该数据集还支持构建主题导向的检索或生成式对话系统,为跨语言自然语言处理研究提供了坚实的实验基础。
解决学术问题
该数据集直面西班牙语对话语料匮乏、主题标注成本高昂的学术困境。传统主题分类研究多集中于英语,而西班牙语尤其是拉美地区变体的对话数据缺乏系统化的主题标注。oasst2-es-3k-topics通过自动零样本分类方法,以较低成本实现了大规模主题标注,解决了小样本场景下西班牙语对话主题识别的研究难题。其公开的置信度分数也支撑了关于分类不确定性建模的探索,推动了鲁棒性更强的主题分类方法在资源稀缺语言中的发展。这不仅丰富了多语言对话理解的理论体系,也为比较不同语言间主题分布差异提供了量化依据。
衍生相关工作
该数据集衍生了一系列推动西班牙语自然语言处理发展的经典工作。其中,基于其主题标签的研究包括探索零样本分类模型在不同置信度阈值下对下游任务性能的影响,以及利用主题信息增强对话状态追踪的多任务学习框架。也有学者将其与原始oasst2数据集结合,开展跨语言主题一致性分析,揭示西班牙语对话中的文化特异性话题。此外,该数据集还被用作少样本提示学习(prompt learning)的评测基准,验证预训练语言模型在西班牙语主题任务中的泛化能力。这些衍生工作不仅拓展了数据集的应用边界,也深化了学界对低资源语言对话理解机理的认知。
以上内容由遇见数据集搜集并总结生成


