reasoning-base-20k
收藏Hugging Face2024-10-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/KingNish/reasoning-base-20k
下载链接
链接失效反馈官方服务:
资源简介:
该数据集旨在训练推理模型,使其能够像人类一样在提供答案之前思考复杂问题。数据集包含来自不同领域(如科学、编程、数学等)的各种问题,每个问题都附有详细的推理链(COT)和正确答案。数据集的目标是使模型能够学习和改进其推理过程,识别和纠正错误,并提供高质量、详细的回答。数据集目前仍在进行中。
This dataset is designed to train reasoning models, enabling them to think through complex problems before providing answers just as humans do. The dataset contains various questions from diverse fields such as science, programming, mathematics and more, with each question accompanied by a detailed Chain-of-Thought (COT) and the correct answer. The goal of this dataset is to enable models to learn and improve their reasoning processes, identify and rectify errors, and deliver high-quality, detailed responses. The dataset is currently under active development.
创建时间:
2024-10-02
原始信息汇总
数据集卡片:Reasoning Base 20k
数据集详情
数据集描述
该数据集旨在训练推理模型,使其能够在提供答案之前通过复杂问题进行思考,类似于人类的方式。数据集包含来自多个领域(如科学、编码、数学等)的广泛问题,每个问题都附有详细的思维链(COT)和正确答案。目标是使模型能够学习和优化其推理过程,识别并纠正错误,并提供高质量、详细的响应。该数据集目前正在进行中。
- 创建者: Nishith Jain
- 语言: 英语
- 许可证: Apache-2.0
使用场景
直接使用
- 模型训练: 训练推理模型以提高其处理复杂问题的能力。
- 研究: 研究不同推理策略和技术的有效性。
超出范围的使用
- 误用: 数据集不应被用于恶意目的,如生成误导性或有害内容。
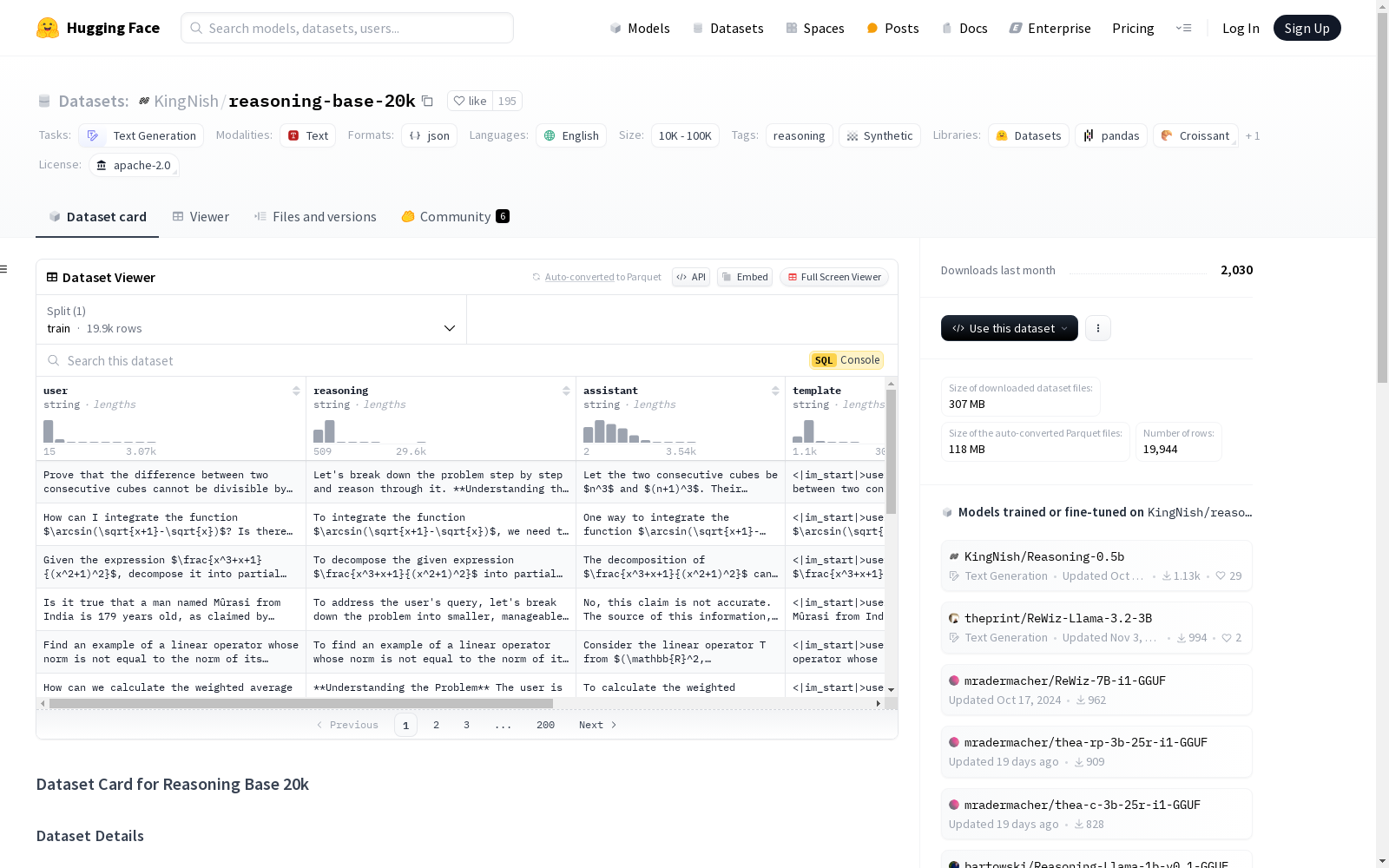
数据结构
数据字段
- user: 用户的查询或问题陈述。
- assistant: 问题的正确答案。
- reasoning: 详细的、逐步的推理过程,解释如何得出正确答案。
搜集汇总
数据集介绍
构建方式
Reasoning Base 20k数据集旨在训练能够模拟人类思维过程的推理模型。该数据集通过整合来自科学、编程、数学等多个领域的复杂问题,为每个问题提供了详细的思维链(Chain of Thought, COT)和正确答案。数据集的构建过程注重问题的多样性和思维链的完整性,以确保模型能够学习并优化其推理过程,识别并修正错误,最终生成高质量且详尽的回答。数据集目前仍在持续更新中。
