ToolACE-Llama-cleaned
收藏Hugging Face2025-02-10 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/tryumanshow/ToolACE-Llama-cleaned
下载链接
链接失效反馈官方服务:
资源简介:
这是一个修改后的ToolACE数据集,专门为LLaMA模型设计,以支持工具调用功能的微调。数据集包含了工具信息和对话信息,已经格式化为LLaMA模型可以直接使用的结构。适用于所有支持工具调用的LLaMA版本,包括3.1、3.2和3.3。
This is a modified ToolACE dataset specifically designed for LLaMA models to support fine-tuning of tool calling capabilities. The dataset contains tool information and dialogue information, and has been formatted into a structure directly usable by LLaMA models. It is applicable to all LLaMA versions that support tool calling functionality, including versions 3.1, 3.2 and 3.3.
创建时间:
2025-02-08
原始信息汇总
数据集概述
数据集名称
ToolACE-Llama-cleaned
语言
- 英语 (en)
许可
Apache-2.0
数据集信息
- 特征:
- tools:字符串类型
- conversations:字符串类型
- 划分:
- 训练集:22355409 字节,10547 个样本
- 下载大小:8247623 字节
- 数据集大小:22355409 字节
配置
- 默认配置:
- 数据文件:data/train-*
简介
该数据集是基于 ToolACE 数据集的改编版,专为 LLaMA 模型进行工具调用微调而设计。原始数据集格式不适用于工具调用训练,因此进行了相应转换,使其更易于 LLaMA 基模型训练。
数据准备
数据集经过重构,以符合 LLaMA 的工具调用要求,确保模型训练无需额外预处理。主要修改包括:
- 将示例格式化为结构化的工具调用提示
- 确保与 LLaMA 的分词器和模型架构兼容
- 改进提示-响应对齐,以便进行监督微调(SFT)
快速入门
使用以下代码加载和使用数据集进行训练:
python import os import json from datasets import load_dataset from transformers import AutoTokenizer
...(代码省略)
基准测试
微调后的模型预计将在工具调用能力上有所提升。将在各种函数调用基准测试后更新基准结果。
关键亮点
- LLaMA 兼容格式:数据集专为 LLaMA 模型设计,无需大量预处理。
- 增强的工具调用支持:旨在提高函数调用性能,这是当前 LLM 应用的关键领域。
- 基于 ToolACE 改编:保持原始 ToolACE 数据集的优点,同时确保与 LLaMA 的可用性。
- 适用于所有支持工具调用的版本:支持 LLaMA 3.1、3.2 和 3.3,具有跨多个版本的通用性。
