scikit-learn/student-alcohol-consumption
收藏Hugging Face2022-06-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/scikit-learn/student-alcohol-consumption
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc0-1.0
---
## Student Alcohol Consumption Dataset
A dataset on social, gender and study data from secondary school students.
Following was retrieved from [UCI machine learning repository](https://www.kaggle.com/datasets/uciml/student-alcohol-consumption).
**Context:**
The data were obtained in a survey of students math and portuguese language courses in secondary school. It contains a lot of interesting social, gender and study information about students. You can use it for some EDA or try to predict students final grade.
**Content:**
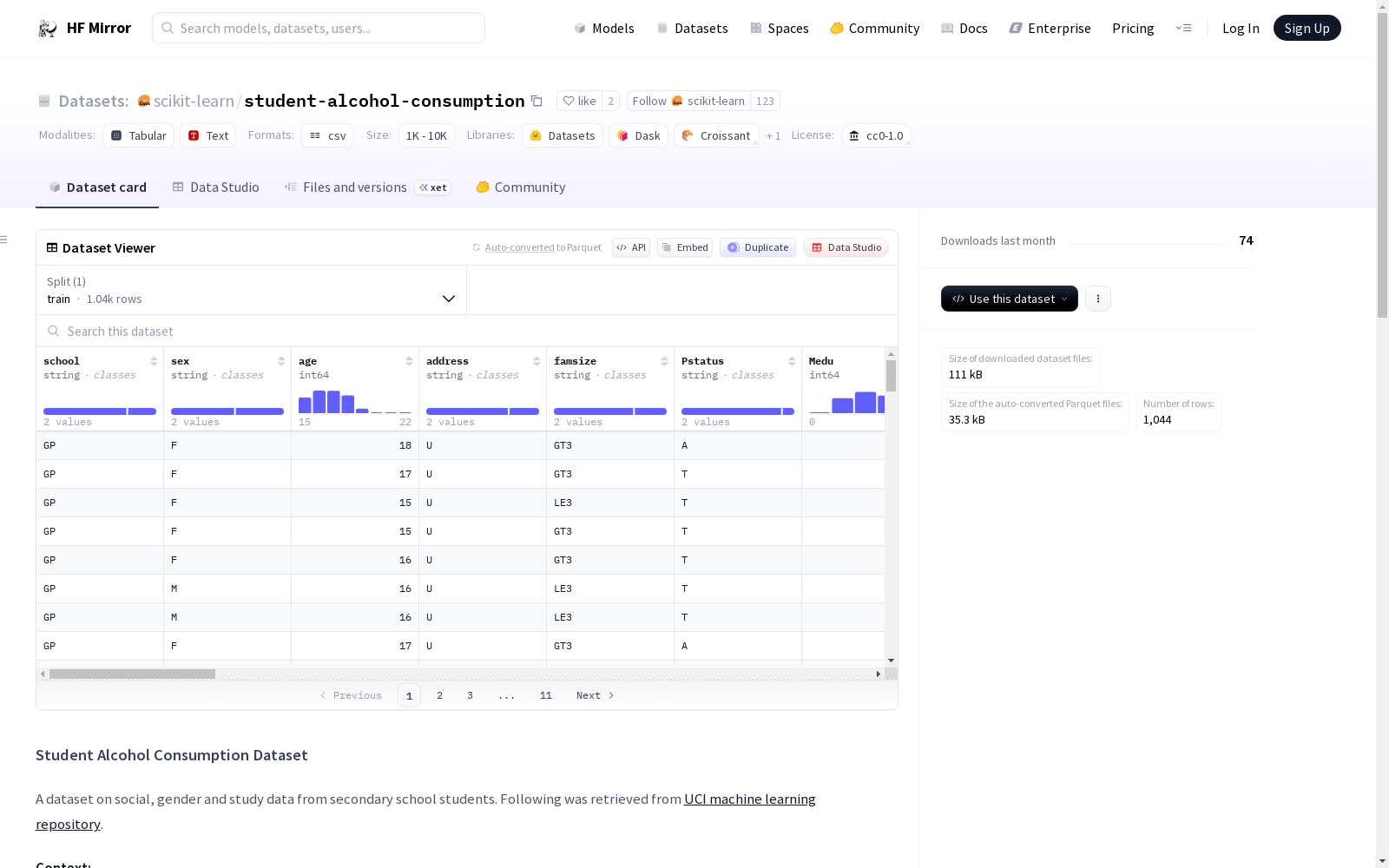
Attributes for both student-mat.csv (Math course) and student-por.csv (Portuguese language course) datasets:
- school - student's school (binary: 'GP' - Gabriel Pereira or 'MS' - Mousinho da Silveira)
- sex - student's sex (binary: 'F' - female or 'M' - male)
- age - student's age (numeric: from 15 to 22)
- address - student's home address type (binary: 'U' - urban or 'R' - rural)
- famsize - family size (binary: 'LE3' - less or equal to 3 or 'GT3' - greater than 3)
- Pstatus - parent's cohabitation status (binary: 'T' - living together or 'A' - apart)
- Medu - mother's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Fedu - father's education (numeric: 0 - none, 1 - primary education (4th grade), 2 – 5th to 9th grade, 3 – secondary education or 4 – higher education)
- Mjob - mother's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- Fjob - father's job (nominal: 'teacher', 'health' care related, civil 'services' (e.g. administrative or police), 'at_home' or 'other')
- reason - reason to choose this school (nominal: close to 'home', school 'reputation', 'course' preference or 'other')
- guardian - student's guardian (nominal: 'mother', 'father' or 'other')
- traveltime - home to school travel time (numeric: 1 - <15 min., 2 - 15 to 30 min., 3 - 30 min. to 1 hour, or 4 - >1 hour)
- studytime - weekly study time (numeric: 1 - <2 hours, 2 - 2 to 5 hours, 3 - 5 to 10 hours, or 4 - >10 hours)
- failures - number of past class failures (numeric: n if 1<=n<3, else 4)
- schoolsup - extra educational support (binary: yes or no)
- famsup - family educational support (binary: yes or no)
- paid - extra paid classes within the course subject (Math or Portuguese) (binary: yes or no)
