Livingwithmachines/hmd-erwt-training
收藏Hugging Face2022-11-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Livingwithmachines/hmd-erwt-training
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- no-annotation
language:
- en
language_creators:
- machine-generated
license:
- cc0-1.0
multilinguality:
- monolingual
pretty_name: Dataset Card for ERWT Hertiage Made Digital Newspapers training data
size_categories:
- 100K<n<1M
source_datasets: []
tags:
- library,lam,newspapers,1800-1900
task_categories:
- fill-mask
task_ids:
- masked-language-modeling
---
# Dataset Card for ERWT Hertiage Made Digital Newspapers training data
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains text extracted at the page level from historic digitised newspapers from the [Heritage Made Digital](https://bl.iro.bl.uk/collections/9a6a4cdd-2bfe-47bb-8c14-c0a5d100501f?locale=en) newspaper digitisation program. The newspapers in the dataset were published between 1800 and 1870.
The data was primarily created as a dataset for training 'time-aware' language models.
The dataset contains text generated from Optical Character Recognition software on digitised newspaper pages. This dataset includes the plain text from the OCR alongside some minimal metadata associated with the newspaper from which the text is derived and OCR confidence score information generated from the OCR software.
#### Breakdown of word counts over time
Whilst the dataset covers a time period between 1800 and 1870, the number of words in the dataset is not distributed evenly across time in this dataset. The figures below give a sense of the breakdown over time in terms of the number of words which appear in the dataset.
| year | total word_count | unique words |
|-------:|-------------------:|---------------:|
| 1800 | 282,554,255 | 15,506,515 |
| 1810 | 328,817,174 | 18,295,974 |
| 1820 | 328,817,174 | 18,295,974 |
| 1830 | 194,958,624 | 10,816,938 |
| 1840 | 305,545,086 | 17,018,560 |
| 1850 | 376,194,785 | 20,942,876 |
| 1860 | 305,545,086 | 17,018,560 |
| 1870 | 51,241,037 | 2,284,803 |

### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
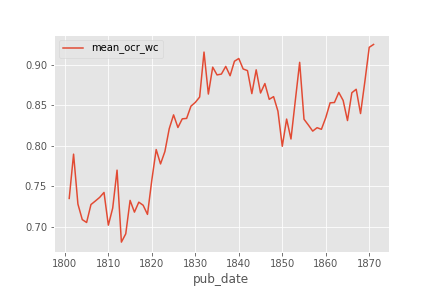
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
提供机构:
Livingwithmachines
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: ERWT Hertiage Made Digital Newspapers training data
- 语言: 英语(en)
- 数据集创建方式: 机器生成
- 许可证: CC0-1.0
- 多语言性: 单语种
- 大小: 10万<n<100万
- 标签: 图书馆, LAM, 报纸, 1800-1900
- 任务类别: 填空
- 任务ID: 掩码语言建模
数据集描述
数据集摘要
本数据集包含从Heritage Made Digital报纸数字化项目中提取的历史数字化报纸的页面级文本。数据集中的报纸出版于1800年至1870年之间。
数据集主要用于训练“时间感知”语言模型。包含由光学字符识别软件生成的数字化报纸页面的文本,以及与报纸相关的最小元数据和OCR软件生成的置信度分数信息。
按时间分解的单词计数
数据集覆盖1800至1870年的时间段,但数据集中的单词数量在时间上分布不均。以下表格提供了数据集中单词数量随时间分布的大致情况。
| 年份 | 总词数 | 唯一词数 |
|---|---|---|
| 1800 | 282,554,255 | 15,506,515 |
| 1810 | 328,817,174 | 18,295,974 |
| 1820 | 328,817,174 | 18,295,974 |
| 1830 | 194,958,624 | 10,816,938 |
| 1840 | 305,545,086 | 17,018,560 |
| 1850 | 376,194,785 | 20,942,876 |
| 1860 | 305,545,086 | 17,018,560 |
| 1870 | 51,241,037 | 2,284,803 |

数据集结构
数据实例
[更多信息待补充]
数据字段
[更多信息待补充]
数据分割
[更多信息待补充]
数据集创建
数据筛选理由
[更多信息待补充]
源数据
初始数据收集和规范化
[更多信息待补充]
源语言生产者
[更多信息待补充]
注释
注释过程
[更多信息待补充]
注释者
[更多信息待补充]
个人和敏感信息
[更多信息待补充]
使用数据的考虑因素
数据集的社会影响
[更多信息待补充]
偏见讨论
[更多信息待补充]
其他已知限制
[更多信息待补充]
附加信息
数据集管理者
[更多信息待补充]
许可信息
[更多信息待补充]
引用信息
[更多信息待补充]
贡献
感谢@github-username添加此数据集。


