llamaindex/ParseBench
收藏Hugging Face2026-04-19 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/llamaindex/ParseBench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
configs:
- config_name: parse-bench
features:
- name: pdf
dtype: string
- name: category
dtype: string
- name: id
dtype: string
- name: type
dtype: string
- name: rule
dtype: string
- name: page
dtype: int64
- name: expected_markdown
dtype: string
- name: tags
sequence: string
data_files:
- split: chart
path: chart.jsonl
- split: layout
path: layout.jsonl
- split: table
path: table.jsonl
- split: text_content
path: text_content.jsonl
- split: text_formatting
path: text_formatting.jsonl
language:
- en
pretty_name: ParseBench
size_categories:
- 100K<n<1M
tags:
- document-parsing
- pdf
- benchmark
- evaluation
- tables
- charts
- ocr
- layout-detection
citation: |
@misc{zhang2026parsebench,
title={ParseBench: A Document Parsing Benchmark for AI Agents},
author={Boyang Zhang and Sebastián G. Acosta and Preston Carlson and Sacha Bron and Pierre-Loïc Doulcet and Simon Suo},
year={2026},
eprint={2604.08538},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.08538},
}
---
# ParseBench

**Quick links:** [\[🌐 Website\]](https://parsebench.ai) [\[📜 Paper\]](https://arxiv.org/abs/2604.08538) [\[💻 Code\]](https://github.com/run-llama/ParseBench)
**ParseBench** is a benchmark for evaluating document parsing systems on real-world enterprise documents, with the following characteristics:
- **Multi-dimensional evaluation.** The benchmark is stratified into five capability dimensions — tables, charts, content faithfulness, semantic formatting, and visual grounding — each with task-specific metrics designed to capture what agentic workflows depend on.
- **Real-world enterprise documents.** The evaluation set contains ~2,000 human-verified pages from over 1,200 publicly available documents spanning insurance, finance, government, and other domains, ranging from straightforward to adversarially hard.
- **Dense test coverage.** Over 169K test rules across the five dimensions, providing fine-grained diagnostic power over precisely where a parser breaks down.
- **Human-verified annotations.** All annotations are produced through a two-pass pipeline: frontier VLM auto-labeling followed by targeted human correction.
- **Evaluation code suite.** The benchmark ships with a full evaluation framework supporting end-to-end pipeline evaluation, per-dimension scoring, and cross-pipeline comparison. The evaluation code can be found at [ParseBench](https://github.com/run-llama/ParseBench).
## Dataset Introduction
ParseBench comprises ~2,000 human-verified, annotated pages drawn from publicly available enterprise documents spanning insurance, finance, government, and other domains. The benchmark is stratified into five capability dimensions, each targeting a failure mode that consistently breaks production agentic workflows:
- **Tables.** Structural fidelity of merged cells and hierarchical headers. A single shifted header or merged-cell error causes an agent to extract values from the wrong column, silently corrupting financial analysis.
- **Charts.** Exact data point extraction with correct labels from bar, line, pie, and compound charts. Agents need precise numerical values rather than natural-language descriptions.
- **Content Faithfulness.** Omissions, hallucinations, and reading-order violations. Dropped or fabricated content means the agent acts on wrong context.
- **Semantic Formatting.** Preservation of inline formatting that carries meaning: strikethrough (marks superseded content), superscript/subscript (footnote references, chemical formulae), bold (defined terms, key values), titles, LaTeX, and code blocks.
- **Visual Grounding.** Tracing every extracted element back to its precise source location on the page. Required for auditability in regulated workflows.
| Dimension | Metric | Pages | Docs | Rules |
|-----------|--------|------:|-----:|------:|
| Tables | GTRM (GriTS + TableRecordMatch) | 503 | 284 | --- |
| Charts | ChartDataPointMatch | 568 | 99 | 4,864 |
| Content Faithfulness | Content Faithfulness Score | 506 | 506 | 141,322 |
| Semantic Formatting | Semantic Formatting Score | 476 | 476 | 5,997 |
| Layout (Visual Grounding) | Element Pass Rate | 500 | 321 | 16,325 |
| **Total (unique)** | | **2,078** | **1,211** | **169,011** |
Content Faithfulness and Semantic Formatting share the same 507 underlying text documents, evaluated with different rule sets. Totals reflect unique pages and documents. Tables uses a continuous metric (no discrete rules).
