NEUDM/aste-data-v2
收藏Hugging Face2023-05-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/NEUDM/aste-data-v2
下载链接
链接失效反馈官方服务:
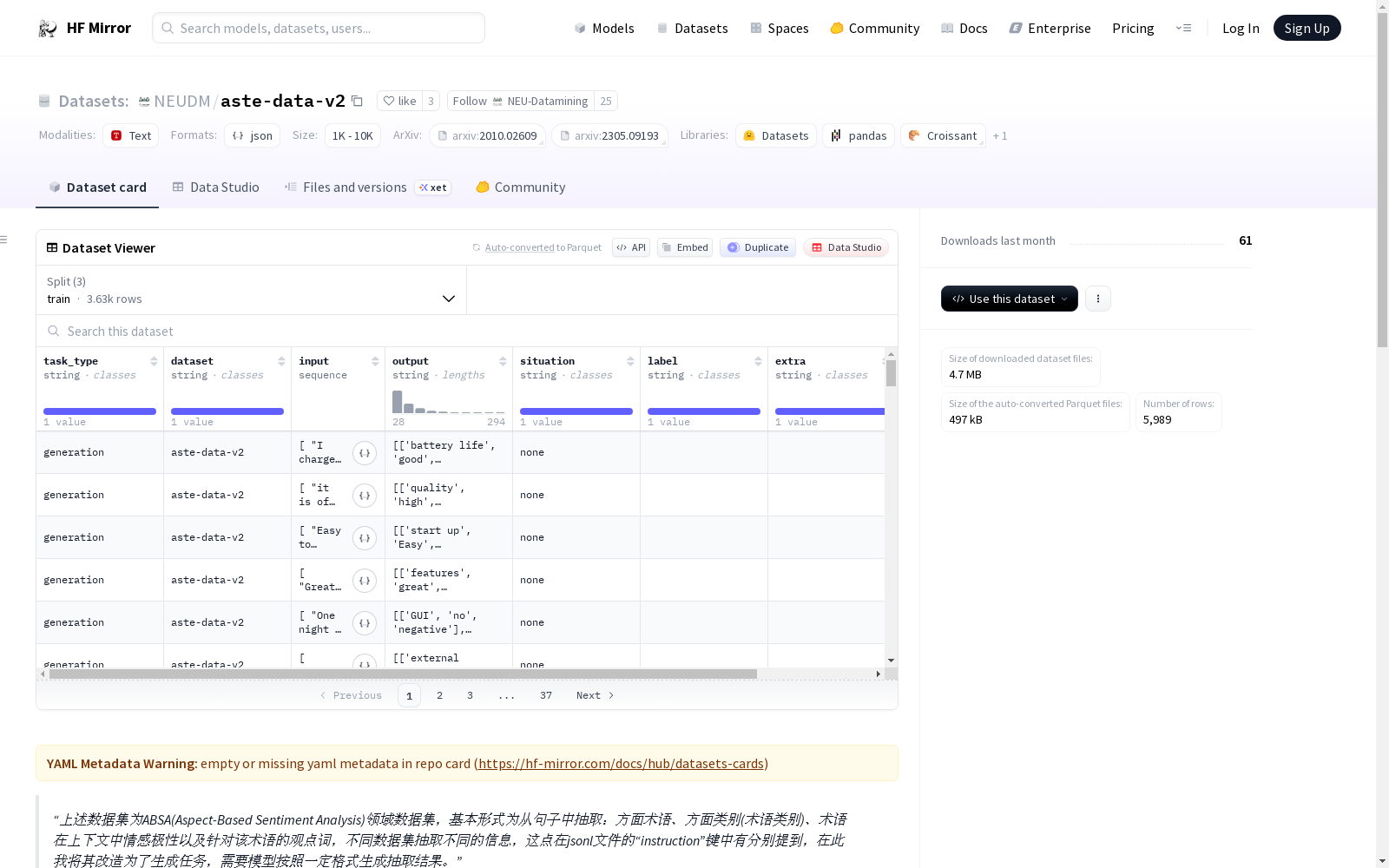
资源简介:
> 上述数据集为ABSA(Aspect-Based Sentiment Analysis)领域数据集,基本形式为从句子中抽取:方面术语、方面类别(术语类别)、术语在上下文中情感极性以及针对该术语的观点词,不同数据集抽取不同的信息,这点在jsonl文件的“instruction”键中有分别提到,在此我将其改造为了生成任务,需要模型按照一定格式生成抽取结果。
#### 以acos数据集中抽取的jsonl文件一条数据举例:
```
{
"task_type": "generation",
"dataset": "acos",
"input": ["the computer has difficulty switching between tablet and computer ."],
"output": "[['computer', 'laptop usability', 'negative', 'difficulty']]",
"situation": "none",
"label": "",
"extra": "",
"instruction": "
Task: Extracting aspect terms and their corresponding aspect categories, sentiment polarities, and opinion words.
