Babillage
收藏Hugging Face2025-03-21 更新2025-03-22 收录
下载链接:
https://huggingface.co/datasets/kyutai/Babillage
下载链接
链接失效反馈官方服务:
资源简介:
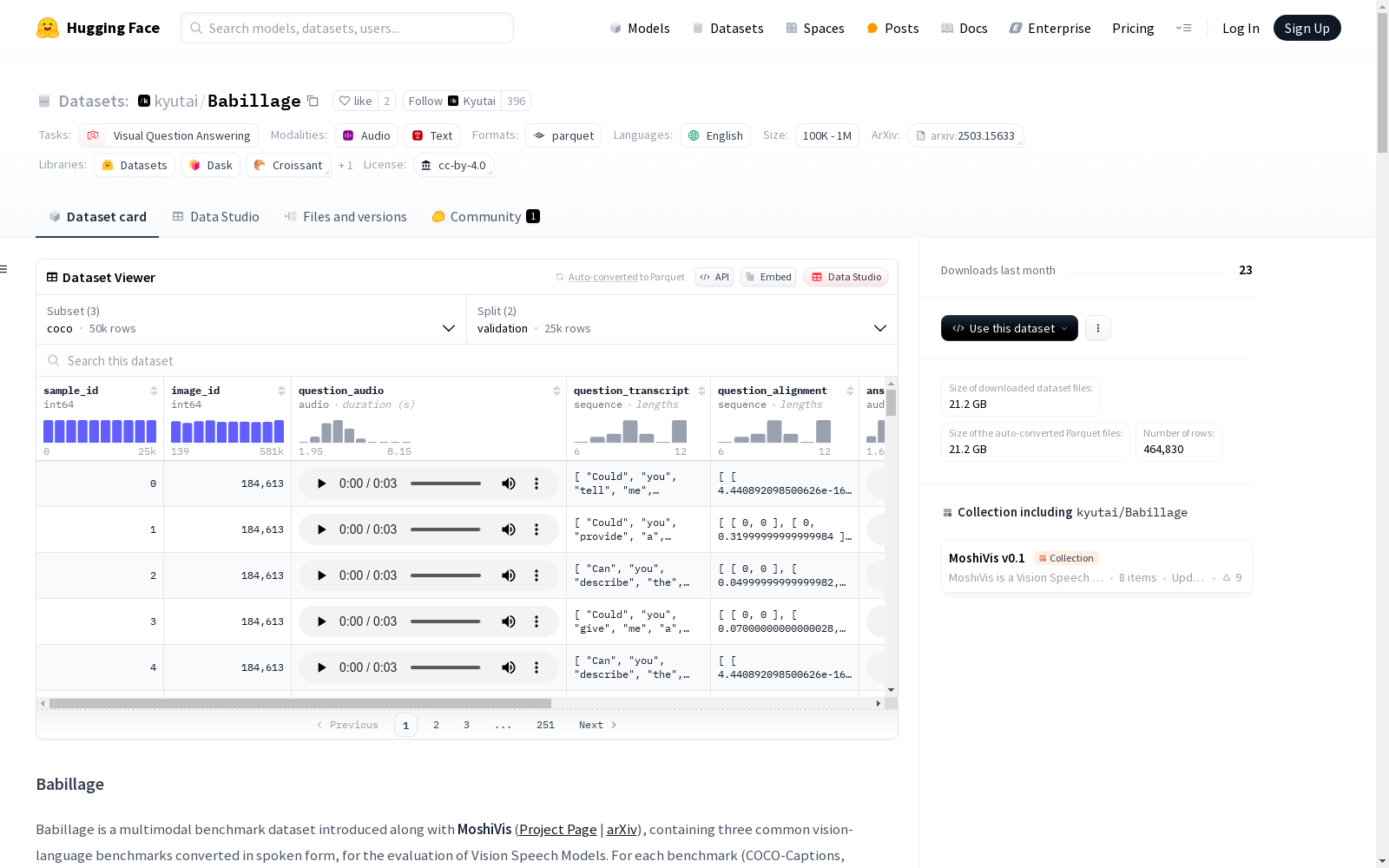
Babillage是一个多模态基准数据集,包含三种常见的视觉语言基准(COCO-Captions、OCR-VQA、VQAv2),转换为口语形式,用于评估视觉语音模型。对于每个基准,首先将文本问答对重新格式化为更对话式的风格,然后通过文本到语音管道进行转换,使用一致的合成声音回答(助手)和多种多样的声音提问(用户)。数据集提供了生成的口语样本,旨在用于会话AI、口语视觉问答和多模态对话系统的研究。
创建时间:
2025-03-17
搜集汇总
数据集介绍
构建方式
Babillage数据集的构建基于三个常见的视觉-语言基准(COCO-Captions、OCR-VQA、VQAv2),通过将文本问答对重新格式化为对话形式,并利用文本到语音的转换管道生成语音样本。数据集中的问题语音由多样化的声音生成,而回答语音则采用一致的合成声音。这一构建方式旨在为视觉-语音模型的研究提供多模态对话系统的评估基准。
特点
Babillage数据集的特点在于其多模态性,结合了文本、语音和图像三种模态。每个样本包含问题的音频形式、文本转录及其时间对齐信息,部分样本还包含回答的音频及其对齐信息。数据集涵盖了COCO、OCR-VQA和VQAv2三个子集,分别针对图像描述、基于OCR的视觉问答和通用视觉问答任务,提供了丰富的对话式交互数据。
使用方法
Babillage数据集的使用方法包括加载数据集并与原始视觉-语言数据集进行合并,以映射音频样本与对应图像及真实标签。用户可以通过提供的代码片段将音频文件转换为未压缩的WAV格式,并展示样本内容。数据集支持通过Hugging Face的`datasets`库加载,并提供了与COCO、OCR-VQA和VQAv2原始数据的集成示例,便于用户进行多模态对话系统的研究与开发。
背景与挑战
背景概述