## Usage
You can use our [evaluation framework](https://github.com/run-llama/ParseBench) to run evaluations across the five dimensions:
- **Tables** — GTRM (average of GriTS and TableRecordMatch): GriTS measures structural similarity; TableRecordMatch treats tables as bags of records and scores structural fidelity
- **Charts** — ChartDataPointMatch: verifies annotated data points against the parser's table output
- **Content Faithfulness** — Rule-based detection of omissions, hallucinations, and reading-order violations at word, sentence, and digit granularities
- **Semantic Formatting** — Verification of formatting preservation (bold, strikethrough, superscript/subscript, titles, LaTeX, code blocks)
- **Visual Grounding** — Joint evaluation of localization (IoA), classification, and attribution
The evaluation dataset files include:
- [chart.jsonl](chart.jsonl) — 4,864 chart data point spot-check rules across 568 pages
- [table.jsonl](table.jsonl) — 503 ground-truth HTML tables for structural evaluation
- [text_content.jsonl](text_content.jsonl) — 141,322 content faithfulness rules (omission, hallucination, reading order) across 506 pages
- [text_formatting.jsonl](text_formatting.jsonl) — 5,997 formatting preservation rules across 476 pages
- [layout.jsonl](layout.jsonl) — 16,325 layout element and reading order rules across 500 pages
- [docs/](https://huggingface.co/datasets/llamaindex/ParseBench/tree/main/docs) — Source documents (PDF, JPG, PNG) organized by category
<details>
<summary>Dataset Format</summary>
The dataset format is JSONL, with one line per test rule. The structure and field explanations:
```json
{
"pdf": "docs/chart/report_p41.pdf", // Relative path to the source document (PDF, JPG, or PNG)
"category": "chart", // Evaluation category
"id": "unique_rule_id", // Unique identifier for this test rule
"type": "chart_data_point", // Rule type (see below)
"rule": "{...}", // JSON-encoded rule payload with evaluation parameters
"page": null, // Page number (1-indexed), used by layout rules
"expected_markdown": null, // Ground-truth HTML/markdown, used by table rules
"tags": ["need_estimate"] // Document-level tags for filtering and grouping
}
```
**Tags by category:**
- **chart**: `need_estimate` (value requires visual estimation), `3d_chart` (3D chart rendering)
- **table**: difficulty (`easy`, `hard`)
- **text_content / text_formatting**: difficulty (`easy`, `hard`) and document type (`dense`, `sparse`, `simple`, `multicolumns`, `ocr`, `multilang`, `misc`, `handwritting`)
- **layout**: difficulty (`easy`, `hard`)
**Rule types by category:**
- **chart**: `chart_data_point` — a spot-check data point specifying a numerical value and one or more labels (series name, x-axis category) that should be locatable in the parser's table output, with a configurable tolerance.
- **table**: `expected_markdown` — ground-truth HTML table structure. Evaluation treats tables as bags of records (rows keyed by column headers).
- **layout**: `layout` (bounding box + semantic class + content + reading order index), `order` (pairwise reading order assertion).
- **text_content**: `missing_word_percent`, `unexpected_word_percent`, `too_many_word_occurence_percent`, `missing_sentence_percent`, `unexpected_sentence_percent`, `too_many_sentence_occurence_percent`, `bag_of_digit_percent`, `order`, `missing_specific_word`, `missing_specific_sentence`, `is_footer`, `is_header`
- **text_formatting**: `is_bold`, `is_italic`, `is_underline`, `is_strikeout`, `is_mark`, `is_sup`, `is_sub`, `is_title`, `title_hierarchy_percent`, `is_latex`, `is_code_block`
</details>
<details>
<summary>Evaluation Categories</summary>
**Chart** rule type — `chart_data_point`:
Each rule specifies an expected numerical value and one or more labels (series name, x-axis category, chart title). A data point is verified if its value and all associated labels can be located in the parser's table output. Evaluation is insensitive to table orientation (rows and columns can be swapped) and tolerant of numeric formatting differences (currency symbols, unit suffixes, thousands separators). Each data point includes a configurable tolerance since exact value retrieval from charts is often imprecise.