Input: A sentence
Output: A list of 4-tuples, where each tuple contains the extracted aspect term, its aspect category, sentiment polarity, and opinion words (if any). Supplement: \"Null\" means that there is no occurrence in the sentence.
Example:
Sentence: \"Also it's not a true SSD drive in there but eMMC, which makes a difference.\"
Output: [['SSD drive', 'hard_disc operation_performance', 'negative', 'NULL']]'
"
}
```
> 此处未设置label和extra,在instruction中以如上所示的字符串模板,并给出一个例子进行one-shot,ABSA领域数据集(absa-quad,acos,arts,aste-data-v2,mams,semeval-2014,semeval-2015,semeval-2016,towe)每个数据集对应instruction模板相同,内容有细微不同,且部分数据集存在同一数据集不同数据instruction内容不同的情况。
#### 原始数据集
- 数据[链接](https://github.com/xuuuluuu/Position-Aware-Tagging-for-ASTE)
- Paper: [Position-Aware Tagging for Aspect Sentiment Triplet Extraction](https://arxiv.org/abs/2010.02609)
- 说明:原始数据集由laptop14、restaurant14、restaurant15以及restaurant16四部分文件组成。
#### 当前SOTA
*数据来自[Easy-to-Hard Learning for Information Extraction](https://arxiv.org/abs/2305.09193)*
- 评价指标:F1 Score
- SOTA模型:E2H-large
- 在laptop14数据部分:**75.92**
- 在restaurant14数据部分:**65.98**
- 在restaurant15数据部分:**68.80**
- 在restaurant16数据部分:**75.46**
- 平均:**71.54**
- Paper:[Easy-to-Hard Learning for Information Extraction](https://arxiv.org/pdf/2305.09193.pdf)
- 说明:该论文来自[Google Scholar](https://scholar.google.com/scholar?as_ylo=2023&hl=zh-CN&as_sdt=2005&sciodt=0,5&cites=8596892198266513995&scipsc=)检索到的引用ASTE-data-v2原论文的论文之一,在比较2023年的一些论文工作后筛选了一个最优指标以及模型。
本数据集属于基于方面的情感分析(Aspect-Based Sentiment Analysis,ABSA)领域,其核心任务为从语句中抽取四类信息:方面术语、方面类别(术语所属类别)、术语在上下文语境中的情感极性,以及针对该术语的评价观点词。不同数据集需抽取的信息维度存在差异,相关说明可在jsonl文件的"instruction"字段中查看。本次工作将该类数据集改造为生成式任务,要求模型按照指定格式生成抽取结果。
#### 以acos数据集中抽取的jsonl文件一条数据举例:
json
{
"任务类型": "generation",
"数据集名称": "acos",
"输入": ["这款电脑在平板与电脑模式间切换存在卡顿。"],
"输出": "[['电脑', '笔记本电脑使用性能', '负面', '卡顿']]",
"场景": "none",
"标签": "",
"额外信息": "",
"指令说明": "
