SWE-agent-trajectories
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/nebius/SWE-agent-trajectories
下载链接
链接失效反馈官方服务:
资源简介:
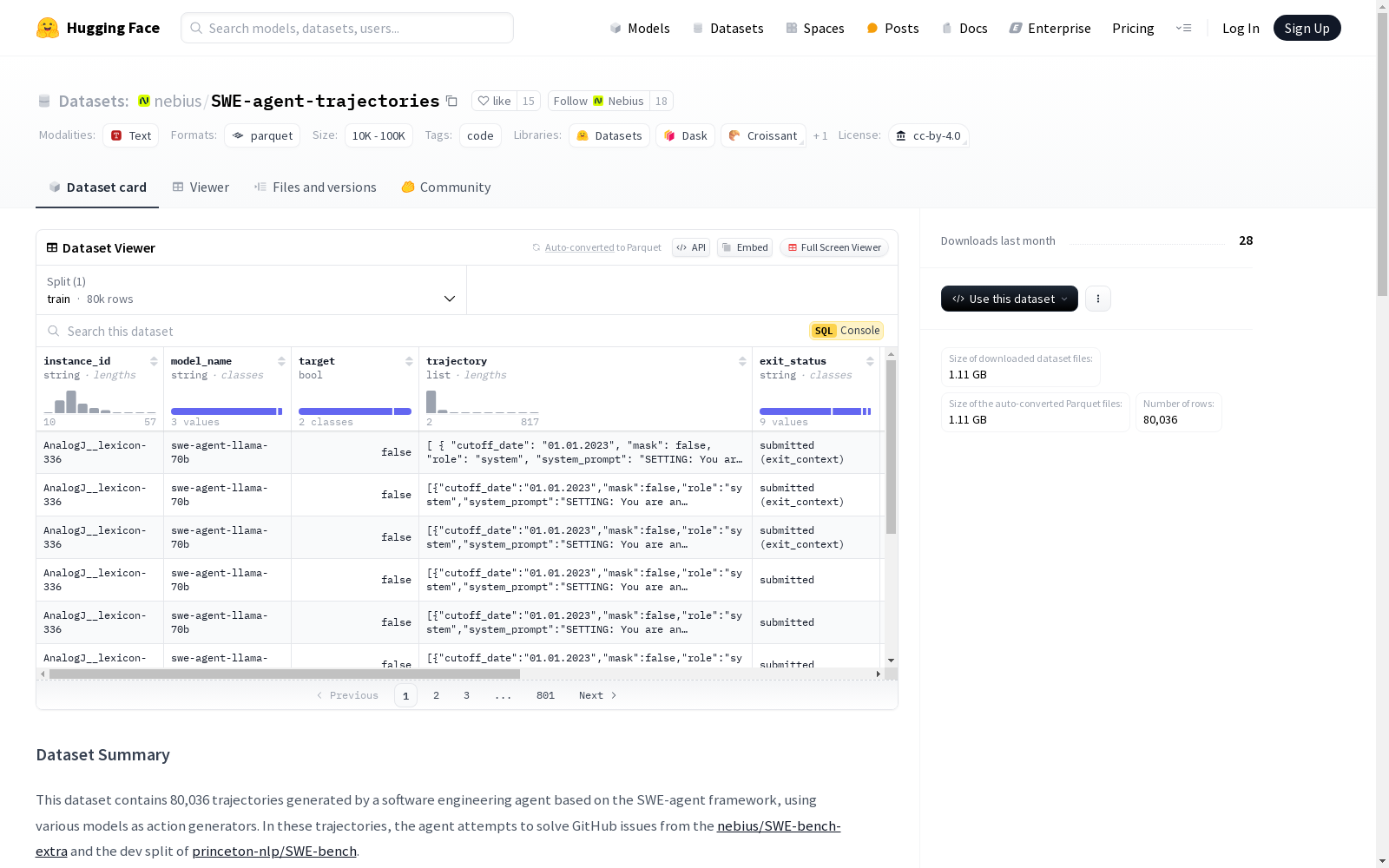
该数据集包含由软件工程代理基于SWE-agent框架生成的80,036个轨迹,使用各种模型作为动作生成器。这些轨迹用于解决来自[nebius/SWE-bench-extra](https://huggingface.co/datasets/nebius/SWE-bench-extra)和[princeton-nlp/SWE-bench](https://huggingface.co/datasets/princeton-nlp/SWE-bench)的dev分割的GitHub问题。数据集的创建是为了研究开发使用开放权重模型的软件工程代理,并在SWE-bench Verified基准测试中取得了40.6%的分数。数据集的收集分为两个阶段:收集问题解决实例和生成大量轨迹以解决收集到的问题。生成的代码补丁通过链接的拉取请求中的测试进行评估,以确定哪些补丁通过了测试。数据集的结构包括多个字段,如实例ID、模型名称、目标、轨迹、退出状态、生成的补丁和评估日志。数据集的统计信息涵盖了问题解决和补丁编辑的关键统计数据,如步骤数、上下文长度、编辑细节、退出率和正确性指标。
This dataset contains 80,036 trajectories generated by software engineering agents based on the SWE-agent framework, with various models acting as action generators. These trajectories are used to resolve GitHub issues from the dev splits of [nebius/SWE-bench-extra](https://huggingface.co/datasets/nebius/SWE-bench-extra) and [princeton-nlp/SWE-bench](https://huggingface.co/datasets/princeton-nlp/SWE-bench). This dataset was created to research software engineering agents that utilize open-weight models, and achieved a score of 40.6% on the SWE-bench Verified benchmark. The dataset collection process is divided into two stages: collecting problem-solving instances and generating a large number of trajectories to solve the collected issues. Generated code patches are evaluated via tests in the linked pull requests to identify which patches pass the tests. The dataset structure includes multiple fields such as instance ID, model name, target, trajectory, exit status, generated patch, and evaluation logs. The dataset's statistics cover key metrics for problem-solving and patch editing, including step count, context length, editing details, exit rate, and correctness metrics.