```
chart_data_point # Spot-check data point: value + labels matched against parser's table output
# Rule fields: labels (list), value (string), max_diffs (int), normalize_numbers (bool)
```
**Table** — `expected_markdown`:
Each rule provides a ground-truth HTML table. Evaluation uses the **TableRecordMatch** metric, which treats a table as a bag of records: each row is a record whose cell values are keyed by their column headers. Ground-truth records are matched to predicted records, and each matched pair is scored by binary cell-level agreement. TableRecordMatch is insensitive to column and row order (which don't alter key-value relationships), while dropped or transposed headers cause large mismatches and are penalized accordingly.
```
expected_markdown # Ground-truth HTML table for TableRecordMatch evaluation
# Rule fields: {} (ground truth stored in expected_markdown field)
```
**Text Content rule types** measure whether the parser faithfully reproduces textual content:
```
# Text correctness — omissions and hallucinations
missing_word_percent # Fraction of ground-truth words missing from output
unexpected_word_percent # Fraction of output words not in ground truth (hallucinations)
too_many_word_occurence_percent # Excess word duplications
missing_sentence_percent # Fraction of ground-truth sentences missing
unexpected_sentence_percent # Fraction of output sentences not in ground truth
too_many_sentence_occurence_percent # Excess sentence duplications
bag_of_digit_percent # Digit frequency distribution match (catches OCR errors like 6→8)
missing_specific_word # Binary: specific word present or absent
missing_specific_sentence # Binary: specific sentence present or absent
# Structural
order # Pairwise reading order assertion (before/after)
is_footer # Footer detection
is_header # Header detection
```
**Text Formatting rule types** verify preservation of semantically meaningful formatting:
```
# Text styling
is_bold # Bold formatting preserved
is_italic # Italic formatting preserved
is_underline # Underline formatting preserved
is_strikeout # Strikethrough preserved (marks superseded content)
is_mark # Highlight/mark preserved
is_sup # Superscript preserved (footnotes, exponents)
is_sub # Subscript preserved (chemical formulae)
# Document structure
is_title # Text appears as heading at correct level
title_hierarchy_percent # Title parent-child hierarchy score
# Special content
is_latex # Mathematical formula in LaTeX notation
is_code_block # Fenced code block with language annotation
```
**Layout rule types** evaluate visual grounding:
```
layout # Element annotation: bounding box (normalized [0,1]),
# semantic class (Text, Table, Picture, Page-Header, Page-Footer),
# content association, and reading order index
order # Layout-level reading order assertion
```
</details>
<details>
<summary>Document Categories</summary>
**Chart documents** (568 pages) — bar, line, pie, and compound charts from corporate reports, financial filings, and government publications. The dataset ensures diversity across charts with/without explicit value labels, discrete and continuous series, varying data density, and single vs. multi-chart pages.
**Table documents** (503 pages) — sourced primarily from insurance filings (SERFF), public financial documents, and government reports. Tables remain embedded in their original PDF pages, preserving the full visual context. The dataset includes merged cells, hierarchical headers, spanning rows, and multi-page tables.
**Text documents** (508 pages, shared by Content Faithfulness and Semantic Formatting) — one page per document, categorized by tag:
| Tag | Description | Docs |
|-----|-------------|-----:|
| `simple` | Simple text with some styling | 170 |
| `ocr` | Scanned/image documents, various quality | 119 |
| `multicolumns` | 1–8 columns, different layouts | 97 |
| `multilang` | 20+ languages, all major scripts | 47 |
| `misc` | Unusual content/layout/reading order | 33 |
| `dense` | Dense, large documents (e.g., newspapers) | 14 |
| `sparse` | Sparse text content, minimal text per page | 14 |
| `handwritting` | Significant handwritten text | 13 |
**Layout documents** (500 pages) — single-column, multi-column, and complex layouts with mixed media (text, images, tables, charts). Includes PDF, JPG, and PNG inputs. Evaluation uses a compact label set: Text, Table, Picture, Page-Header, and Page-Footer.