引用
如果您使用此数据集,请考虑引用 ToolACE:
@misc{toolace, title = {ToolACE: A Dataset for Tool-Calling Evaluation}, url = {https://huggingface.co/datasets/Team-ACE/ToolACE}, author = {Team-ACE}, year = {2024} }
搜集汇总
数据集介绍
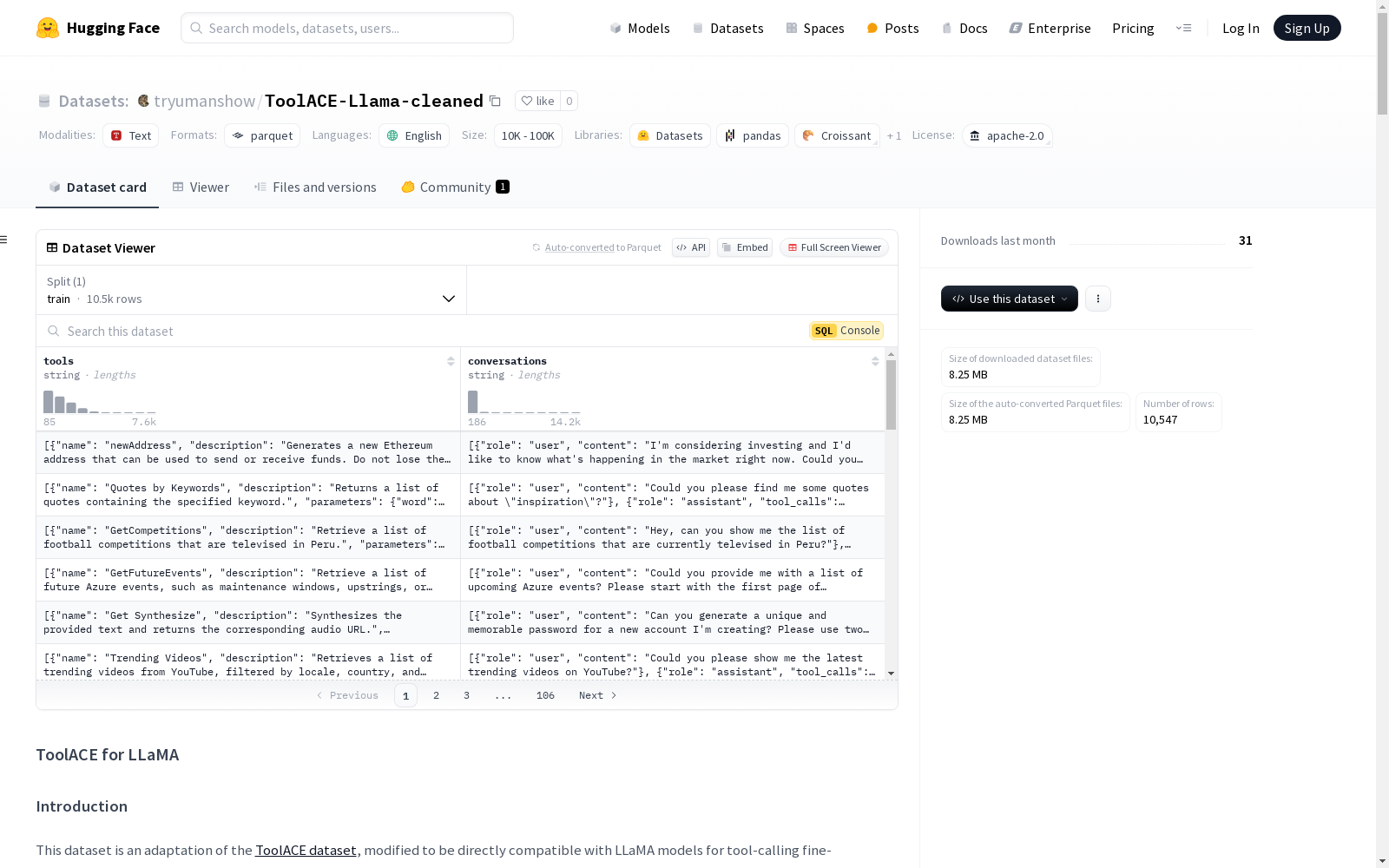
构建方式
ToolACE-Llama-cleaned数据集是对原始ToolACE数据集的改编,专为LLaMA模型进行工具调用微调而设计。该数据集的构建主要包括将原始数据格式转化为LLaMA模型所需的工具调用提示结构,确保与LLaMA的标记器和模型架构兼容,并优化提示-响应对齐,以利于监督微调(SFT)。
特点
该数据集的特点在于其LLaMA兼容格式,无需额外预处理即可用于模型训练。它增强了工具调用支持,针对提高LLM应用中函数调用性能而设计。同时,它继承了ToolACE数据集的优点,并确保了与支持工具调用的所有LLaMA版本兼容。
使用方法
使用该数据集进行训练时,首先需要加载和格式化数据集,使其适应LLaMA模型的训练需求。通过调用相关API并应用特定的数据预处理函数,可以轻松将数据集整合到训练流程中,进而对LLaMA模型进行微调,提升其工具调用能力。
背景与挑战
背景概述
ToolACE-Llama-cleaned数据集是对原始ToolACE数据集的改编,旨在与LLaMA模型直接兼容,以便于工具调用功能的微调。该数据集的创建体现了对现有数据集格式的改进,以满足特定模型的需求。它由Team-ACE团队提供,并适用于所有支持工具调用的LLaMA模型版本,包括3.1、3.2和3.3,确保了其广泛的适用性。此数据集的构建旨在推动LLaMA模型在工具调用能力上的提升,对于自然语言处理领域中的模型训练与评估具有重要意义。
当前挑战
在构建ToolACE-Llama-cleaned数据集的过程中,研究人员面临了将原始数据集格式转换为适合LLaMA模型要求的挑战。这涉及到对示例的格式化,以确保与LLaMA的标记器和模型架构兼容,并提高提示-响应对齐,以利于监督微调(SFT)。此外,数据集在解决领域问题,如工具调用训练中的挑战方面,也显示出其重要性,尤其是在确保模型能够准确理解和执行工具调用任务方面。
常用场景
经典使用场景
ToolACE-Llama-cleaned数据集专为LLaMA模型设计,其经典使用场景在于为工具调用任务提供精细化的训练数据。该数据集通过结构化的工具调用提示,使得LLaMA模型能够学习如何根据上下文有效地调用外部工具,进而提升模型在复杂任务中的表现。
解决学术问题
该数据集解决了自然语言处理领域中的一个重要学术问题,即如何提升大型语言模型在需要外部工具支持的任务中的性能。通过提供兼容LLaMA模型的工具调用数据,研究者能够更好地理解和优化模型在工具调用方面的能力,推动学术界的工具增强型语言模型研究。
衍生相关工作
基于ToolACE-Llama-cleaned数据集的研究成果,衍生出了多项相关工作。这些工作不仅涉及对LLaMA模型工具调用性能的评估和优化,还包括探索如何将工具调用与语言模型结合以解决更多实际问题,为人工智能领域的发展贡献了新的视角和方法。
以上内容由遇见数据集搜集并总结生成