创建时间:
2024-12-09
原始信息汇总
数据集概述
该数据集包含80,036条轨迹,这些轨迹由基于SWE-agent框架的软件工程代理生成,使用各种模型作为动作生成器。代理尝试解决来自nebius/SWE-bench-extra和princeton-nlp/SWE-bench的dev分区的GitHub问题。
数据集描述
该数据集是为一个研究项目创建的,该项目专注于开发使用开放权重模型的软件工程代理,该代理在SWE-bench Verified基准测试中获得了40.6%的分数。数据集的收集包括两个阶段:收集问题解决实例,类似于SWE-bench的方法,并生成大量轨迹以解决收集的问题。生成的代码补丁通过链接的拉取请求中的测试进行评估,以确定哪些补丁通过了测试。
数据集统计
关键统计数据包括问题解决和补丁编辑的步骤、上下文长度、编辑细节、退出率和正确性指标,汇总了80,036个实例。
| 问题已解决 | 问题未解决 | ||
|---|---|---|---|
| 轨迹 | 平均步骤数 | 31.3 | 58.4 |
| 平均上下文长度(Llama 3 tokenizer) | 8,352.4 | 15,241 | |
| 最终补丁 | 编辑的文件数 | 1.33 | 2.17 |
| 编辑的行数 | 20.7 | 61.0 | |
| 退出状态率(按目标分组) | 提交 | 94.6% | 57.6% |
| 退出上下文 | 5.31% | 30.4% | |
| 其他 | 0.37% | 12% | |
| 正确步骤 | 至少打开一个正确文件 | 83% | 40% |
| 总计 | 实例数 | 13,389 | 66,647 |
数据集结构
代理的轨迹包括以下信息:
| 字段名 | 类型 | 描述 |
|---|---|---|
| instance_id | str | 代理尝试解决的问题实例的标识符,由仓库名称和问题编号组成。 |
| model_name | str | 用于生成轨迹的模型名称。 |
| target | bool | 模型是否在此轨迹中解决了问题。 |
| trajectory | str | 包含模型推理和动作(角色:ai)以及环境观察(角色:user)的JSON列表。第一个条目是系统提示(角色:system)。 |
| exit_status | str | 代理完成的状态。 |
| generated_patch | str | 模型在修改项目文件时生成的最终补丁。 |
| eval_logs | str | 用于验证最终补丁的测试执行日志。 |
许可证
该数据集根据Creative Commons Attribution 4.0许可证授权。请尊重每个特定仓库的许可证,每个实例的仓库许可证在SWE-bench-extra中提供。
此外,用户须知:如果您打算使用这些模型的输出,您必须遵守Llama 3.1许可证。
搜集汇总
数据集介绍
构建方式