</details>
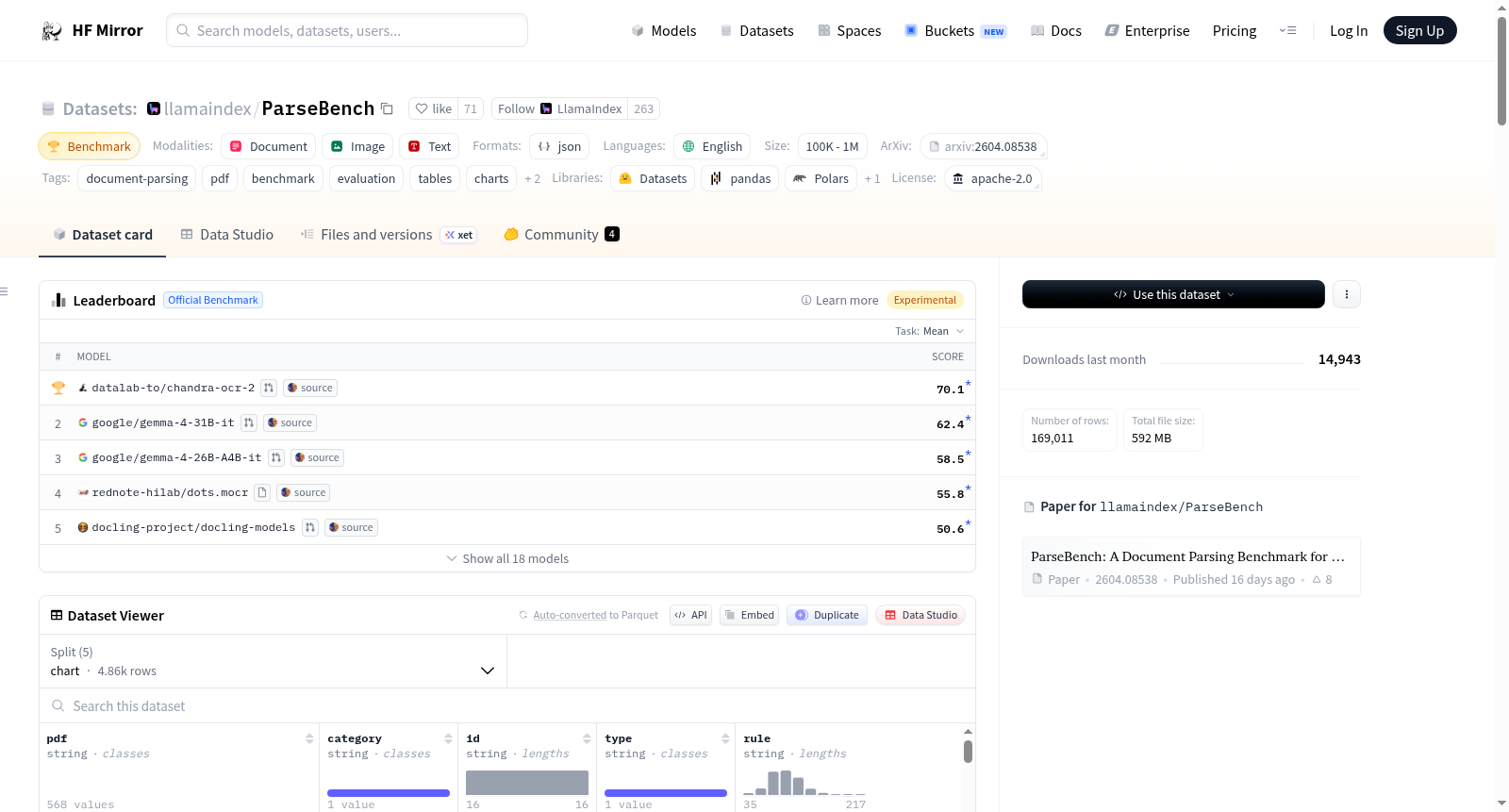
## Submit Results to the Leaderboard
We welcome and appreciate community contributions to the ParseBench [leaderboard](https://huggingface.co/datasets/llamaindex/ParseBench)!
To contribute a model's score, open a PR on the model's HuggingFace repo adding a `.eval_results/parsebench.yaml` file following the format in [this example PR](https://huggingface.co/google/gemma-4-31B-it/discussions/72).
See [HuggingFace eval-results docs](https://huggingface.co/docs/hub/eval-results) for more details.
