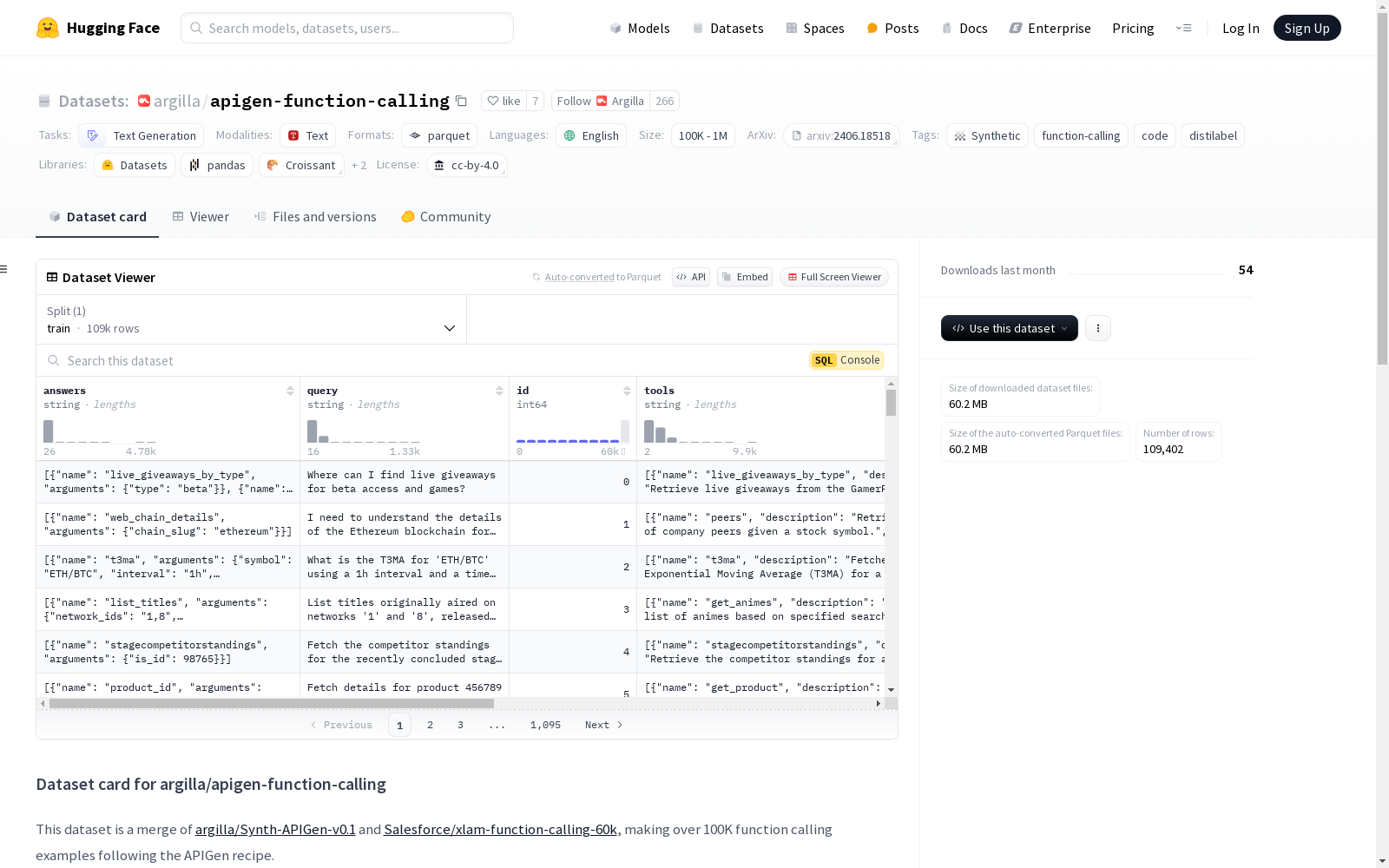
apigen-function-calling
收藏数据集概述
基本信息
- 数据集名称: argilla/apigen-function-calling
- 数据集大小: 165,059,162 字节
- 下载大小: 60,235,594 字节
- 语言: 英语 (en)
- 许可证: CC BY 4.0
- 任务类别: 文本生成 (text-generation)
- 标签: 合成数据 (synthetic), 函数调用 (function-calling), 代码 (code), distilabel
- 数据集规模: 100K < n < 1M
数据集结构
特征 (Features)
- answers: 字符串 (string)
- query: 字符串 (string)
- id: 整数 (int64)
- tools: 字符串 (string)
- func_name: 字符串 (string)
- func_desc: 字符串 (string)
- hash_id: 字符串 (string)
- model_name: 字符串 (string)
- origin: 字符串 (string)
数据分割 (Splits)
- train: 包含 109,402 个样本,占用 165,059,162 字节
配置 (Configs)
- default: 包含训练数据文件,路径为
data/train-*
数据集来源
- 该数据集是 argilla/Synth-APIGen-v0.1 和 Salesforce/xlam-function-calling-60k 的合并,包含超过 100K 的函数调用示例。
示例
json { "answers": "[{"name": "split_list", "arguments": {"lst": [10, 20, 30, 40, 50, 60], "chunk_size": 4}}, {"name": "binary_search", "arguments": {"arr": [10, 20, 30, 40, 50, 60], "target": 30}}]", "query": "Please split the list [10, 20, 30, 40, 50, 60] into chunks of size 4, and also find the index of 30 in this list.", "id": 1234, "tools": "[{"name": "split_list", "description": "Splits a list into chunks of a specified size.", "parameters": {"lst": {"description": "The input list.", "type": "List"}, "chunk_size": {"description": "The size of each chunk.", "type": "int"}}}, {"name": "binary_search", "description": "Performs binary search on a sorted list to find the index of a target value.", "parameters": {"arr": {"description": "The sorted list of integers.", "type": "List[int]"}, "target": {"description": "The target value to search for.", "type": "int"}}}]", "func_name": null, "func_desc": null, "hash_id": null, "model_name": null, "origin": "xLAM" }