RAVDESS Facial Landmark Tracking
收藏www.kaggle.com2019-09-10 更新2025-01-21 收录
下载链接:
https://www.kaggle.com/uwrfkaggler/ravdess-facial-landmark-tracking
下载链接
链接失效反馈官方服务:
资源简介:
RAVDESS Facial Landmark Tracking
------------
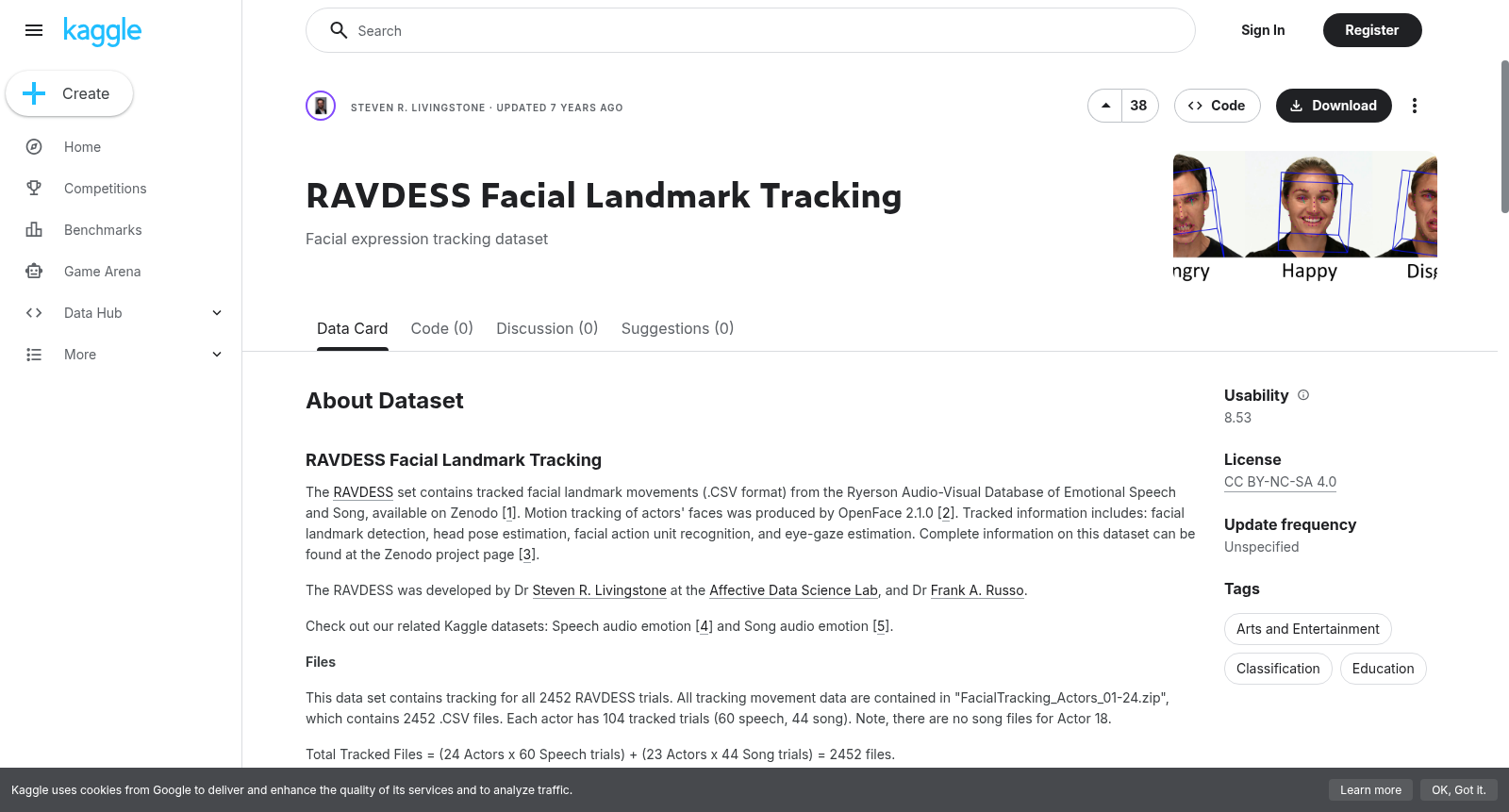
The [RAVDESS](https://affectivedatascience.com/datasets.html#ravdess) set contains tracked facial landmark movements (.CSV format) from the Ryerson Audio-Visual Database of Emotional Speech and Song, available on Zenodo [[1](https://zenodo.org/record/1188976)]. Motion tracking of actors' faces was produced by OpenFace 2.1.0 [[2](https://github.com/TadasBaltrusaitis/OpenFace)]. Tracked information includes: facial landmark detection, head pose estimation, facial action unit recognition, and eye-gaze estimation. Complete information on this dataset can be found at the Zenodo project page [[3](https://zenodo.org/record/3255102)].
