WM4VLA_benchmark_v4
收藏Hugging Face2026-04-18 更新2026-04-19 收录
下载链接:
https://huggingface.co/datasets/masterwu/WM4VLA_benchmark_v4
下载链接
链接失效反馈官方服务:
资源简介:
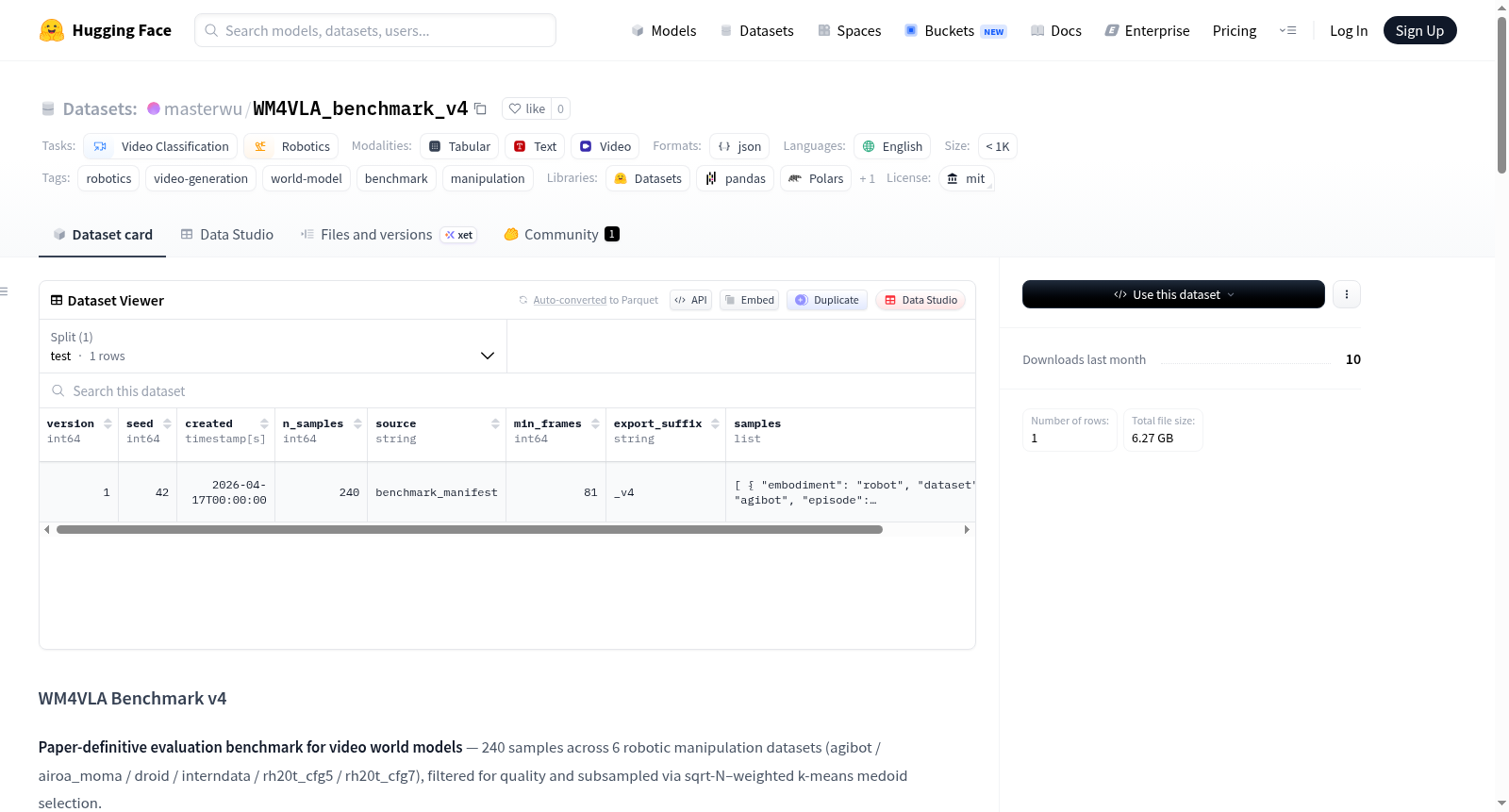
WM4VLA Benchmark v4 是一个专为视频世界模型设计的评估基准数据集,包含来自6个机器人操作数据集(agibot、airoa_moma、droid、interndata、rh20t_cfg5、rh20t_cfg7)的240个高质量样本。这些样本经过筛选和子采样,确保数据质量和多样性。每个样本包含81帧视频,分辨率为480×640,帧率因数据集而异。数据集还包括骨架渲染的夹持器/手臂投影视频、文本描述、元数据(如末端执行器位姿、关节角度、夹持器开合度等)以及可选的调试叠加视频。数据集适用于视频分类、机器人操作、视频生成等任务,并提供详细的评估协议和指标(如PSNR、SSIM、LPIPS、FVD等)。数据集采用MIT许可证,但需注意上游数据集的许可条款。
创建时间:
2026-04-17
原始信息汇总
WM4VLA Benchmark v4 数据集概述
基本信息
- 数据集名称:WM4VLA Benchmark v4
- 许可证:MIT
- 主要任务类别:视频分类、机器人学
- 语言:英语
- 标签:机器人学、视频生成、世界模型、基准测试、操作
- 数据规模:小于1K样本
- 磁盘大小:约6.7 GB
数据集构成
- 总样本数:240个
- 源数据集数量:6个(agibot, airoa_moma, droid, interndata, rh20t_cfg5, rh20t_cfg7)
- 各数据集样本分配:
- agibot: 77
- airoa_moma: 35
- droid: 54
- interndata: 30
- rh20t_cfg5: 23
- rh20t_cfg7: 21
- 每个样本帧数:81帧(已对齐,确保第0帧满足手臂可见性条件)
- 视频分辨率:480 × 640
- 帧率:遵循源数据集原生帧率(agibot 15 FPS, airoa 30 FPS, rh20t_cfg5 12 FPS, rh20t_cfg7 10 FPS, droid 14 FPS, interndata 30 FPS)
数据来源与处理流程
- 基准版本:v4,取代已归档的v1版本(masterwu/WM4VLA_benchmark)。
- 筛选流程:
- 从v1池(1000个样本)开始。
- 应用v3协议的筛选器:要求
num_frames ≥ 81,并对gripper_scenario.mp4应用手臂可见性三元组条件(T0, T1, R),扫描最多200帧以找到最早的有效窗口。 - 对有效窗口起始帧非0的样本,使用ffmpeg(libx264 crf=18)重新编码,修剪偏移量存储在
arm_visibility_v4.json中。 - 重新编码后进行完整性检查,失败样本由次优幸存样本替换,以恢复各数据集分配数量。
- 使用sqrt-N加权k-means中心点选择法,将总样本数子采样至240个,并按最大余数法分配至各数据集。
- 筛选后样本数:823个样本通过筛选,最终子采样至240个。
样本文件结构
每个样本位于{dataset}/{episode}/{camera}/目录下,包含:
