SIV-Bench
收藏arXiv2025-06-05 更新2025-06-10 收录
下载链接:
https://kfq20.github.io/sivbench/
下载链接
链接失效反馈官方服务:
资源简介:
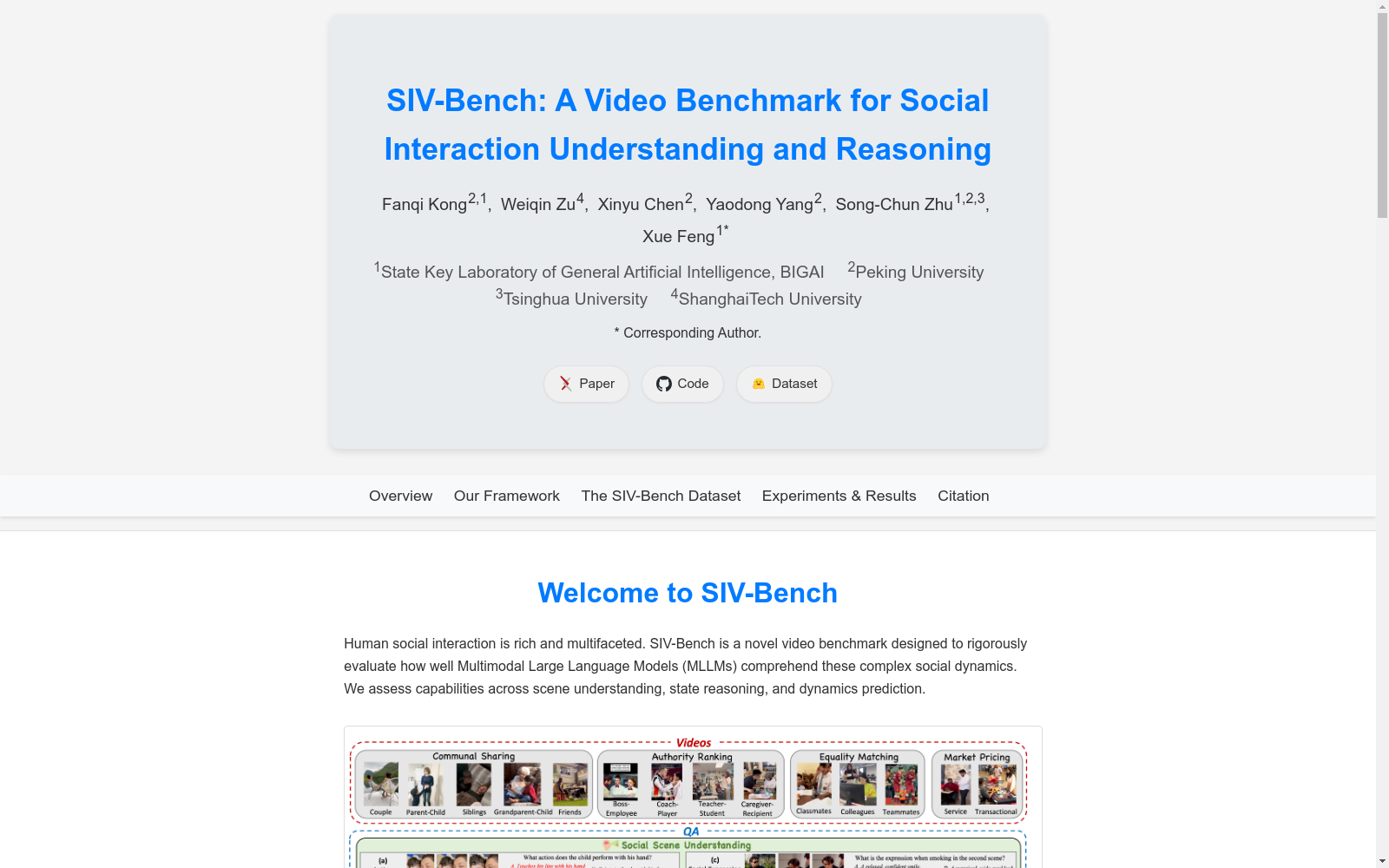
SIV-Bench是一个视频基准数据集,用于严格评估多模态大型语言模型(MLLMs)在社交场景理解(SSU)、社交状态推理(SSR)和社交动态预测(SDP)方面的能力。该数据集包含2792个视频片段和8792个精心生成的问答对,源自于人类与LLM协作的管道。它最初是从TikTok和YouTube收集的,涵盖广泛的视频类型、展示风格和语言文化背景。SIV-Bench还专门设置了分析不同文本线索影响的环境,包括原始屏幕文本、添加的对话或无文本。在领先的MLLMs上进行的综合实验表明,模型在处理SSU方面表现得很好,但在SSR和SDP方面却存在显著困难,其中关系推理(RI)是一个严重的瓶颈。SIV-Bench为分析当前MLLMs的优缺点提供了关键见解,以推动更具有社交智能的AI的发展。数据集和代码可在https://kfq20.github.io/sivbench/获取。
SIV-Bench is a video benchmark dataset designed to rigorously evaluate the capabilities of Multimodal Large Language Models (MLLMs) in three core social intelligence tasks: Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamic Prediction (SDP). This dataset contains 2,792 video clips and 8,792 meticulously generated question-answer pairs, which are derived from a pipeline where humans collaborate with LLMs. It was initially collected from TikTok and YouTube, covering a wide spectrum of video genres, presentation styles, and linguistic and cultural backgrounds. SIV-Bench also specifically offers an experimental setup for analyzing the impact of different textual cues, including raw on-screen text, added dialogues, or no text at all. Comprehensive experiments conducted on state-of-the-art MLLMs have demonstrated that these models perform excellently in handling SSU, but encounter substantial difficulties in SSR and SDP, with Relation Inference (RI) acting as a critical bottleneck. SIV-Bench provides critical insights for analyzing the strengths and limitations of current MLLMs, with the goal of promoting the development of AI endowed with stronger social intelligence. The dataset and code are accessible at https://kfq20.github.io/sivbench/.
