VADB
收藏arXiv2025-10-29 更新2025-10-31 收录
下载链接:
https://github.com/BestiVictory/VADB
下载链接
链接失效反馈官方服务:
资源简介:
VADB是一个大规模的视频美学数据库,包含10,490个多样化的视频,由37位专业人士在多个美学维度上进行标注,包括整体和特定属性的美学评分、丰富的语言评论和客观标签。VADB旨在解决视频美学评估领域的挑战,提供了一种新的视频美学评估模型VADB-Net,该模型基于多模态CLIP框架,在评分任务中优于现有的视频质量评估模型,并支持下游的视频美学评估任务。
VADB is a large-scale video aesthetics database, containing 10,490 diverse videos annotated by 37 professionals across multiple aesthetic dimensions. The annotations cover overall and attribute-specific aesthetic scores, extensive linguistic comments, and objective tags. VADB aims to address the challenges in the field of video aesthetic assessment, and proposes a novel video aesthetic assessment model VADB-Net based on the multimodal CLIP framework. This model outperforms existing video quality assessment models in the scoring task and supports downstream video aesthetic assessment tasks.
提供机构:
北京电子科技学院, 南京大学, 华中科技大学, 北京电影学院, 中国科学技术大学, 中国科学院自动化研究所, 北京通用人工智能研究院
创建时间:
2025-10-29
原始信息汇总
VADB数据集概述
数据集基本信息
- 数据集名称:VADB(Video Aesthetics Database)
- 数据集类型:大规模视频美学数据库
- 数据规模:包含7,881个视频
- 数据内容:涵盖多样化视频风格和内容类别
数据集内容特性
- 详细语言评论:每个视频均附带语言描述
- 多维度美学评分:包含7-11个维度的美学评分
- 丰富客观标签:标注视频拍摄技术和其他客观维度
- 美学属性覆盖:全面覆盖视频美学属性特征
数据集获取与许可
- 公开地址:https://huggingface.co/datasets/BestiVictoryLab/VADB