任务:抽取方面术语及其对应的方面类别、情感极性与观点词。
输入:单句文本
输出:由四元组构成的列表,每个四元组依次包含抽取得到的方面术语、所属方面类别、情感极性以及观点词(若存在)。补充说明:"Null"表示语句中无对应内容。
示例:
语句:"此处搭载的并非真正的固态硬盘(SSD),而是eMMC存储,这会对性能产生影响。"
输出:[['固态硬盘(SSD)', '硬盘运行性能', '负面', 'NULL']]
"
}
本示例未设置标签与额外信息字段,指令说明采用上述字符串模板,并通过单样本示例(one-shot)进行演示。ABSA领域数据集涵盖absa-quad、acos、arts、aste-data-v2、mams、semeval-2014、semeval-2015、semeval-2016、towe等,各数据集的指令模板框架一致,但细节存在差异;部分数据集甚至存在同数据集内不同样本的指令内容不一致的情况。
#### 原始数据集
- 数据[链接](https://github.com/xuuuluuu/Position-Aware-Tagging-for-ASTE)
- 论文: [面向方面情感三元组抽取的位置感知标注](https://arxiv.org/abs/2010.02609)
- 说明:原始数据集包含laptop14、restaurant14、restaurant15与restaurant16四个子数据集文件。
#### 当前最优模型(SOTA)
*数据来源:[面向信息抽取的从易到难学习](https://arxiv.org/abs/2305.09193)*
- 评价指标:F1值
- 当前最优模型:E2H-large
- 在laptop14子数据集上:**75.92**
- 在restaurant14子数据集上:**65.98**
- 在restaurant15子数据集上:**68.80**
- 在restaurant16子数据集上:**75.46**
- 整体平均性能:**71.54**
- 相关论文:[面向信息抽取的从易到难学习](https://arxiv.org/pdf/2305.09193.pdf)
- 说明:该论文为通过[Google Scholar](https://scholar.google.com/scholar?as_ylo=2023&hl=zh-CN&as_sdt=2005&sciodt=0,5&cites=8596892198266513995&scipsc=)检索到的引用ASTE-data-v2原论文的文献之一,研究团队在对比2023年以来的多项相关研究工作后,选取了该最优性能指标与对应模型。
提供机构:
NEUDM
原始信息汇总
数据集概述
数据集类型
- 领域:Aspect-Based Sentiment Analysis (ABSA)
- 任务类型:Generation
数据集内容
- 数据集名称:acos
- 输入格式:句子
- 输出格式:列表,包含四个元素的元组,分别表示提取的方面术语、方面类别、情感极性及观点词。
- 示例:
- 输入:"the computer has difficulty switching between tablet and computer ."
- 输出:"[[computer, laptop usability, negative, difficulty]]"
数据集说明
- 任务描述:从句子中抽取方面术语及其对应的方面类别、情感极性和观点词。
- 输入说明:单个句子。
- 输出说明:一个列表,每个元素为一个四元组,包含方面术语、方面类别、情感极性和观点词(若无观点词,则用"NULL"表示)。
- 示例输出:[[SSD drive, hard_disc operation_performance, negative, NULL]]
原始数据集信息
- 组成:由laptop14、restaurant14、restaurant15及restaurant16四部分文件组成。
- 来源:Position-Aware Tagging for Aspect Sentiment Triplet Extraction
当前SOTA模型
- 模型名称:E2H-large
- 评价指标:F1 Score
- 性能指标:
- laptop14部分:75.92
- restaurant14部分:65.98