Babillage数据集是由Kyutai团队于2025年推出的多模态基准数据集,旨在评估视觉语音模型(Vision Speech Models)的性能。该数据集基于三个常见的视觉-语言基准任务(COCO-Captions、OCR-VQA、VQAv2),通过将文本形式的问答对转换为对话形式,并利用文本到语音技术生成语音样本。数据集的设计初衷是推动对话式人工智能、语音问答系统以及多模态对话系统的研究。Babillage的推出标志着视觉与语音结合的研究进入了一个新的阶段,为相关领域的研究者提供了丰富的实验数据。
当前挑战
Babillage数据集面临的挑战主要体现在两个方面。首先,在领域问题方面,视觉语音模型需要同时处理图像、文本和语音信息,这对模型的跨模态理解能力提出了极高的要求。如何准确地将视觉信息与语音信息对齐,并生成符合上下文的语音回答,是一个亟待解决的核心问题。其次,在数据集构建过程中,如何确保语音样本的自然性和多样性,同时保持与原始文本数据的一致性,也是一个技术难点。此外,数据集的规模较大,处理和分析这些多模态数据对计算资源的需求也构成了挑战。
常用场景
经典使用场景
Babillage数据集在视觉语音模型的研究中扮演了重要角色,尤其是在多模态对话系统和视觉问答(VQA)领域。该数据集通过将COCO、OCR-VQA和VQAv2等经典视觉语言基准转换为语音形式,为研究者提供了一个全新的评估平台。其独特之处在于将文本问题-答案对重新格式化为对话形式,并通过语音合成技术生成多样化的语音样本,从而模拟真实的人机对话场景。
实际应用
在实际应用中,Babillage数据集为智能助手、语音交互系统和多模态对话系统的开发提供了重要支持。例如,在智能家居场景中,用户可以通过语音与设备进行交互,询问关于图像内容的问题,如“这张照片中有哪些物体?”或“这张图片中的文字是什么?”。Babillage的语音问答功能使得这些应用更加自然和高效,极大地提升了用户体验。
衍生相关工作
Babillage数据集的推出催生了一系列相关研究,尤其是在多模态对话系统和视觉语音模型领域。例如,基于Babillage的研究工作探索了如何更好地对齐语音与视觉信息,以及如何生成更加自然的对话响应。此外,该数据集还被用于训练和评估多模态预训练模型,如MoshiVis,这些模型在视觉问答和对话生成任务中表现出色,进一步推动了多模态学习的发展。
以上内容由遇见数据集搜集并总结生成


