test
收藏Hugging Face2025-08-21 更新2025-08-22 收录
下载链接:
https://huggingface.co/datasets/mkzheng/test
下载链接
链接失效反馈官方服务:
资源简介:
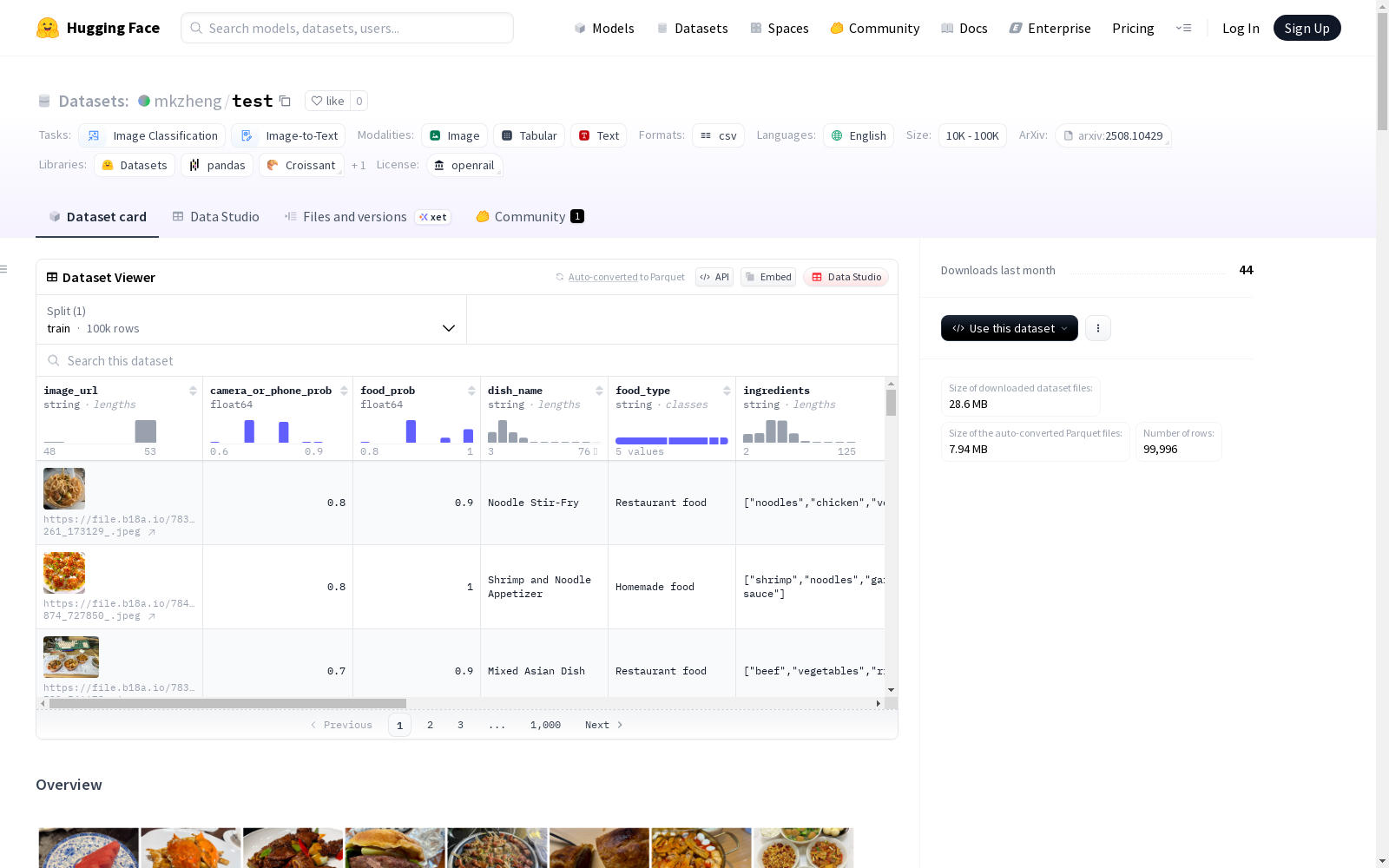
这是一个包含10万张高质量食物图像的综合性数据集,旨在为计算机视觉任务提供支持,特别是食物识别、分类和营养分析。数据集包含详细的元数据,包括食材、分量大小、营养成分、烹饪方法等信息,以支持更复杂的AI应用。数据集适合用于食物识别、营养估算、食谱推荐、健康管理、餐厅自动化和计算机视觉研究。
创建时间:
2025-08-21
搜集汇总
数据集介绍
构建方式
在食品计算机视觉研究领域,数据集的构建质量直接决定了模型的泛化能力。本数据集采用创新的混合标注流程,首先通过Booster活动收集了120万张由真实用户贡献的食品图像,经过严格清洗保留100万张高质量样本。随后由专业标注团队进行预标注,涵盖区域划分、食物名称及份量信息,再通过GPT-4o和Qwen-max-latest多模态模型进行自动化深度标注,最终由人工完成二次评估与质量校验,确保营养成分等关键数据的精确性。
特点
该数据集在食品智能分析领域展现出显著优势,包含10万张高质量图像并配备多维结构化元数据。其核心特征在于突破传统单一图像分类模式,提供食材清单、精确克重、营养成分及烹饪方法等深度标注信息。数据覆盖自制食品、餐厅菜品、生鲜蔬果及包装食品四大类型,且通过概率指标区分用户拍摄与网络下载图像源,有效提升真实场景下的模型适应性。
使用方法
研究者可通过HuggingFace平台直接加载数据集,利用其多模态特性开展食品识别与分类模型训练。每条数据包含图像URL及结构化JSON元数据,支持端到端的营养成分估算、智能菜谱推荐等应用开发。数据集采用OpenRAIL-M许可证开放非商业使用,商业应用需联系授权,为食品AI创新研究提供坚实基础支撑。
背景与挑战
背景概述