## Data Display
### Charts
<table>
<tr>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/She-figures_p278.pdf"><img src="thumbnails/chart_01.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/m-trends-2025-en_p41.pdf"><img src="thumbnails/chart_02.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/PRO013216_91_Blackrock_Proxy-Statement-2025_p112.pdf"><img src="thumbnails/chart_03.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/Whatnextfortheglobalcarindustry_p20.pdf"><img src="thumbnails/chart_04.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/VPEG6_SIV_Information_Memorandum__June_2025__p20.pdf"><img src="thumbnails/chart_05.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/chart/ac8b3538-en_p148.pdf"><img src="thumbnails/chart_06.png" width="150" /></a></td>
</tr>
</table>
### Tables
<table>
<tr>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/1653739079_page39.pdf"><img src="thumbnails/table_01.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/222876fb_page2.pdf"><img src="thumbnails/table_02.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/JNPR.2018.page_212.pdf_110717_page1.pdf"><img src="thumbnails/table_03.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/SERFF_CA_random_pages 1_page687.pdf"><img src="thumbnails/table_04.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/FBLB-134215544_page44.pdf"><img src="thumbnails/table_05.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/table/SERFF_CA_random_pages 1_page1423.pdf"><img src="thumbnails/table_06.png" width="150" /></a></td>
</tr>
</table>
### Layout & Visual Grounding
<table>
<tr>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/2023-Sappi-Annual-Integrated-Report_Final-2_p2.pdf"><img src="thumbnails/layout_01.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/novartis-integrated-report-2021_p2.pdf"><img src="thumbnails/layout_02.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/2024-Ford-Integrated-Sustainability-and-Financial-Report_Final_p46.pdf"><img src="thumbnails/layout_03.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/Intact-Financial-Corporation-2020-Annual-Report_p38.pdf"><img src="thumbnails/layout_04.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/01205.jpg"><img src="thumbnails/layout_05.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/layout/multi_col_40665.png"><img src="thumbnails/layout_06.png" width="150" /></a></td>
</tr>
</table>
### Text (Content Faithfulness & Semantic Formatting)
<table>
<tr>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_dense__canara.pdf"><img src="thumbnails/text_01.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_handwritting__contract.pdf"><img src="thumbnails/text_02.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_multicolumns__10k2col.pdf"><img src="thumbnails/text_03.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_multilang__arabic.pdf"><img src="thumbnails/text_04.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_ocr__012-25.pdf"><img src="thumbnails/text_05.png" width="150" /></a></td>
<td><a href="https://huggingface.co/datasets/llamaindex/ParseBench/blob/main/docs/text/text_simple__10k.pdf"><img src="thumbnails/text_06.png" width="150" /></a></td>
