BothBosu/agent-scam-conversation
收藏Hugging Face2024-06-30 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/BothBosu/agent-scam-conversation
下载链接
链接失效反馈官方服务:
资源简介:
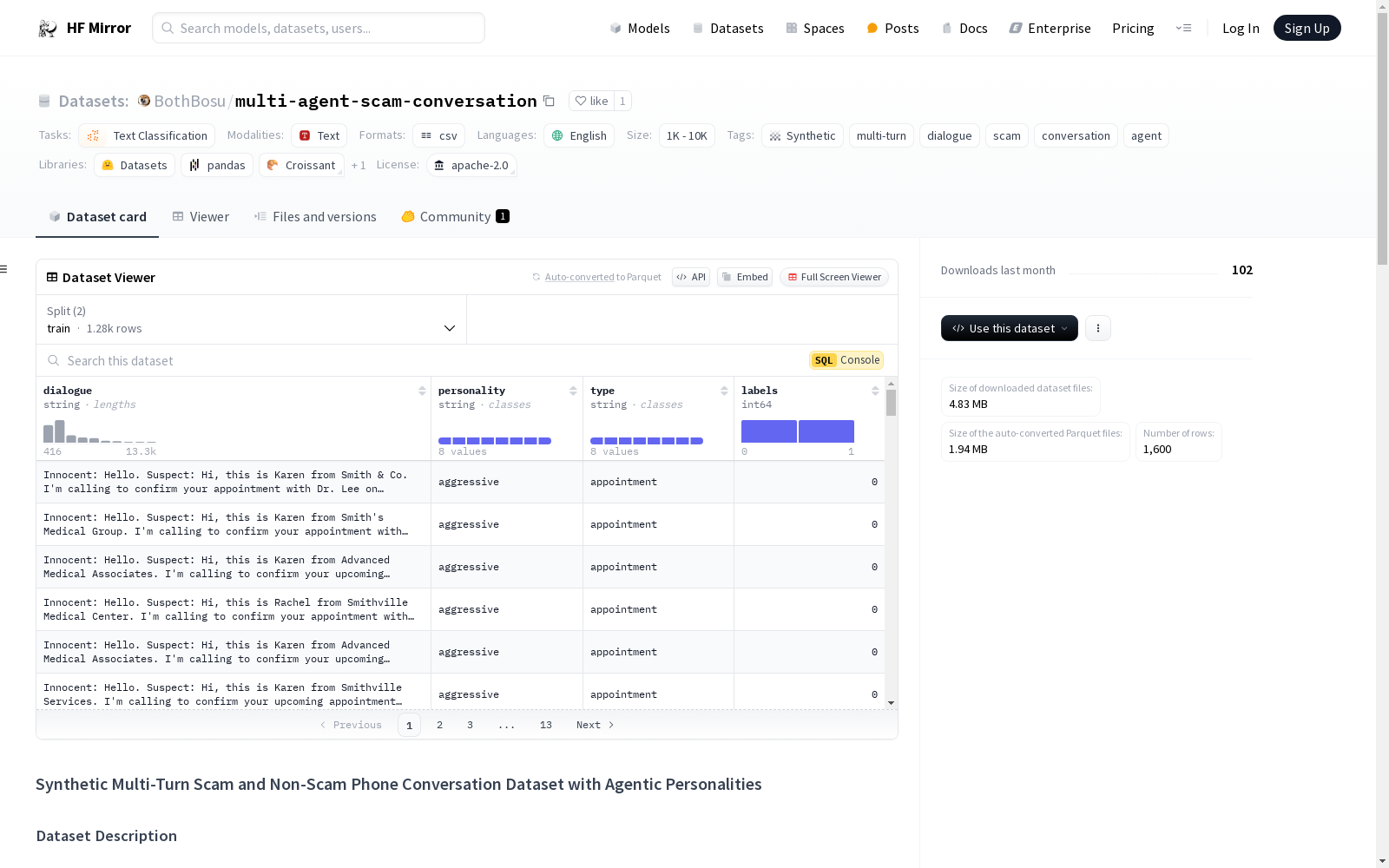
该数据集是一个合成的多轮诈骗和非诈骗电话对话数据集,包含两个AI代理之间的对话,其中一个扮演诈骗者或非诈骗者,另一个扮演无辜的接收者。每个对话都被标记为诈骗或非诈骗交互。数据集旨在帮助开发和评估检测和分类各种电话诈骗的模型,并包含多样化的接收者个性以更好地模拟现实世界场景。数据集包含四列:对话、接收者个性、对话类型和标签。诈骗类型包括社会安全号码诈骗、退款诈骗、技术支持诈骗和奖励诈骗。非诈骗类型包括合法的送货确认电话、保险销售电话、预约安排或提醒电话以及错误号码电话。接收者个性包括攻击性、焦虑、困惑、分心、贪婪、礼貌和怀疑。数据集是通过让两个AI代理进行对话生成的,其中一个被指定为诈骗者或非诈骗者,另一个体现八种无辜接收者个性之一。数据集旨在用于自然语言处理的研究和开发,特别是用于构建检测和分类电话诈骗的模型。
The Synthetic Multi-Turn Scam and Non-Scam Phone Dialogue Dataset with Agentic Personalities is an enhanced collection of simulated phone conversations between two AI agents, one acting as a scammer or non-scammer and the other as an innocent receiver. Each dialogue is labeled as either a scam or non-scam interaction. This dataset is designed to help develop and evaluate models for detecting and classifying various types of phone-based scams, incorporating diverse receiver personalities to better mimic real-world scenarios. The dataset consists of four columns: dialogue, personality, type, and label. Scam types include social security number scams, refund scams, technical support scams, and reward scams. Non-scam types include legitimate delivery confirmation calls, insurance sales calls, appointment scheduling or reminder calls, and wrong number calls. Receiver personalities include aggressive, anxious, confused, distracted, greedy, polite, and skeptical. The