- restaurant15部分:68.80
- restaurant16部分:75.46
- 平均:71.54
- 来源论文:Easy-to-Hard Learning for Information Extraction
搜集汇总
数据集介绍
构建方式
在细粒度情感分析领域,ASTE-data-v2数据集基于原始ASTE任务构建,其原始数据来源于laptop14、restaurant14、restaurant15及restaurant16四个公开基准。该数据集通过结构化转换,将传统的序列标注或分类任务重构为生成式任务。每条数据样本均包含一个输入句子及对应的输出四元组列表,涵盖方面术语、类别、情感极性和观点词。构建过程中,设计统一的指令模板,并采用单样本示例引导,确保了任务格式的一致性,同时保留了原始数据的细粒度标注信息,为生成式模型提供了清晰的任务定义与上下文。
特点
ASTE-data-v2数据集在方面级情感三元组抽取任务中展现出鲜明的特点。数据集覆盖餐饮与电子产品两大领域,提供了丰富的真实场景语句,增强了模型的领域适应性。其核心特征在于将复杂的结构化抽取任务转化为序列生成问题,通过统一的指令模板明确输出格式,降低了模型理解难度。数据集中每条样本均附带详细的指令说明与示例,支持单样本学习,有助于提升模型在少样本情境下的泛化能力。此外,数据集与当前SOTA研究紧密关联,为模型性能评估提供了可靠的基准。
使用方法
使用ASTE-data-v2数据集时,研究者可将其直接应用于生成式模型的训练与评估。模型接收输入句子及对应的指令模板,生成结构化的四元组列表作为输出。在训练阶段,建议遵循指令中的格式规范,确保模型学习到准确的抽取逻辑。评估时,可采用标准F1分数作为指标,与现有SOTA模型如E2H-large进行性能对比。数据集适用于探索从易到难的学习策略、少样本学习及跨领域迁移等研究方向,为推进ABSA领域的技术发展提供了实用且规范的实验平台。
背景与挑战
背景概述
NEUDM/aste-data-v2数据集诞生于2020年,由相关研究团队基于《Position-Aware Tagging for Aspect Sentiment Triplet Extraction》论文构建,专注于方面级情感三元组抽取这一细粒度情感分析任务。该数据集整合了laptop14、restaurant14、restaurant15及restaurant16等多个经典领域语料,旨在从文本中精准识别方面术语、其所属类别、情感极性及对应观点词,推动了ABSA领域向结构化、可解释性方向深化发展。其构建为模型提供了统一评估基准,显著促进了端到端信息抽取技术的演进,成为后续研究如Easy-to-Hard Learning等工作的关键数据基础。
当前挑战
在方面级情感三元组抽取任务中,核心挑战在于模型需同时处理术语边界识别、类别归类、情感判断及观点词关联等多重子任务,且需应对术语与观点词间复杂语义关联及跨领域适应性难题。数据集构建过程中,标注一致性面临严峻考验,例如方面术语与观点词的稀疏对齐、情感极性在上下文中的歧义性,以及不同领域如笔记本电脑与餐厅评论的术语分布差异,均增加了高质量标注的难度。此外,将异构原始数据转化为统一生成式格式时,需平衡指令模板的普适性与数据特异性,确保评估标准的严谨性。
常用场景
经典使用场景
在细粒度情感分析领域,ASTE-data-v2数据集为方面级情感三元组抽取任务提供了标准化的评估基准。该数据集通过标注句子中的方面术语、其所属类别、情感极性及对应的观点词,构建了结构化情感信息框架。研究者通常利用此数据集训练序列标注或生成模型,以精准识别文本中隐含的情感要素,推动自然语言理解向更深层次发展。
实际应用
在实际应用中,ASTE-data-v2数据集支撑了电商评论分析、社交媒体舆情监控及客户反馈挖掘等场景。企业可借助基于该数据集训练的模型,自动提取产品特定方面的用户评价,识别服务短板或产品优势,从而优化运营策略。这种细粒度分析能力提升了商业智能系统的决策精度与响应效率。
衍生相关工作
围绕该数据集,学术界涌现了多项经典工作,例如基于位置感知标注的ASTE模型,以及采用易到难学习策略的E2H-large模型。这些研究通过改进序列标注架构或引入渐进式训练机制,显著提升了情感三元组抽取的F1分数,推动了细粒度情感分析技术的迭代演进,并为后续的生成式方法奠定了基础。
以上内容由遇见数据集搜集并总结生成