特点
Reasoning Base 20k数据集的特点在于其广泛的问题覆盖范围和详细的思维链标注。每个问题不仅包含用户查询和正确答案,还提供了逐步推理的过程,帮助模型理解如何从问题陈述推导出最终答案。此外,数据集采用了RChatML模板,便于直接应用于模型训练和推理任务。这种结构化的数据形式为研究不同推理策略和技术提供了丰富的实验基础。
使用方法
Reasoning Base 20k数据集可直接用于训练推理模型,提升其在复杂问题上的推理能力。研究人员可通过该数据集研究不同推理策略的有效性,探索模型在逐步推理中的表现。数据集中的RChatML模板可直接应用于模型训练,简化了数据处理流程。此外,该数据集还可用于评估模型在生成详细推理过程时的准确性和逻辑性,为推理模型的优化提供重要参考。
背景与挑战
背景概述
Reasoning Base 20k数据集由Nishith Jain主导开发,旨在训练具备复杂问题推理能力的模型。该数据集涵盖了科学、编程、数学等多个领域的问题,每个问题均附有详细的思维链(Chain of Thought, COT)和正确答案。通过提供逐步推理过程,模型能够学习并优化其推理能力,识别并纠正错误,从而生成高质量且详细的响应。该数据集目前仍在持续开发中,其目标是通过模拟人类的思维方式,推动自然语言处理领域在复杂问题解决方面的进展。
当前挑战
Reasoning Base 20k数据集在构建和应用过程中面临多重挑战。首先,生成高质量的思维链需要领域专家深入参与,确保推理过程的准确性和逻辑性,这对数据标注提出了极高要求。其次,数据集涵盖多领域问题,如何平衡各领域的覆盖范围与深度,避免数据偏差,是构建过程中的一大难点。此外,模型在训练过程中需有效学习并模拟人类的推理过程,这对模型架构和训练策略提出了更高要求。最后,如何评估模型推理能力的真实提升,而非仅仅依赖答案的正确性,也是该领域亟待解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,reasoning-base-20k数据集被广泛用于训练和评估推理模型。该数据集包含了来自科学、编程、数学等多个领域的复杂问题,每个问题都附有详细的思维链(COT)和正确答案。通过使用该数据集,研究人员能够训练模型在提供答案之前进行深入的推理,从而模拟人类的思维过程。这种训练方式有助于模型在解决复杂问题时表现出更高的准确性和逻辑性。
解决学术问题
reasoning-base-20k数据集解决了自然语言处理领域中模型推理能力不足的问题。传统的模型往往在复杂问题上表现不佳,缺乏对问题的深入理解和逐步推理的能力。该数据集通过提供详细的思维链和正确答案,帮助模型学习如何逐步推理并纠正错误,从而提升其在复杂任务中的表现。这一进步对于推动人工智能在推理和决策领域的应用具有重要意义。
衍生相关工作
reasoning-base-20k数据集催生了一系列相关研究工作,特别是在推理模型和思维链生成领域。许多研究团队基于该数据集开发了新的推理算法和模型架构,进一步提升了模型的推理能力。例如,一些研究专注于优化思维链生成过程,以提高模型的解释性和准确性。此外,该数据集还被用于评估不同推理策略的有效性,推动了自然语言处理领域在推理任务上的技术进步。
以上内容由遇见数据集搜集并总结生成