随着人工智能在健康饮食领域的深入应用,食品图像数据集成为计算机视觉研究的重要基础。MM-Food-100K数据集由Codatta与Binance通过Booster活动合作构建,汇集了来自近5万名真实用户提交的120万张食品图像,经过严格筛选后形成百万级样本库。该数据集专注于解决全球食品多样性识别与营养分析的核心问题,通过融合多模态标注信息(包括成分、重量、营养数据和烹饪方法),为智能膳食管理、健康监测系统提供高质量数据支撑,显著推动了食品AI领域的研究进程。
当前挑战
食品智能分析面临现实场景中食品种类繁多、地域差异显著的识别挑战,现有模型对亚洲菜肴的营养估算误差率高达76%,且难以准确估计食物份量。数据集构建过程中需克服大规模图像采集的质量控制难题,包括模糊图像过滤、多源数据整合以及复杂标注体系的一致性维护。此外,自动化标注依赖GPT-4o等大型模型生成成分与营养数据,需通过人工二次评估确保 annotations 的准确性,这对数据验证流程提出了极高要求。
常用场景
经典使用场景
在计算机视觉与营养健康交叉领域,该数据集为食品图像识别与分类提供了重要基准。其十万级样本规模与多模态标注结构,特别适用于训练深度神经网络进行细粒度食品识别,包括对亚洲菜肴等多样化饮食文化的精准分类。通过结合图像与结构化元数据,研究者能够开发出在复杂真实场景中仍保持高准确率的食品识别模型。
实际应用
在实际应用层面,该数据集支撑了智能健康管理系统的开发,用户通过拍摄餐食照片即可获得精准的营养成分分析与热量计算。餐厅自动化系统利用其训练视觉识别模块,实现智能点餐与食品推荐。医疗健康领域则依托该数据开发饮食监控工具,为糖尿病等慢性病患者提供个性化的膳食管理方案。
衍生相关工作
基于该数据集衍生的经典工作包括多模态食品分析模型MMFoodNet,其融合视觉与文本特征实现成分解析;营养估算系统NutriEstimate通过深度学习预测食物热量与宏量营养素;以及跨文化食品识别框架GlobalFoodRecog,专门针对亚洲菜肴的识别难题进行优化。这些工作显著推动了食品AI在真实场景中的应用进展。
以上内容由遇见数据集搜集并总结生成


