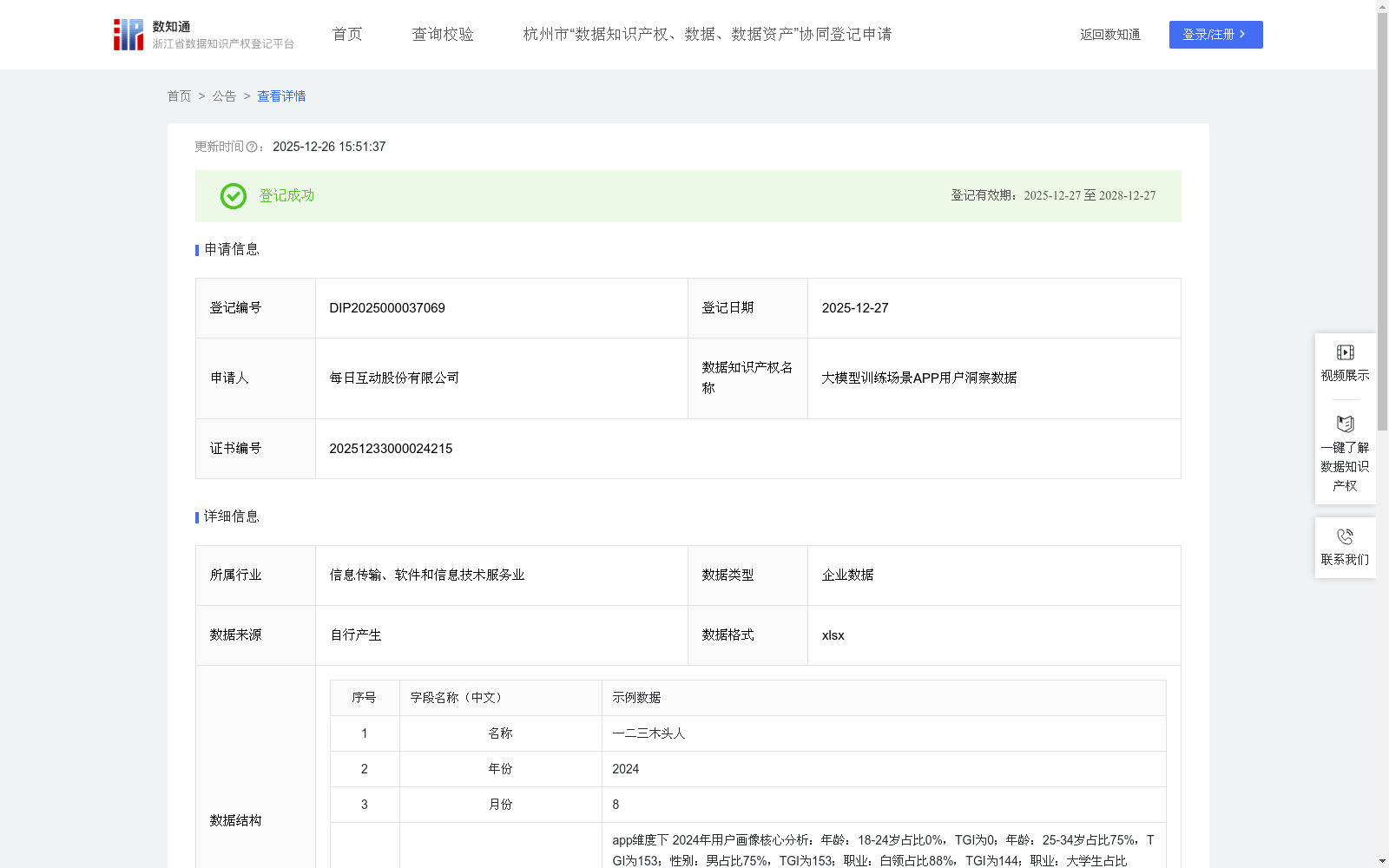
大模型训练场景APP用户洞察数据
收藏浙江省数据知识产权登记平台2025-12-26 更新2025-12-27 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8419558
下载链接
链接失效反馈官方服务:
资源简介:
1、大模型训练场景APP用户洞察数据,通过去标识化、聚合化的数据处理流程,将十亿级用户行为转化为该APP的宏观群体画像。这些高质量的统计数据,使得大语言模型能够直接、高效地学习真实世界的用户分布、社会常识与市场趋势,从而优化其推理能力、校准输出并减少幻觉。本数据作为大模型训练的优质“事实基准”与“认知图谱”,具有很强的复用性,适用于市面上大语言模型的预训练、监督微调与效果评估
2、本报告中详尽的群体统计维度,可以作为重要的特征和基准,直接应用于大模型的训练与优化流程,具体可应用于:体可应用于:
2.1预训练与知识增强:年龄、性别、兴趣等分布字段,为大模型注入社会人口统计学与消费行为学常识,提升其对社会结构的认知准确度
2.2优化对话与推荐能力:TGI等群体偏好指标可构建指令样本,教导模型掌握“量化分析”思维,使其在垂直领域输出更专业的回答
2.3校准输出与评估幻觉:报告数据可作为真实性检验基准,用于量化模型“幻觉”程度,也可接入RAG系统,确保回答基于真实统计
2.4合成高质量模拟对话:依据用户群体特征标签,生成对应群体的模拟对话数据,用于扩展训练集,提升模型与不同用户群体的交互能力。一、数据收集: 通过个推软件开发工具包(SDK)对海量、离散的用户行为数据进行收集。
二、数据处理:对数据进行清洗、脱敏和聚合,所有涉及用户标识的数据均会经过哈希函数进行单向、不可逆的计算,实现了数据的匿名化与去标识化,确保其无法回溯至特定个人。
三、算法加工: 引入机器学习模型进行标签预测:
1.对于无法直接获取的人口属性(如年龄、性别)及深层兴趣偏好,本方案采用预设的机器学习模型进行推断。该模型首先以用户授权的、经脱敏后的跨平台全域APP使用行为数据(即用户对所有可观测应用程序的使用记录)作为输入特征,通过逻辑回归模型,为每个去标识化的用户ID预测其归属于“18-25岁”、“男性”或“美妆兴趣”等特定标签的概率,进行统计聚合,输出出全域(大盘)用户的“年龄分布”、“性别分布”等宏观画像数据
2.基于上述同一模型,对目标APP用户进行标签预测与统计,得出该APP的用户画像数据(即各标签群体在APP中的渗透率)。
3.同时通过计算TGI分步(具体规则在其他说明中),来量化群体特征相对于总体的偏好强度,并将TGI指标作为洞察报告的关键维度之一。
4.以报告形式产出标准化数据资产:基于具体业务场景向大语言模型下达精准指令,该大语言模型通过预训练,能精准生成包含固定框架、动态模块与数据占位符的标准报告模板;随后,通过算法程序,将处理后的数据,转化为格式统一的高质量报告,无缝适配报告模板填充需求,将数据填入到报告模板中。
1. APP User Insight Data for Large Language Model (LLM) Training Scenarios: Through a de-identification and aggregation data processing workflow, billion-level user behavior data is converted into macro-level group portraits of this APP. These high-quality statistical data enable large language models to directly and efficiently learn real-world user distributions, social common sense and market trends, thereby optimizing their reasoning capabilities, calibrating outputs and reducing hallucinations. This data serves as an excellent "factual benchmark" and "cognitive graph" for large model training, with strong reusability, applicable to the pretraining, supervised fine-tuning and performance evaluation of large language models on the market.
2. The detailed group statistical dimensions in this report can serve as important features and benchmarks, directly applied to the training and optimization workflows of large language models, with specific applications as follows:
2.1 Pretraining and Knowledge Enhancement: Distribution fields such as age, gender and interests inject socio-demographic and consumer behavior common sense into large language models, improving their accuracy in understanding social structures.
2.2 Optimizing Dialogue and Recommendation Capabilities: Group preference metrics such as TGI can be used to construct instruction samples, teaching the model to master "quantitative analysis" thinking, enabling it to generate more professional responses in vertical domains.
