Gerutrute/Nemotron-Personas-Korea
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Gerutrute/Nemotron-Personas-Korea
下载链接
链接失效反馈官方服务:
资源简介:
Nemotron-Personas-Korea是一个基于韩国真实世界人口统计、地理和人格特质分布的开源合成人物数据集(CC BY 4.0)。它旨在广泛反映韩国人口的多样性和特征。作为首个大规模韩语人物数据集,它包含了诸如姓名、性别、年龄、婚姻状况、教育水平、职业和居住地区等属性,这些均基于韩国统计信息服务(KOSIS)、韩国最高法院、国民健康保险公团、韩国农村经济研究院和NAVER Cloud的官方统计数据合成。该数据集支持韩国模型开发者开发包含重要地区特定人口统计和文化背景的主权AI系统。它可用于扩展主权AI模型开发的合成数据多样性,缓解数据和模型偏见,并提高模型响应的多样性。数据集使用企业级合成数据生成复合AI系统NeMo Data Designer创建,并利用专有的概率图模型(PGM)、Apache-2.0许可的google/gemma-4-31B-it模型以及Data Designer中包含的验证和评估方法。
Nemotron-Personas-Korea is an open-source persona dataset (CC BY 4.0) synthesized based on real-world demographic, geographic, and personality trait distributions of South Korea. It is designed to broadly reflect the diversity and characteristics of the South Korean population. As the first large-scale Korean-language persona dataset, it includes attributes such as name, sex, age, marital status, education level, occupation, and region of residence, all synthesized using official statistics from the Korean Statistical Information Service (KOSIS), the Supreme Court of Korea, the National Health Insurance Service, and the Korea Rural Economic Institute, and NAVER Cloud. The dataset supports South Korean model builders in developing Sovereign AI systems that incorporate important region-specific demographics and cultural context. This dataset can be used to expand the diversity of synthetic data for sovereign AI model development, mitigate data and model bias, and improve the diversity of model responses. The dataset was created using NeMo Data Designer, an enterprise-grade compound AI system for synthetic data generation. It leverages a proprietary probabilistic graphical model (PGM), the Apache-2.0 licensed google/gemma-4-31B-it model, and the validation and evaluation methods included in Data Designer.
提供机构:
Gerutrute
搜集汇总
数据集介绍
构建方式