The RAVDESS was developed by Dr [Steven R. Livingstone](https://affectivedatascience.com/people/livingstone_sr) at the [Affective Data Science Lab](https://affectivedatascience.com), and Dr [Frank A. Russo](https://www.torontomu.ca/psychology/about-us/our-people/faculty/frank-russo/).
Check out our related Kaggle datasets: Speech audio emotion [[4](https://www.kaggle.com/uwrfkaggler/ravdess-emotional-speech-audio)] and Song audio emotion [[5](https://www.kaggle.com/uwrfkaggler/ravdess-emotional-song-audio)].
**Files**
This data set contains tracking for all 2452 RAVDESS trials. All tracking movement data are contained in "FacialTracking_Actors_01-24.zip", which contains 2452 .CSV files. Each actor has 104 tracked trials (60 speech, 44 song). Note, there are no song files for Actor 18.
Total Tracked Files = (24 Actors x 60 Speech trials) + (23 Actors x 44 Song trials) = 2452 files.
Tracking results for each trial are provided as individual comma separated value files (CSV format). File naming convention of tracked files is identical to that of the RAVDESS. For example, tracked file "01-01-01-01-01-01-01.csv" corresponds to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4". For a complete description of the RAVDESS file naming convention and experimental manipulations, please see the [RAVDESS Zenodo page](https://zenodo.org/record/1188976).
Tracking overlay videos for all trials (720p Xvid, .avi), one zip file per Actor, can be downloaded from the RAVDESS Facial Landmark Tracking project page on [Zenodo](https://zenodo.org/record/3255102).
As the RAVDESS does not contain "ground truth" facial landmark locations, the overlay videos provide a visual 'sanity check' for researchers to confirm the general accuracy of the tracking results. The file naming convention of tracking overlay videos also matches that of the RAVDESS. For example, tracking video "01-01-01-01-01-01-01.avi" corresponds to RAVDESS audio-video file "01-01-01-01-01-01-01.mp4".
**Tracking File Output Format**
This data set retained OpenFace's data output format, [described here in detail](https://github.com/TadasBaltrusaitis/OpenFace/wiki/Output-Format). The resolution of all input videos was 1280x720. When tracking output units are in pixels, their range of values is (0,0) (top left corner) to (1280,720) (bottom right corner).
*Columns 1-3 = Timing and Detection Confidence*
1. Frame - The number of the frame (source videos 30 fps), range = 1 to n
2. Timestamp - Time of frame, range = 0 to m
3. Confidence - Tracker confidence level in current landmark detection estimate, range = 0 to 1
*Columns 4-291 = Eye Gaze Detection*
4-6. gaze_0_x, gaze_0_y, gaze_0_z - Eye gaze direction vector in world coordinates for eye 0 (normalized), eye 0 is the leftmost eye in the image (think of it as a ray going from the left eye in the image in the direction of the eye gaze).
7-9. gaze_1_x, gaze_1_y, gaze_1_z - Eye gaze direction vector in world coordinates for eye 1 (normalized), eye 1 is the rightmost eye in the image (think of it as a ray going from the right eye in the image in the direction of the eye gaze).
10-11. gaze_angle_x, gaze_angle_y - Eye gaze direction in radians in world coordinates, averaged for both eyes. If a person is looking left-right this will results in the change of gaze_angle_x (from positive to negative) and, if a person is looking up-down this will result in change of gaze_angle_y (from negative to positive), if a person is looking straight ahead both of the angles will be close to 0 (within measurement error).
12-123. eye_lmk_x_0, ..., eye_lmk_x55, eye_lmk_y_0,..., eye_lmk_y_55 - Location of 2D eye region landmarks in pixels. A figure describing the landmark index [can be found here](https://raw.githubusercontent.com/wiki/TadasBaltrusaitis/OpenFace/images/eye_lmk_markup.png).
124-291. eye_lmk_X_0, ..., eye_lmk_X55, eye_lmk_Y_0,..., eye_lmk_Y_55,..., eye_lmk_Z_0,..., eye_lmk_Z_55 - Location of 3D eye region landmarks in millimeters. A figure describing the landmark index [can be found here](https://raw.githubusercontent.com/wiki/TadasBaltrusaitis/OpenFace/images/eye_lmk_markup.png).