2.3 Calibrating Outputs and Evaluating Hallucinations: The report data can serve as an authenticity verification benchmark to quantify the degree of model "hallucinations", and can also be integrated into Retrieval-Augmented Generation (RAG) systems to ensure that responses are based on real statistics.
2.4 Generating High-Quality Simulated Dialogues: Simulated dialogue data for corresponding user groups can be generated based on user group feature tags, used to expand the training set and improve the model's interaction capabilities with different user groups.
I. Data Collection: Massive and discrete user behavior data is collected through the GePush Software Development Kit (SDK).
II. Data Processing: Data is cleaned, desensitized and aggregated. All data involving user identifiers will undergo one-way, irreversible hash function calculations, achieving data anonymization and de-identification, ensuring that it cannot be traced back to specific individuals.
III. Algorithm Processing: Machine learning models are introduced for label prediction:
1. For demographic attributes (such as age, gender) and deep-seated interest preferences that cannot be directly obtained, this solution uses pre-trained machine learning models for inference. The model first takes user-authorized and desensitized cross-platform universal APP usage behavior data (i.e., users' usage records of all observable applications) as input features, and uses a logistic regression model to predict the probability that each de-identified user ID belongs to specific labels such as "18-25 years old", "male" or "beauty interest". After statistical aggregation, macro portrait data such as "age distribution" and "gender distribution" of universal (market-wide) users are output.
2. Based on the same model mentioned above, label prediction and statistics are performed on target APP users to obtain user portrait data of this APP (i.e., the penetration rate of each label group in the APP).
3. Meanwhile, the preference strength of group characteristics relative to the overall population is quantified by calculating TGI calculation steps (specific rules are provided in other instructions), and the TGI metric is taken as one of the key dimensions of the insight report.
4. Producing standardized data assets in the form of reports: Precise instructions are sent to the large language model based on specific business scenarios. This pre-trained large language model can accurately generate standard report templates containing fixed frameworks, dynamic modules and data placeholders; subsequently, through algorithmic procedures, the processed data is converted into high-quality reports with unified formats, which seamlessly adapt to the filling requirements of the report templates, and the data is inserted into the report templates.
提供机构:
每日互动股份有限公司
创建时间:
2025-12-04
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集提供大模型训练场景下的APP用户洞察数据,包含500条记录,每月更新,以xlsx格式呈现。它通过去标识化和聚合化处理,将十亿级用户行为转化为宏观群体画像,涵盖年龄、性别、职业、消费水平等统计维度,并利用TGI指标量化群体偏好。这些数据适用于大语言模型的预训练、监督微调、效果评估和优化对话能力,旨在提升模型对社会结构和市场趋势的认知准确性。
以上内容由遇见数据集搜集并总结生成