该数据集通过软件工程代理框架SWE-agent生成,共包含80,036条轨迹,这些轨迹基于多种模型生成,旨在解决来自[nebius/SWE-bench-extra](https://huggingface.co/datasets/nebius/SWE-bench-extra)和[princeton-nlp/SWE-bench](https://huggingface.co/datasets/princeton-nlp/SWE-bench)的GitHub问题。数据集的构建分为两个阶段:首先,收集问题解决实例,其方法与SWE-bench类似;其次,生成大量轨迹以解决这些问题。生成的代码补丁通过关联的拉取请求中的测试进行评估,以确定其是否通过测试。
特点
该数据集的显著特点在于其丰富的轨迹信息,包括模型推理和环境观察的详细记录,以及生成的代码补丁和评估日志。此外,数据集提供了每个实例的退出状态和目标解决情况,便于研究人员分析模型的行为和性能。数据集还包含了每个实例的上下文长度、编辑细节和正确性指标,这些统计信息为深入研究软件工程代理的行为模式提供了宝贵的数据支持。
使用方法
使用该数据集时,用户可以通过HuggingFace的`datasets`库加载数据集,具体方法为调用`load_dataset('nebius/swe-agent-trajectories')`。数据集的结构清晰,包含实例ID、模型名称、目标解决情况、轨迹信息、退出状态、生成的补丁和评估日志等字段。用户可以根据这些字段进行深入分析,例如研究模型在不同问题上的表现、轨迹的复杂性以及补丁的正确性等。
背景与挑战
背景概述
SWE-agent-trajectories数据集是由Nebius公司和Princeton-NLP团队共同创建的,旨在通过软件工程代理框架解决GitHub问题。该数据集包含了80,036条由不同模型生成的轨迹,这些轨迹用于解决从Nebius/SWE-bench-extra和Princeton-NLP/SWE-bench数据集中提取的GitHub问题。该数据集的核心研究问题是如何利用开放权重模型开发高效的软件工程代理,并在SWE-bench Verified基准测试中取得了40.6%的分数。这一研究不仅推动了软件工程自动化领域的发展,还为未来的智能代理技术提供了宝贵的数据资源。
当前挑战
SWE-agent-trajectories数据集在构建过程中面临多项挑战。首先,收集和生成解决GitHub问题的轨迹需要复杂的流程和大量的计算资源。其次,确保生成的代码补丁能够通过相关测试是一个技术难题,这涉及到对代码质量和测试覆盖率的严格评估。此外,数据集的多样性和代表性也是一个挑战,因为不同的GitHub问题可能涉及不同的编程语言、框架和复杂度。最后,确保数据集的合法性和合规性,特别是在涉及第三方代码库时,也是一个重要的考虑因素。
常用场景
经典使用场景
SWE-agent-trajectories数据集的经典使用场景主要集中在软件工程领域,特别是自动化代码修复和问题解决。该数据集通过记录软件工程代理在解决GitHub问题时的轨迹,展示了代理如何通过一系列推理和行动逐步生成代码补丁。研究者可以利用这些轨迹数据来训练和评估自动化软件工程工具,优化其在复杂问题上的表现。
实际应用
在实际应用中,SWE-agent-trajectories数据集可用于开发和优化自动化代码修复工具,帮助软件开发者快速解决GitHub上的问题。通过分析代理的轨迹,开发者可以识别常见问题模式并生成相应的修复方案,从而提高软件开发效率。此外,该数据集还可用于培训新一代的软件工程代理,使其在面对复杂问题时能够更加高效和准确地进行操作。
衍生相关工作
基于SWE-agent-trajectories数据集,研究者已开展了一系列相关工作,包括改进自动化代码修复算法、优化软件工程代理的推理机制以及开发新的评估指标。这些工作不仅提升了自动化工具的性能,还为软件工程领域的研究提供了新的视角和方法。此外,该数据集还激发了对自动化软件工程代理行为模式的研究,推动了该领域的进一步发展。
以上内容由遇见数据集搜集并总结生成