*Columns 292-297 = Head pose*
292-294. pose_Tx, pose_Ty, pose_Tz - Location of the head with respect to camera in millimeters (positive Z is away from the camera).
295-297. pose_Rx, pose_Ry, pose_Rz - Rotation of the head in radians around X,Y,Z axes with the convention R = Rx * Ry * Rz, left-handed positive sign. This can be seen as pitch (Rx), yaw (Ry), and roll (Rz). The rotation is in world coordinates with the camera being located at the origin.
*Columns 298-433 = Facial Landmarks locations in 2D*
298-433. x_0, ..., x_67, y_0,...y_67 - Location of 2D landmarks in pixels. A figure describing the landmark index can be found here.
*Columns 434-637 = Facial Landmarks locations in 3D*
434-637. X_0, ..., X_67, Y_0,..., Y_67, Z_0,..., Z_67 - Location of 3D landmarks in millimetres. A figure describing the landmark index can be found here. For these values to be accurate, OpenFace needs to have good estimates for fx,fy,cx,cy.
*Columns 638-677 = Rigid and non-rigid shape parameters*
Parameters of a point distribution model (PDM) that describe the rigid face shape (location, scale and rotation) and non-rigid face shape (deformation due to expression and identity). For more details, please refer to chapter 4.2 of my Tadas Baltrusaitis's PhD thesis [download link].
638-643. p_scale, p_rx, p_ry, p_rz, p_tx, p_ty - Scale, rotation, and translation terms of the PDM.
644-677. p_0, ..., p_33 - Non-rigid shape parameters.
*Columns 687-712 = Facial Action Units*
Facial Action Units (AUs) are a way to describe human facial movements (Ekman, Friesen, and Hager, 2002) [wiki link]. More information on OpenFace's implementation of AUs can be found here.
687-694. AU01_r, AU02_r, AU04_r, AU05_r, AU06_r, AU07_r, AU09_r, AU10_r, AU12_r, AU14_r, AU15_r, AU17_r, AU20_r, AU23_r, AU25_r, AU26_r, AU45_r - Intensity of AU movement, range from 0 (no muscle contraction) to 5 (maximal muscle contraction).
695-712. AU01_c, AU02_c, AU04_c, AU05_c, AU06_c, AU07_c, AU09_c, AU10_c, AU12_c, AU14_c, AU15_c, AU17_c, AU20_c, AU23_c, AU25_c, AU26_c, AU28_c, AU45_c - Presence or absence of 18 AUs, range 0 (absent, not detected) to 1 (present, detected).
Note, OpenFace's columns 2 and 5 (face_id and success, respectively) were not included in this data set. These values were redundant as a single face was detected in all frames, in all 2452 trials.
**Camera Parameters and 3D Calibration Procedure**
This data set contains accurate estimates of actors' 3D head poses. To produce these, camera parameters at the time of recording were required (distance from camera to actor, and camera field of view). These values were used with OpenCV's camera calibration procedure, described here, to produce estimates of the camera's focal length and optical center at the time of actor recordings. The four values produced by the calibration procedure (fx,fy,cx,cy) were input to OpenFace as command line arguments during facial tracking, described here, to produce accurate estimates of 3D head pose.
*Camera Parameters*
Distance between camera and actor = 1.4 meters
Camera field of view = 0.5 meters
Focal length in x (fx) = 6385.9
Focal length in y (fy) = 6339.6
Optical center in x (cx) = 824.241
Optical center in y (cy) = 1033.6
The use of OpenCV's calibration procedure was required as the video camera used in the RAVDESS recordings did not report focal length values. Unlike SLR cameras, most video cameras do not provide this information to the user due to their dynamic focus feature. For all RAVDESS recordings, camera distance, field of view, and focal point (manual fixed camera focus) were kept constant.