Nemotron-Personas-Korea 数据集基于韩国真实的人口统计、地理及性格特质分布,采用复合 AI 系统构建而成。其构建过程深度融合了源自韩国统计厅、大法院、国民健康保险公团等官方机构的种子数据,并借助企业级合成数据生成框架 NeMo Data Designer 中的概率图模型与 google/gemma-4-31B-it 模型,自动化地合成出百万级别的大规模韩语人格档案。每个记录均历经从初始属性抽样到人格描述文本生成的完整管线,最终形成涵盖丰富上下文属性的结构化数据集。
特点
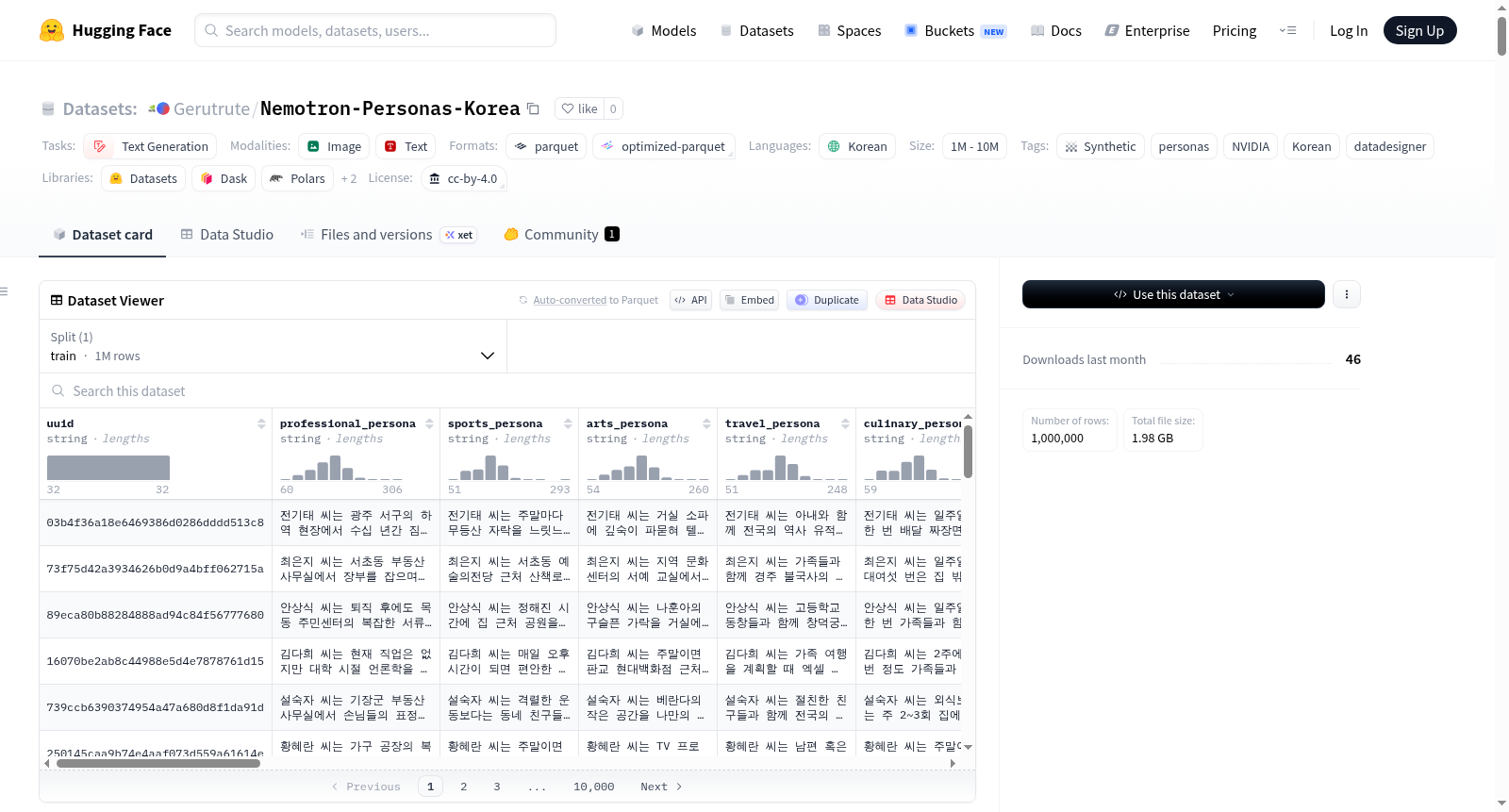
该数据集的核心特色在于其高度贴近韩国现实人口结构的合成特性,尤其强调在年龄、地域、教育水平及职业等维度上的分布保真度,有效缓解了现有数据集中的代表性与偏差问题。其包含 100 万条记录及 700 万个人格描述,横跨 17 个一级行政区与 252 个基层行政单元,并提供了职业、运动、艺术等七类人格视角以及详尽的社会文化背景字段。此外,数据集遵循 CC BY 4.0 许可协议,为商业及非商业用途提供了开放透明的使用基础。
使用方法
此数据集专为支持韩国主权人工智能系统开发而设计,开发者可将其直接用于大语言模型的微调与对齐,以增强模型输出的多样性并减轻潜在的样本偏差。具体使用时,研究人员能够基于丰富的上下文属性字段(如年龄、性别、职业、居住地)进行精准的条件化采样,从而生成针对特定人口群体的定制化训练数据。数据集在 Hugging Face 上以 Parquet 格式分片发布,便于直接加载,同时 NeMo Data Designer 亦提供了可扩展的增强版本供深入探索。
背景与挑战
背景概述
Nemotron-Personas-Korea数据集由NVIDIA于2026年4月发布,是首个基于韩国实际人口统计与地理分布的大规模韩语合成人物画像数据集。其核心研究问题在于为韩语大语言模型提供能够真实反映韩国人口多样性(涵盖年龄、地区、职业等维度)的人物画像数据,以支持主权AI系统的开发。该数据集通过整合韩国统计厅、大法院、国民健康保险公团等多个权威机构的官方统计数据,利用NeMo Data Designer的复合AI系统及概率图模型生成,显著提升了合成数据的多样性与代表性,对缓解模型偏见、防止模型坍缩具有重要价值,为韩语自然语言处理领域提供了关键的底层资源。
当前挑战
该数据集主要挑战包括:1)解决的领域问题:现有韩语人物画像数据集在年龄(如老年人)、地区(如农村)和职业等维度上分布不均,导致模型训练数据存在偏差,难以公平覆盖韩国人口的多样性;合成数据生成过程中,由于公共数据的时效性限制和概率图模型的现实约束,需对变量间的独立性(如职业与性别、学历的交互效应)做出简化假设,无法完全模拟现实中的复杂关联。2)构建挑战:整合来自韩国统计厅、大法院、国民健康保险公团等异构数据源时,需处理数据格式、编码及定义差异;性别统计仅涵盖生物学性别,而缺乏社会性别数据,导致无法全面反映人口维度;确保合成人物画像与真实人物“无巧合相似”并保护隐私,增加了数据验证与匿名化难度。
常用场景
经典使用场景
Nemotron-Personas-Korea作为首个大规模韩语合成角色数据集,其经典应用在于为大型语言模型的微调与对齐提供高度拟真的韩国人口角色样本。研究者可依托其涵盖职业、兴趣、家庭背景等七类细致角色描述,结合年龄、性别、地域、学历等26维人口统计属性,精准构建反映韩国社会多样性的对话或指令数据,从而提升模型在韩语场景下的文化敏感性与回复的个性化程度。该数据集尤其适用于生成式AI的偏好学习与角色扮演任务,为构建更具语境适应性的智能系统奠定坚实的数据基石。
解决学术问题
该数据集致力于攻克现有合成语料中普遍存在的数据多样性与人口分布偏斜问题。通过严格锚定韩国统计厅、大法院等官方发布的真实人口分布,它有效缓解了因训练数据缺失特定年龄层(如高龄群体)、偏远地区(如农村)及特定职业群体而导致的模型代表性与公平性失衡。此外,其精心设计的多维度角色属性有助于压缩生成模型的坍塌风险,为学术界研究数据偏差的量化评估与缓解策略提供了理想实验平台,从而推动更具包容性的AI模型评估框架的发展。
衍生相关工作
该数据集的发布催生了若干方向的前沿探索。其一,研究者基于其构建的复杂人口统计关系图谱,开发了用于生成式AI的上下文条件化合成架构,进一步提升了角色生成的逻辑一致性。其二,部分工作围绕该数据集设计的角色多样性指标展开,提出了针对语言模型文化知识覆盖度的定量评估方法,为多区域AI研究提供了可复用的基准。此外,韩国本地社区已基于其公开的CC BY 4.0授权逐步衍生出一系列面向医疗、法律等垂直领域的专业角色数据集,拓展了该框架的应用边界。
以上内容由遇见数据集搜集并总结生成