提供机构:
北京大学、清华大学、上海科技大学、BIGAI
创建时间:
2025-06-05
搜集汇总
数据集介绍
构建方式
SIV-Bench数据集通过严谨的人机协作流程构建,首先从TikTok和YouTube平台采集2,792个涵盖14种社会关系类型的视频片段,确保内容覆盖日常记录、电影片段、体育赛事等多种体裁。采用Whisper-large-v3模型进行音频转录与翻译,生成三种字幕条件(原始字幕、添加对话字幕、去除字幕)以评估语言线索的影响。通过Gemini-2.0-Flash生成初始问题对,结合GPT-4o-mini生成干扰项,并经过三阶段质量验证:专家模型共识筛选、无视频输入过滤及人工标注复核,最终形成8,728个高质量多选题对。
特点
该数据集以Fiske社会关系理论为框架,系统评估多模态大语言模型在社交场景理解(SSU)、社交状态推理(SSR)和社交动态预测(SDP)三个维度的能力。其核心特色在于:1)细粒度划分10个子任务,如关系推断、意图推理等;2)包含多元文化背景的短视频,平均时长32.49秒;3)独创的三字幕条件设计,可量化分析语言模态对社交认知的影响;4)问题难度经过分层控制,其中SSR类问题占比达56.7%,重点挑战模型的深层社会推理能力。
使用方法
使用SIV-Bench时需注意:1)对于视频输入型模型(如Gemini系列),直接加载MP4文件;图像序列处理模型(如LLaVA)则需均匀采样16帧。2)评估需区分三种字幕条件,原始版本(origin)保留平台原生文字,+sub版本添加转录对话,-sub版本去除所有文本线索。3)采用标准提示模板确保输出格式统一,要求模型返回选项字母及完整文本。4)性能分析应重点关注SSR任务中的关系推断(RI)准确率,该子任务在现有模型中平均表现最低(64.41%),能有效暴露模型社交认知缺陷。
背景与挑战
背景概述
SIV-Bench是由BIGAI、北京大学、清华大学和上海科技大学的研究团队于2025年推出的视频基准测试数据集,旨在系统评估多模态大语言模型(MLLMs)在社会交互理解与推理方面的能力。该数据集基于Fiske的关系模型理论,构建了包含2,792个视频片段和8,792个高质量问答对的评估体系,覆盖社交场景理解(SSU)、社交状态推理(SSR)和社交动态预测(SDP)三个核心维度。其视频素材源自TikTok和YouTube平台,涵盖多元文化背景和14种典型社会关系类型,为人工智能社交智能研究提供了标准化评估工具。
当前挑战
该数据集主要解决社交视频理解中多模态线索整合与隐性关系推理的挑战,具体表现为:1) 领域问题方面,模型在关系推理(RI)任务中准确率显著低于场景理解任务,存在主次关系混淆、场景误导性线索等问题;2) 构建过程中需克服多模态数据对齐的困难,包括视频素材的社会关系标注一致性、问答对设计的认知层级划分,以及跨文化社交行为差异的标准化处理。此外,字幕条件实验表明语言线索的缺失会使SSR任务性能下降1.176%,凸显多模态融合的技术瓶颈。
常用场景
经典使用场景
SIV-Bench作为多模态大语言模型(MLLMs)在社交视频理解领域的评估基准,其经典使用场景涵盖对社交场景理解(SSU)、社交状态推理(SSR)和社交动态预测(SDP)三大核心能力的系统性测试。通过2792个涵盖14种社会关系的视频片段及8792个精细化构建的问答对,该数据集为模型提供了识别可见行为要素(如动作、环境)、推断隐含心理状态(如意图、情绪)以及预测互动演变轨迹的标准化任务框架。其多维度评估体系尤其适合检验模型在复杂社交语境下的跨模态关联与深层推理能力。
实际应用
该数据集的实际应用价值体现在多个前沿领域:在智能助手中,可优化对话系统对用户非语言线索(如微表情、语调)的实时解析能力;在教育科技领域,能训练虚拟教师识别学生群体互动中的协作或冲突模式;于跨文化商业场景,辅助AI分析不同关系层级(如权威型vs平等型)下的谈判策略差异。特别值得注意的是,其提供的三种字幕条件(原始/增删字幕)验证了语言线索对社交理解的关键影响,为视听障碍辅助工具的设计提供了数据支持。
衍生相关工作
SIV-Bench已衍生出两类代表性研究:一类是围绕其发现的Relation Inference瓶颈问题,如InternVL3-78B通过引入关系感知注意力机制将RI准确率提升9.2%;另一类扩展了基准的评估维度,如Social-IQ 3.0整合其SSR任务构建更复杂的多轮社交决策评估。此外,其数据构建方法论启发了VideoSocialBench等后续工作采用人机协作的QA生成管道,而基于字幕影响的发现直接推动了像DialogueGround这样的跨模态对齐框架的发展。
以上内容由遇见数据集搜集并总结生成