- 数据集许可:CC BY-NC 4.0(禁止商业使用)
- 代码模型许可:CC BY 4.0
配套评估框架
- 框架名称:VADB-Net
- 功能描述:新颖的视频美学评分框架
评估模型组件
1. 整体美学评分
- 模型位置:1TotalScore文件夹
- 功能:预测视频整体美学分数
2. 通用属性评分
- 模型位置:2GeneralAttribute文件夹
- 评估维度:
- 构图
- 镜头尺寸
- 照明
- 视觉色调
- 色彩
- 景深
3. 人物中心属性评分
- 模型位置:3HumanAttribute文件夹
- 评估维度:
- 表情
- 动作
- 服装
- 妆容
预训练模型
- 视频编码器:https://drive.google.com/file/d/1hCSY1jY-tvXJSgYyyi0M60mcoobgkIGH/view?usp=drive_link
- 功能:从视频中提取美学特征向量,作为所有评分模型的基础组件
搜集汇总
数据集介绍
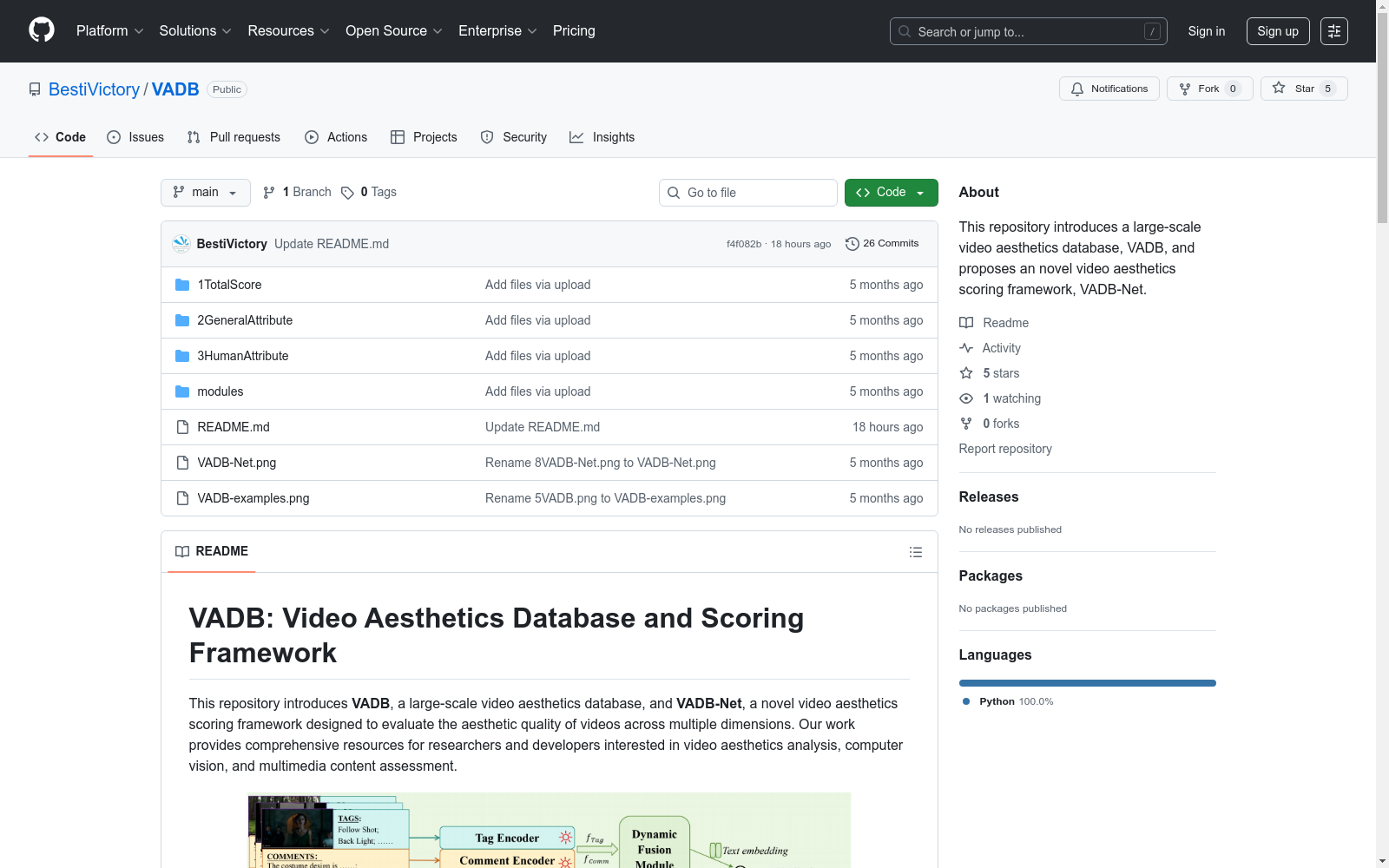
构建方式
在视频美学评估领域,VADB数据集的构建体现了系统化工程思维。研究团队与北京电影学院合作组建了37人专业标注团队,所有成员均具备三年以上影视艺术鉴赏经验。标注流程采用多维度协同标注机制,每个视频由至少13名标注者独立完成整体美学评分、10项属性评分、语言评论和技术标签标注。通过自建标注平台实现任务动态分配,采用克里彭多夫Alpha系数进行一致性验证,最终从13,000个初始样本中筛选出10,490个高质量样本,确保了数据的可靠性与专业性。
特点
VADB数据集在规模与标注深度上具有显著优势。其核心特征体现在多维标注体系:除整体美学评分外,还包含构图、景别、光影等10个专业属性评分,每个视频平均配备22条语言评论和7个客观技术标签。数据集涵盖人物、自然风光、建筑与美食四大视频类别,其中人物类视频达8,130段,充分体现了以人物为中心的美学评估特性。视频时长控制在5-20秒之间,既保证了内容完整性又兼顾处理效率,其标注一致性系数介于0.54-0.66之间,符合美学评估的主观特性。
使用方法
该数据集支持多层次的研究应用。在基础层面,研究者可利用10,490个视频的完整标注数据开发视频美学质量评估模型。进阶应用中,多维属性评分为细粒度美学分析提供支撑,语言评论与技术标签则适用于多模态学习任务。特别设计的VADB-Net框架展示了典型使用范式:通过预训练阶段学习视频-文本对齐表示,再经微调阶段实现美学评分预测。数据集的80%公开版本便于学术研究,剩余20%受保护内容确保了版权合规,为视频美学计算提供了标准化基准。
背景与挑战
背景概述