rgb.mp4:H.264编码,480×640分辨率,81帧,源数据集帧率。gripper_scenario.mp4:用于手臂可见性和感兴趣区域渲染的骨架投影视频。caption.pickle:包含"caption"等键的字典。episode_meta.npz:包含每帧的末端执行器位姿(4×4矩阵)、关节角度、夹持器开合度、相机内参和外参。overlay.mp4:可选的调试叠加视频(rgb + gripper_scenario),约163/240个样本包含此文件。- 注意:agibot数据集使用双臂键名(
ee_pose_left/ee_pose_right等),其他数据集使用单臂键名(ee_pose等)。
关键文件
benchmark_eval_split_v4.json:包含240个样本的扁平列表,每个条目有{embodiment, dataset, episode, camera, data_root}字段,用于基准适配器。benchmark_manifest.json:各数据集的导出摘要(计数、回填、修剪统计信息)。
评估协议
- 输入窗口:
rgb.mp4从第0帧开始的前81帧。 - 度量窗口:真实输出和生成输出的前49帧(生成后切片),遵循Kinema4D惯例。
- 跳过第0帧:在逐帧PSNR/SSIM/LPIPS计算中跳过第0帧(因其为I2V输入图像)。
- 评估指标:
- PSNR(越高越好)
- SSIM(越高越好)
- LPIPS(越低越好,AlexNet骨干网络)
- FVD(越低越好,I3D Kinetics-400)
- FID(越低越好,InceptionV3)
- Latent L2(越低越好,Wan2.1 VAE)
- tLPIPS(越低越好,连续生成帧间的时序LPIPS,无需真实数据)
- 报告层级:
- PSNR/SSIM/LPIPS/tLPIPS/Latent L2:总体 + 每个实施方式 + 每个数据集
- FVD/FID:总体 + 每个实施方式(每个数据集样本数约30-80,低于FID/FVD经验稳定性阈值)
引用格式
bibtex @dataset{masterwu_wm4vla_benchmark_v4_2026, author = {wuzy2115}, title = {WM4VLA Benchmark v4}, year = {2026}, url = {https://huggingface.co/datasets/masterwu/WM4VLA_benchmark_v4}, }
版本历史
- v4 (2026-04-17):当前版本。对v1池应用手臂可见性筛选和最小帧数≥81条件,子采样至240个样本,对修剪样本重新编码,进行修剪后完整性检查和回填以恢复各数据集分配。为每个样本添加
episode_meta.npz。 - v1 (2026-04-12):已归档。1000个样本,未筛选池。存档于https://huggingface.co/datasets/masterwu/WM4VLA_benchmark。
搜集汇总
数据集介绍
构建方式
在机器人操作视频世界模型评估领域,WM4VLA Benchmark v4的构建体现了严谨的数据筛选与优化流程。该数据集从六个机器人操作数据集中初选1000个样本作为原始池,随后应用了基于臂部可见性的三重过滤标准,确保样本在视觉上具有足够的操作信息与连续性。通过最小帧数要求与窗口内像素变化比率的约束,筛选出823个合格样本,并采用基于平方根加权的k-means中值选择法,最终精炼为240个代表性样本,同时保持了各源数据集的分布平衡。