RAVDESS面部特征追踪数据集
------------
该[RAVDESS](https://affectivedatascience.com/datasets.html#ravdess)数据集收录了来自Ryerson音频-视觉情感与歌声数据库(Zenodo上可获取[[1](https://zenodo.org/record/1188976)])的面部特征运动追踪数据(.CSV格式)。演员面部运动追踪由OpenFace 2.1.0软件生成[[2](https://github.com/TadasBaltrusaitis/OpenFace)]。追踪信息包括:面部特征检测、头部姿态估计、面部动作单元识别和眼神追踪估计。关于该数据集的详细信息可在Zenodo项目页面上找到[[3](https://zenodo.org/record/3255102)]。
RAVDESS数据集由[Affective Data Science Lab](https://affectivedatascience.com)的Dr [Steven R. Livingstone](https://affectivedatascience.com/people/livingstone_sr)和Dr [Frank A. Russo](https://www.torontomu.ca/psychology/about-us/our-people/faculty/frank-russo/)共同开发。
查阅相关Kaggle数据集:语音音频情感[[4](https://www.kaggle.com/uwrfkaggler/ravdess-emotional-speech-audio)]和歌曲音频情感[[5](https://www.kaggle.com/uwrfkaggler/ravdess-emotional-song-audio)]。
**文件内容**
本数据集包含2452个RAVDESS实验的追踪数据。所有追踪运动数据均包含在“FacialTracking_Actors_01-24.zip”文件中,其中包含2452个.CSV文件。每位演员有104个追踪实验(60个语音实验,44个歌曲实验)。请注意,第18位演员没有歌曲文件。
总追踪文件数 = (24位演员 x 60个语音实验) + (23位演员 x 44个歌曲实验) = 2452个文件。
每个实验的追踪结果以单独的逗号分隔值文件(CSV格式)提供。追踪文件的命名规范与RAVDESS一致。例如,追踪文件“01-01-01-01-01-01-01.csv”对应于RAVDESS音频-视频文件“01-01-01-01-01-01-01.mp4”。关于RAVDESS文件命名规范和实验操作的完整描述,请参阅[RAVDESS Zenodo页面](https://zenodo.org/record/1188976)。
所有实验的追踪叠加视频(720p Xvid,.avi格式),每个演员一个zip文件,可从Zenodo上的RAVDESS面部特征追踪项目页面上下载[[3](https://zenodo.org/record/3255102)]。
由于RAVDESS不包含“地面真相”面部特征位置,因此叠加视频为研究人员提供了一个视觉‘理智检查’,以确认追踪结果的总体准确性。追踪叠加视频的文件命名规范也与RAVDESS一致。例如,追踪视频“01-01-01-01-01-01-01.avi”对应于RAVDESS音频-视频文件“01-01-01-01-01-01-01.mp4”。
**追踪文件输出格式**
本数据集保留了OpenFace的数据输出格式,[详细描述见此处](https://github.com/TadasBaltrusaitis/OpenFace/wiki/Output-Format)。所有输入视频的分辨率为1280x720。当追踪输出单位为像素时,其值范围为(0,0)(左上角)到(1280,720)(右下角)。
*列1-3 = 定时和检测置信度*
1. Frame - 帧数(源视频30 fps),范围 = 1 到 n
2. Timestamp - 帧时间,范围 = 0 到 m
3. Confidence - 追踪器对当前特征检测估计的置信度水平,范围 = 0 到 1
*列4-291 = 眼神追踪检测*
4-6. gaze_0_x, gaze_0_y, gaze_0_z - 眼睛0的世界坐标系中的眼神方向向量(归一化),眼睛0是图像中最左侧的眼睛(可以将其视为从图像中的左侧眼睛发出的指向眼神方向的光线)。
7-9. gaze_1_x, gaze_1_y, gaze_1_z - 眼睛1的世界坐标系中的眼神方向向量(归一化),眼睛1是图像中最右侧的眼睛(可以将其视为从图像中的右侧眼睛发出的指向眼神方向的光线)。
10-11. gaze_angle_x, gaze_angle_y - 两个眼睛的世界坐标系中的眼神方向(以弧度为单位),平均计算。如果一个人向左右看,这将导致gaze_angle_x(从正到负)的变化,如果一个人上下看,这将导致gaze_angle_y(从负到正)的变化,如果一个人直视前方,这两个角度将接近0(在测量误差范围内)。