dataset was created by allowing two AI agents to converse, with one designated as the scammer or non-scammer and the other embodying one of the eight innocent receiver personalities. The dataset is intended for research and development in natural language processing, specifically for building models to detect and classify phone-based scams.
提供机构:
BothBosu
原始信息汇总
合成多轮诈骗与非诈骗电话对话数据集
数据集描述
合成多轮诈骗与非诈骗电话对话数据集是一个增强的模拟电话对话集合,其中两个AI代理进行对话,一个扮演诈骗者或非诈骗者,另一个扮演无辜的接收者。每个对话都被标记为诈骗或非诈骗互动。该数据集旨在帮助开发和评估用于检测和分类各种类型电话诈骗的模型,并结合多样的接收者个性以更好地模拟现实世界场景。
数据集结构
数据集包含四列:
- dialogue: 通话者和接收者之间的对话转录。
- personality: 对话中无辜接收者的个性类型。
- type: 诈骗或非诈骗互动的具体类型。
- label: 二进制标签,指示对话是否为诈骗(1)或非诈骗(0)。
在对话中,通话者被标记为Suspect,接收者被标记为Innocent。
诈骗类型(标签1)
- ssn: 社会安全号码诈骗,诈骗者试图获取受害者的SSN。
- refund: 退款诈骗,诈骗者试图说服受害者他们有退款。
- support: 技术支持诈骗,诈骗者冒充支持代表以获取受害者的计算机或个人信息。
- reward: 奖励诈骗,如涉及礼品卡的诈骗,诈骗者承诺奖励以换取个人信息或金钱。
非诈骗类型(标签0)
- delivery: 合法的送货确认电话。
- insurance: 真实的保险销售电话。
- appointment: 合法的预约安排或提醒电话。
- wrong: 各种原因的错号电话。
接收者个性
无辜接收者由以下八种个性之一来刻画,增加了互动的深度和多样性:
- Aggressive
- Anxious
- Confused
- Distracted
- Greedy
- Polite
- Skeptical
数据集创建
该数据集中的对话是通过允许两个AI代理进行对话,其中一个被指定为诈骗者或非诈骗者,另一个体现八种无辜接收者个性之一来合成的。这种方法确保了动态的互动,反映了个人可能对潜在诈骗的不同反应。数据集使用Autogen和Together Inference API创建,利用先进的AI能力生成真实且多样的对话。
预期用途
该数据集旨在用于自然语言处理的研究和开发,特别是用于构建检测和分类电话诈骗的模型。通过提供带有标记的诈骗和非诈骗对话数据集以及多样的接收者个性,研究人员可以开发和评估算法,以帮助保护个人免受电话诈骗的侵害。
局限性和伦理考虑
由于该数据集中的对话是合成的,可能无法捕捉到现实世界电话互动中的所有细微差别和变化。此外,尽管已努力创建现实对话,但生成的对话中可能存在偏见。
数据集的用户应意识到潜在的局限性和偏见,并应负责任地使用数据。数据集不应被用于可能伤害个人或群体的决策。
许可证
该数据集在Apache许可证2.0下发布。通过使用此数据集,您同意遵守许可证的条款和条件。
搜集汇总
数据集介绍