使用方法
使用该数据集进行模型评估时,研究者需加载benchmark_eval_split_v4.json文件以获取样本列表。每个样本的rgb.mp4文件作为模型输入,其对应的episode_meta.npz文件提供机器人状态信息。模型应生成81帧预测视频,评估窗口聚焦于前49帧,并需跳过第0帧以避免平凡度量结果。输出结果需按照指定的目录结构保存,便于后续自动化计算各类视觉质量与时间一致性指标。
背景与挑战
背景概述
在机器人操作与视频生成交叉领域,世界模型作为预测动态环境的关键技术,其评估长期缺乏标准化基准。WM4VLA Benchmark v4由研究人员wuzy2115于2026年创建,旨在为视频世界模型提供权威性评估框架。该数据集整合了六个异构机器人操作数据集,通过严格的质控与采样策略,构建了包含240个高质量样本的测试集。其核心研究问题聚焦于提升世界模型在复杂操作场景中的视频预测准确性,推动了具身智能与生成模型在真实物理交互中的可复现性研究。
当前挑战
该数据集致力于解决机器人操作视频预测的领域挑战,包括模型对多臂系统、不同相机视角及动态物体交互的泛化能力。构建过程中面临多重困难:需从原始数据中筛选出满足最小帧数及机械臂可见性约束的样本,涉及复杂的视觉阈值设计与窗口扫描算法;同时,保持各源数据集的比例平衡,需采用基于平方根加权的k-means中值选择进行子采样,并处理因重新编码导致的样本失效问题,通过后备样本替换确保数据集的完整性。
常用场景
经典使用场景
在机器人操作与视频生成交叉领域,WM4VLA Benchmark v4作为世界模型评估的权威基准,其经典使用场景聚焦于视频预测任务的系统性评测。该数据集通过精心筛选的240个样本,覆盖六种机器人操作数据集,为研究者提供了标准化的输入窗口与度量框架。模型以初始81帧视频作为条件,生成后续帧序列,并在49帧的度量窗口内计算多种视觉质量指标,从而客观比较不同世界模型在复杂动态环境中的预测能力。
解决学术问题
该数据集有效解决了机器人学与计算机视觉中视频世界模型评估缺乏统一标准的核心问题。通过整合多源机器人操作数据并实施严格的样本过滤与子采样策略,它确保了评估样本的质量与多样性。其意义在于为学术界提供了可复现、可比较的评测协议,推动了世界模型在长时序预测、物理交互理解等关键研究方向上的进展,显著提升了该领域方法迭代的严谨性与效率。
实际应用
在实际应用层面,WM4VLA Benchmark v4直接服务于机器人仿真与自主系统开发。基于该数据集训练和评估的世界模型,能够赋能机器人进行更精准的任务规划与决策,例如在非结构化环境中预测物体运动轨迹或自身操作后果。这为开发更智能、更可靠的工业机械臂、家庭服务机器人乃至自动驾驶系统提供了关键的视频预测能力验证基础,加速了从实验室研究到现实部署的转化进程。
数据集最近研究
最新研究方向
在机器人操作与视觉学习交叉领域,WM4VLA Benchmark v4作为视频世界模型的权威评估基准,正推动着生成式人工智能在具身智能中的前沿探索。该数据集通过整合六个异构机器人操作数据集并应用严格的质控筛选,专注于提升视频预测模型的泛化能力与物理一致性。当前研究热点集中于利用其多模态元数据(如末端执行器姿态、关节角度)开发能够理解复杂操作场景的动态世界模型,这些模型在模拟真实世界交互、减少仿真到现实差距方面展现出关键意义。同时,数据集支持的多样化评估指标(如FVD、tLPIPS)促进了生成视频的时空连贯性与视觉保真度的量化比较,为自动驾驶、工业自动化等领域的决策系统提供了可验证的仿真基础。
以上内容由遇见数据集搜集并总结生成