随着短视频平台的迅猛发展和生成式人工智能技术的突破,互联网视频数据呈现爆炸式增长,用户对视频内容的审美需求日益提升,推动了视频美学评估成为多媒体计算领域的关键研究方向。在此背景下,VADB数据集于2025年由南京大学、北京电子科技学院等机构联合发布,作为当前规模最大的视频美学数据库,包含10,490个多样化视频片段,由37位专业标注者从构图、光影、色彩等11个维度进行系统标注。该数据集通过融合电影美学理论与计算视觉方法,建立了首个结合定量评分与语义描述的多模态标注体系,为视频美学研究提供了标准化数据基础,显著促进了跨媒体内容质量评估的发展。
当前挑战
视频美学评估领域长期面临动态时空特征建模与多模态融合的复杂性挑战,传统图像美学方法难以直接迁移至视频场景。VADB数据集构建过程中需克服标注一致性与专业性的平衡难题:在解决视频美学质量量化问题时,需协调不同文化背景标注者的主观差异,其标注一致性系数介于0.54-0.66间;在数据采集环节,需处理从专业影视作品到用户生成内容的巨大质量跨度,同时通过多层质量控制机制确保10,490个有效样本的标注可靠性。此外,模型开发需应对时空特征提取与多维度美学属性联合建模的技术瓶颈,这对深度学习架构设计提出了更高要求。
常用场景
经典使用场景
在多媒体计算领域,视频美学评估作为连接计算机视觉与人类认知的重要桥梁,其研究进展常受限于标准化数据集的匮乏。VADB数据集凭借其大规模视频样本与专业多维标注,为视频美学质量评估模型的训练与验证提供了理想基准。该数据集通过涵盖人物、自然风光、建筑与美食等多元场景,支持研究者系统分析视频在构图、光影、色彩等维度的美学特性,成为开发先进评估算法的核心资源。
衍生相关工作
基于VADB数据集构建的VADB-Net模型开创了双模态预训练框架在视频美学评估中的应用先河,其通过融合视觉序列特征与语言注释的对比学习策略,显著提升了评分预测精度。该工作进一步启发了跨模态美学分析的新方向,例如结合CLIP架构的语义理解能力拓展至视频情感计算、风格迁移质量评估等衍生任务。相关技术路径为后续研究提供了可复现的基准模型,推动了视频美学计算范式的迭代升级。
数据集最近研究
最新研究方向
随着短视频平台与生成式AI技术的飞速发展,视频美学评估已成为多媒体计算领域的前沿课题。VADB作为当前规模最大、标注维度最全面的视频美学数据库,其多维度评分体系与专业注释为视频美学研究提供了标准化基础。该数据集推动了基于CLIP架构的多模态预训练模型在视频美学质量评估中的应用,通过融合视觉特征与语言注释,显著提升了美学评分的准确性。相关研究正聚焦于跨文化美学差异的建模、AIGC生成视频的质量评估,以及动态时空特征与美学属性的关联分析,这些方向不仅拓展了视频美学在工业化影视制作与内容平台优化中的实践价值,也为构建更普适、可解释的美学评估框架奠定了理论基础。
相关研究论文
- 1VADB: A Large-Scale Video Aesthetic Database with Professional and Multi-Dimensional Annotations北京电子科技学院, 南京大学, 华中科技大学, 北京电影学院, 中国科学技术大学, 中国科学院自动化研究所, 北京通用人工智能研究院 · 2025年
以上内容由遇见数据集搜集并总结生成


