Omni-RewardData
收藏arXiv2025-10-27 更新2025-10-29 收录
下载链接:
https://hf.co/datasets/jinzhuoran/OmniRewardData
下载链接
链接失效反馈官方服务:
资源简介:
Omni-RewardData是一个包含多种模态偏好的大规模多模态偏好数据集,旨在训练能够处理所有模态的通用多模态奖励模型。数据集由248K个通用偏好对和69K个包含自由形式偏好描述的指令调整对组成,覆盖了文本、图像、视频、音频和3D等五个模态。该数据集的构建旨在解决现有奖励模型在模态不平衡和偏好刚性方面的挑战,从而提高模型的泛化能力,更好地适应不同的用户偏好。
Omni-RewardData is a large-scale multi-modal preference dataset encompassing diverse modal preferences, aiming to train general multi-modal reward models capable of handling all modalities. The dataset consists of 248K general preference pairs and 69K instruction tuning pairs with free-form preference descriptions, covering five modalities including text, image, video, audio, and 3D. The construction of this dataset is designed to address the challenges of modal imbalance and preference rigidity in existing reward models, thereby enhancing the generalization ability of models and better adapting to diverse user preferences.
提供机构:
中国科学院自动化研究所
创建时间:
2025-10-27
搜集汇总
数据集介绍
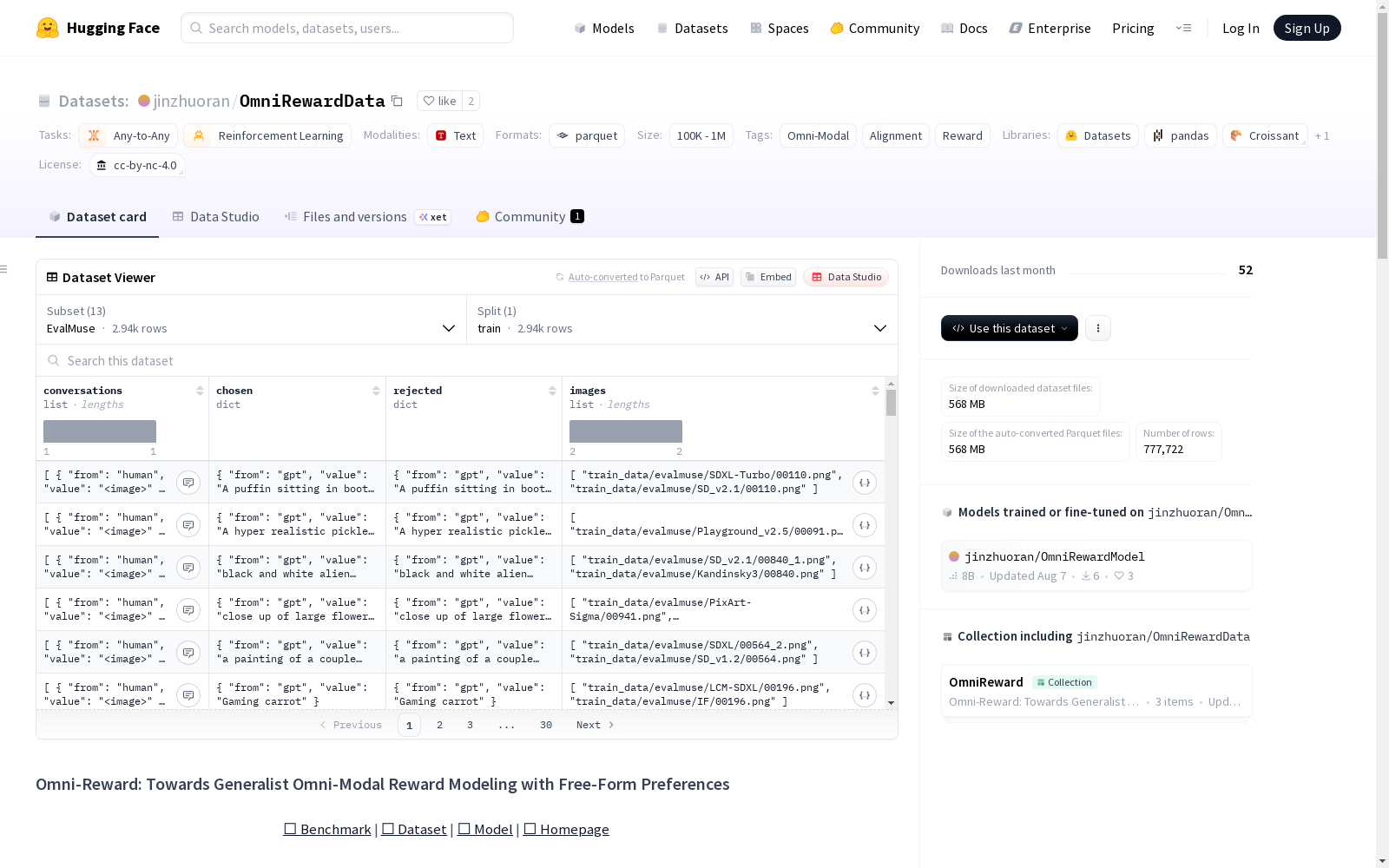
构建方式
在构建Omni-RewardData数据集时,研究团队整合了多个现有偏好数据集以支持通用偏好学习,同时通过内部指令调优数据增强模型对自由形式用户偏好的理解能力。具体而言,该数据集汇集了248,000个通用偏好对和69,000个指令调优对,覆盖文本到文本、文本图像到文本、文本到图像及文本到视频四大任务类型。数据来源包括Skywork-Reward-Preference、RLAIF-V、HPDv2等高质量标注资源,并通过GPT-4o生成自由形式指令,辅以多模型验证确保标注一致性与可靠性。
特点
Omni-RewardData的显著特点在于其跨模态的广泛覆盖与自由形式偏好的深度融合。数据集囊括文本、图像、视频、音频及3D五种模态,通过九类任务实现多维度偏好建模。其自由形式指令结构使奖励模型能够动态适应个性化评估标准,突破传统二元偏好的刚性限制。此外,数据集规模达317,000对,兼具通用性与细粒度特性,为训练通用全模态奖励模型提供了丰富且多样化的监督信号,有效缓解模态失衡与偏好僵化问题。