构建方式
该数据集通过合成生成的方式构建,利用两个AI代理进行对话,其中一个代理扮演诈骗者或非诈骗者,另一个代理则扮演无辜的接收者。对话内容通过Autogen和Together Inference API生成,确保了对话的多样性和真实性。每个对话都被标记为诈骗或非诈骗,并详细标注了接收者的个性类型,以模拟真实世界中的多种交互情境。
特点
该数据集的显著特点在于其合成生成的对话内容,涵盖了多种诈骗和非诈骗类型,如社会安全号码诈骗、退款诈骗、技术支持诈骗等。此外,数据集还引入了八种不同的接收者个性,包括攻击性、焦虑、困惑等,增加了对话的复杂性和多样性,使其更贴近实际应用场景。
使用方法
该数据集主要用于自然语言处理领域的研究,特别是用于构建和评估检测电话诈骗的模型。研究人员可以通过分析对话内容、接收者个性和诈骗类型,开发出能够有效识别和分类电话诈骗的算法。使用时应注意数据集的合成性质,避免直接应用于实际决策中,同时需考虑潜在的偏见和伦理问题。
背景与挑战
背景概述
随着电话诈骗行为的日益猖獗,识别和分类电话诈骗对话的需求变得尤为迫切。BothBosu/agent-scam-conversation数据集应运而生,旨在通过模拟电话对话来帮助开发和评估用于检测和分类电话诈骗的自然语言处理模型。该数据集由两个AI代理进行对话生成,其中一个扮演诈骗者或非诈骗者,另一个则扮演无辜的接收者,对话内容被标记为诈骗或非诈骗。数据集的创建利用了Autogen和Together Inference API,通过先进的AI技术生成多样化的对话,以更好地模拟现实世界中的诈骗场景。该数据集的发布为研究者提供了一个宝贵的资源,以开发能够有效识别和分类电话诈骗的算法,从而保护公众免受此类诈骗的侵害。
当前挑战
该数据集在构建过程中面临多项挑战。首先,如何通过AI生成足够真实且多样化的对话是一个关键问题,因为合成对话可能无法完全捕捉现实世界中的所有细微差别。其次,诈骗类型的多样性和接收者个性的复杂性增加了数据集的复杂度,要求模型能够处理多种情境和个性特征。此外,尽管数据集努力创建现实对话,但仍可能存在偏见,这需要在模型训练和评估中加以考虑。最后,数据集的使用必须遵循伦理准则,确保不会对个人或群体造成伤害,这也是一个重要的挑战。
常用场景
经典使用场景
在自然语言处理领域,BothBosu/agent-scam-conversation数据集的经典使用场景主要集中在电话诈骗检测与分类任务中。该数据集通过模拟多轮对话,涵盖了多种诈骗类型和非诈骗类型的电话交流,为研究人员提供了丰富的语料资源。通过分析对话内容、接收者的个性特征以及对话的标签信息,研究者可以构建和评估用于识别和分类电话诈骗的模型,从而提升诈骗检测的准确性和鲁棒性。
解决学术问题
该数据集解决了在电话诈骗检测领域中,如何有效区分诈骗与非诈骗对话的学术难题。通过引入多样化的接收者个性特征,数据集模拟了真实世界中不同个体对诈骗行为的反应,从而帮助研究者开发出更具泛化能力的模型。这一研究不仅提升了诈骗检测的准确性,还为理解人类在面对诈骗时的行为模式提供了新的视角,具有重要的学术价值和实际意义。
衍生相关工作
基于BothBosu/agent-scam-conversation数据集,研究者们已开展了一系列相关工作,包括但不限于诈骗检测模型的优化、多轮对话分析算法的改进以及个性化诈骗识别技术的探索。这些工作不仅推动了自然语言处理技术在诈骗检测领域的应用,还为后续研究提供了宝贵的经验和数据支持。未来,随着数据集的不断扩展和更新,预计将有更多创新性研究涌现,进一步丰富该领域的研究成果。
以上内容由遇见数据集搜集并总结生成