12-123. eye_lmk_x_0, ..., eye_lmk_x55, eye_lmk_y_0,..., eye_lmk_y_55 - 2D眼睛区域特征点的像素位置。可以在此处找到描述特征点索引的图像[链接](https://raw.githubusercontent.com/wiki/TadasBaltrusaitis/OpenFace/images/eye_lmk_markup.png)。
124-291. eye_lmk_X_0, ..., eye_lmk_X55, eye_lmk_Y_0,..., eye_lmk_Y_55,..., eye_lmk_Z_0,..., eye_lmk_Z_55 - 3D眼睛区域特征点的毫米位置。可以在此处找到描述特征点索引的图像[链接](https://raw.githubusercontent.com/wiki/TadasBaltrusaitis/OpenFace/images/eye_lmk_markup.png)。
*列292-297 = 头部姿态*
292-294. pose_Tx, pose_Ty, pose_Tz - 相对于相机的头部位置(以毫米为单位)(正Z表示远离相机)。
295-297. pose_Rx, pose_Ry, pose_Rz - 头部围绕X、Y、Z轴的旋转(以弧度为单位),遵循R = Rx * Ry * Rz,左手法则。这可以被视为俯仰(Rx)、偏航(Ry)和翻滚(Rz)。旋转是在世界坐标系中,相机位于原点。
*列298-433 = 2D面部特征位置*
298-433. x_0, ..., x_67, y_0,...y_67 - 2D特征点的像素位置。可以在此处找到描述特征点索引的图像。
*列434-637 = 3D面部特征位置*
434-637. X_0, ..., X_67, Y_0,..., Y_67, Z_0,..., Z_67 - 3D特征点的毫米位置。可以在此处找到描述特征点索引的图像。为了确保这些值的准确性,OpenFace需要对其fx、fy、cx、cy的估计良好。
*列638-677 = 刚性和非刚性形状参数*
参数为点分布模型(PDM)的参数,描述刚性面部形状(位置、缩放和旋转)和非刚性面部形状(由于表情和身份引起的变形)。更多细节,请参阅Tadas Baltrusaitis博士论文的第4.2章[下载链接]。
638-643. p_scale, p_rx, p_ry, p_rz, p_tx, p_ty - PDM的缩放、旋转和转换项。
644-677. p_0, ..., p_33 - 非刚性形状参数。
*列687-712 = 面部动作单元*
面部动作单元(AUs)是描述人类面部运动的一种方式(Ekman, Friesen, and Hager, 2002)[wiki链接]。关于OpenFace实现AUs的更多信息,请参阅此处。
687-694. AU01_r, AU02_r, AU04_r, AU05_r, AU06_r, AU07_r, AU09_r, AU10_r, AU12_r, AU14_r, AU15_r, AU17_r, AU20_r, AU23_r, AU25_r, AU26_r, AU45_r - AU运动的强度,范围从0(无肌肉收缩)到5(最大肌肉收缩)。
695-712. AU01_c, AU02_c, AU04_c, AU05_c, AU06_c, AU07_c, AU09_c, AU10_c, AU12_c, AU14_c, AU15_c, AU17_c, AU20_c, AU23_c, AU25_c, AU26_c, AU28_c, AU45_c - 18个AUs的存在或不存在,范围从0(不存在,未检测到)到1(存在,检测到)。
注意,由于在所有2452个实验中,每帧都检测到一个面部,因此未包含OpenFace的列2和5(面部ID和成功,分别)。这些值是冗余的。
**摄像机参数和3D校准程序**
本数据集包含了演员3D头部姿态的精确估计。为了生成这些估计,在录制时需要摄像机参数(摄像机到演员的距离和摄像机视场)。使用OpenCV的摄像机校准程序(此处描述),结合这些值,产生了摄像机在演员录制时的焦距和光学中心的估计。校准程序产生的四个值(fx、fy、cx、cy)在面部追踪期间作为命令行参数输入到OpenFace中,以生成3D头部姿态的精确估计。
*摄像机参数*
摄像机到演员的距离 = 1.4米
摄像机视场 = 0.5米
x轴焦距(fx)= 6385.9
y轴焦距(fy)= 6339.6
x轴光学中心(cx)= 824.241
y轴光学中心(cy)= 1033.6
由于RAVDESS录制所用的视频摄像机未报告焦距值,因此需要使用OpenCV的校准程序。与单反相机不同,大多数视频摄像机不向用户提供此信息,因为它们具有动态对焦功能。对于所有RAVDESS录制,摄像机距离、视场和焦距(手动固定摄像机对焦)均保持不变。
提供机构:
Kaggle
搜集汇总
数据集介绍
背景与挑战
背景概述
RAVDESS Facial Landmark Tracking数据集包含2452个CSV文件,记录了24位演员在情感语音和歌曲表演中的面部地标运动跟踪数据。数据由OpenFace 2.1.0生成,涵盖面部地标、头部姿势、面部动作单元和眼动估计等多维度信息,适用于情感识别和面部运动分析研究。
以上内容由遇见数据集搜集并总结生成