</tr>
</table>
## Copyright Statement
All documents are sourced from public online channels. The dataset is released under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0). If there are any copyright concerns, please contact us via the GitHub repository.
## Citation
```bibtex
@misc{zhang2026parsebench,
title={ParseBench: A Document Parsing Benchmark for AI Agents},
author={Boyang Zhang and Sebastián G. Acosta and Preston Carlson and Sacha Bron and Pierre-Loïc Doulcet and Daniel B. Ospina and Simon Suo},
year={2026},
eprint={2604.08538},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.08538},
}
```
## Links
- **Website**: [parsebench.ai](https://parsebench.ai)
- **Paper**: [arXiv:2604.08538](https://arxiv.org/abs/2604.08538)
- **GitHub**: [run-llama/ParseBench](https://github.com/run-llama/ParseBench)
- **HuggingFace Dataset**: [llamaindex/ParseBench](https://huggingface.co/datasets/llamaindex/ParseBench)
提供机构:
llamaindex
搜集汇总
数据集介绍
构建方式
ParseBench的构建过程严谨而系统,旨在为AI智能体的文档解析能力提供可靠评估。研究团队从保险、金融、政府等多个领域的公开企业文档中精选了超过1,200份原始文件,并从中提取了约2,000个经过人工核验的标注页面。所有标注均通过一个两阶段流程完成:首先利用前沿的视觉语言模型进行自动化标注,随后进行针对性的人工矫正,以确保数据的高质量与准确性。最终,数据集按照表格、图表、内容忠实度、语义格式化和视觉定位这五个能力维度进行分层组织,每个维度都包含了针对性的测试规则集,总计超过169,000条细粒度规则。
使用方法
使用ParseBench评估文档解析系统时,用户需借助其官方提供的评估框架。该框架支持端到端的流水线评估,能够针对五个维度分别计算得分,并支持不同解析系统的横向比较。具体而言,用户可通过加载JSONL格式的数据文件运行测试,其中包含评估所需的各类规则参数,例如对于图表维度的ChartDataPointMatch度量,以及用于衡量表格结构相似性的GTRM指标。评估代码与文档在GitHub上开源,用户亦可将其结果提交至HuggingFace上的排行榜,以获得社区范围内的认可与比较。数据集以Apache 2.0许可协议发布,方便研究者和开发者自由使用。
背景与挑战
背景概述
ParseBench是由Boyang Zhang等研究者于2026年提出的一项面向AI代理的文档解析基准测试,旨在系统评估解析系统在企业级真实文档上的多维度表现。该数据集涵盖保险、金融、政府等多个领域,包含约2000页经过人工验证的标注页面,并围绕表格、图表、内容忠实度、语义格式与视觉定位五大能力维度构建了超过16.9万条细粒度测试规则。ParseBench的出现填补了现有文档解析评估中缺乏真实业务场景与代理工作流适配性的空白,为衡量解析系统在实际应用中的可靠性与鲁棒性提供了权威标杆。
当前挑战
文档解析领域长期面临的核心挑战在于如何精准提取复杂结构中的语义信息。ParseBench针对的五大维度各自对应典型失败场景:表格解析需应对合并单元格与层级表头带来的错位问题,图表要求从柱状图、折线图等中提取精确数值而非模糊描述,内容忠实度须避免遗漏、幻觉与阅读顺序错误,语义格式需保留删除线、上下标等具有业务含义的排版特征,视觉定位则要求每个抽取元素可追溯至原始页面坐标。构建过程中,研究人员采用前沿视觉语言模型自动标注与人工校验相结合的双流水线策略,面对多语言、手写、OCR瑕疵等复杂标注场景,确保近17万条规则的质量与一致性。
常用场景
经典使用场景
ParseBench作为面向AI代理的文档解析基准,其经典使用场景在于系统性地评估多模态大语言模型与文档解析流水线对复杂企业文档的解析能力。该数据集围绕表格、图表、内容忠实度、语义格式化和视觉定位五大核心维度设计了超过16.9万条细粒度测试规则,能够精确诊断解析系统在处理合并单元格、层次化表头、图表数据点精确提取、跨语言排版保留以及阅读顺序维护等方面的薄弱环节。研究者常利用ParseBench对自身开发的解析工具进行全维度对比,从而识别并优化特定功能瓶颈。
解决学术问题
ParseBench着力解决了学术领域中长期以来缺乏统一、多维度且贴近真实业务场景的文档解析评估标准的问题。此前,多数评估仅关注OCR文本准确率或单一版面分析指标,忽视了结构化表格重建、语义格式保真度及内容幻觉对下游任务的关键影响。该数据集通过引入GTRM、ChartDataPointMatch和Content Faithfulness Score等任务专属度量,为文档解析研究提供了精细的诊断工具。其意义在于推动了从粗粒度评估向细粒度失效模式分析的转变,使研究人员能够量化模型在金融报告、法律文书等高风险领域的实际可靠性,极大地促进了鲁棒解析算法的发展。
实际应用
在实际应用中,ParseBench所涵盖的评估维度直接映射到金融自动化、保险核保、法律合同审查和科学文献管理等急需文档解析技术的领域。例如,表格维度的高精确度要求让该基准能筛选出适用于投行财报分析的工具,确保合并单元格结构不被破坏;语义格式化维度则保障了法律条款中删除线标记的保留,避免合规风险。此外,视觉定位能力对监管场景下的可审计性至关重要。因此,ParseBench不仅是技术评测平台,更成为了企业挑选和部署文档智能处理管线时的参照标准。
数据集最近研究
最新研究方向
ParseBench以真实世界企业文档为核心,构建了涵盖表格、图表、内容忠实度、语义格式及视觉定位的五维评估框架,聚焦于AI代理在文档解析中的关键失效模式。当前前沿研究围绕工业级文档解析的鲁棒性与细粒度诊断展开,尤其关注结构化数据(如合并单元格表格、复合图表)的精确提取与内容幻觉抑制。该基准通过超16.9万条人为校验规则与可解释性指标,推动了从OCR到结构化输出的全链路评估标准化,为金融、保险等强监管领域的可审计AI工作流提供了重要参照,其跨管道比较能力亦促进了LMM与解析引擎的协同优化。
以上内容由遇见数据集搜集并总结生成