使用方法
该数据集主要用于训练全模态奖励模型,支持判别式与生成式两种建模范式。在判别式训练中,采用Bradley-Terry损失函数对响应进行标量评分,用户偏好以系统消息形式注入以引导模型行为。生成式训练则结合强化学习,要求模型生成链式思维解释后输出偏好决策,提升评分过程可解释性。数据集可直接用于微调多模态大语言模型,通过指令调优机制使模型依据自由形式准则调整奖励分配,适用于跨模态对齐、强化学习从人类反馈等场景,推动全模态智能体与人类价值观的深度融合。
背景与挑战
背景概述
Omni-RewardData数据集由中国科学院大学人工智能学院与自动化研究所的研究团队于2025年创建,旨在应对多模态奖励模型发展中的核心挑战。该数据集聚焦于解决人工智能行为与人类偏好对齐的关键问题,特别是在全模态场景下模型奖励建模的不足。通过整合文本、图像、视频、音频及3D等多种模态的偏好数据,Omni-RewardData为训练通用全模态奖励模型提供了大规模、多样化的基础,显著推动了多模态对齐研究的发展,并为构建更符合人类复杂偏好的智能系统奠定了数据基石。
当前挑战
Omni-RewardData面临的挑战主要体现在两方面:其一,在领域问题层面,需克服多模态奖励建模中的模态不平衡与偏好僵化问题,即现有模型难以均衡处理视频、音频等弱势模态,且无法灵活适应个性化自由形式偏好;其二,在构建过程中,数据收集需跨越九类任务和五种模态,确保高质量人类标注的一致性,同时通过多模型验证缓解生成指令的偏差,并处理标注冲突以维持数据可靠性。
常用场景
经典使用场景
在多模态人工智能研究领域,Omni-RewardData数据集被广泛应用于训练通用全模态奖励模型。该数据集通过整合文本、图像、视频、音频和3D等五种模态的31.7万组偏好对,为模型提供了跨模态对齐的丰富监督信号。研究者在构建全模态智能体时,常利用该数据集训练奖励模型以准确评估不同模态生成内容的质量,特别是在处理传统奖励模型难以覆盖的视频理解、音频生成等复杂任务时展现出独特价值。
解决学术问题
该数据集有效解决了多模态奖励建模中的两大核心难题:模态失衡与偏好刚性。通过覆盖文本到3D生成等九类任务,它突破了传统奖励模型仅关注文本和图像模态的局限,为视频、音频等弱势模态提供了系统性的偏好标注。同时,其包含的自由形式偏好描述使模型能够理解个性化评估标准,显著提升了奖励模型在未见任务上的泛化能力,为构建真正理解人类复杂偏好的通用奖励模型奠定了数据基础。
衍生相关工作
该数据集催生了系列创新性研究工作,其中最具代表性的是Omni-RewardModel系列模型。研究者基于该数据集相继提出了判别式奖励模型Omni-RewardModel-BT与生成式奖励模型Omni-RewardModel-R1,后者通过链式推理机制提升了评分过程的透明度。同时,该数据集支撑了VL-RewardBench等多模态评估基准的构建,推动了UnifiedReward等统一奖励模型的发展,为全模态对齐研究提供了重要的技术范式与评估标准。
以上内容由遇见数据集搜集并总结生成