- activities - extra-curricular activities (binary: yes or no)
- nursery - attended nursery school (binary: yes or no)
- higher - wants to take higher education (binary: yes or no)
- internet - Internet access at home (binary: yes or no)
- romantic - with a romantic relationship (binary: yes or no)
- famrel - quality of family relationships (numeric: from 1 - very bad to 5 - excellent)
- freetime - free time after school (numeric: from 1 - very low to 5 - very high)
- goout - going out with friends (numeric: from 1 - very low to 5 - very high)
- Dalc - workday alcohol consumption (numeric: from 1 - very low to 5 - very high)
- Walc - weekend alcohol consumption (numeric: from 1 - very low to 5 - very high)
- health - current health status (numeric: from 1 - very bad to 5 - very good)
- absences - number of school absences (numeric: from 0 to 93)
These grades are related with the course subject, Math or Portuguese:
- G1 - first period grade (numeric: from 0 to 20)
- G2 - second period grade (numeric: from 0 to 20)
- G3 - final grade (numeric: from 0 to 20, output target)
**Additional note:** there are several (382) students that belong to both datasets.
These students can be identified by searching for identical attributes that characterize each student, as shown in the annexed R file.
---
许可证:CC0 1.0
---
## 学生饮酒消费数据集
本数据集包含中学生的社交、性别与学习相关数据,数据源自[UCI机器学习库(UCI Machine Learning Repository)](https://www.kaggle.com/datasets/uciml/student-alcohol-consumption)。
**背景:**
本数据来源于对中学阶段数学课程与葡萄牙语课程学生的调研,包含大量关于学生的社交、性别与学习相关的有效信息,可用于开展探索性数据分析(Exploratory Data Analysis,EDA),或尝试预测学生的最终成绩。
**数据内容:**
两个数据集`student-mat.csv`(数学课程)与`student-por.csv`(葡萄牙语课程)包含以下属性:
- 学校(school):学生就读学校(二进制分类:'GP'代表加百列·佩雷拉(Gabriel Pereira),'MS'代表穆辛霍·达席尔维拉(Mousinho da Silveira))
- 性别(sex):学生性别(二进制分类:'F'为女性,'M'为男性)
- 年龄(age):学生年龄(数值型:15至22岁)
- 家庭住址类型(address):学生家庭住址类型(二进制分类:'U'为城区,'R'为乡村)
- 家庭规模(famsize):家庭成员数量(二进制分类:'LE3'表示小于或等于3人,'GT3'表示大于3人)
- 父母同居状态(Pstatus):父母同居情况(二进制分类:'T'表示共同居住,'A'表示分居)
- 母亲受教育程度(Medu):母亲的受教育水平(数值型:0代表未受教育,1代表小学教育(四年级),2代表5至9年级,3代表中等教育,4代表高等教育)
- 父亲受教育程度(Fedu):父亲的受教育水平(数值型:0代表未受教育,1代表小学教育(四年级),2代表5至9年级,3代表中等教育,4代表高等教育)
- 母亲职业(Mjob):母亲的职业(名义型:'teacher'教师、'health'医疗相关、'services'公共服务(如行政、警务)、'at_home'居家无业或'other'其他)
- 父亲职业(Fjob):父亲的职业(名义型:'teacher'教师、'health'医疗相关、'services'公共服务(如行政、警务)、'at_home'居家无业或'other'其他)
- 择校原因(reason):选择该校的原因(名义型:'home'离家近、'reputation'学校声誉、'course'课程偏好或'other'其他)
- 监护人(guardian):学生的监护人(名义型:'mother'母亲、'father'父亲或'other'其他)
- 上下学通勤时间(traveltime):家到学校的通勤时长(数值型:1代表<15分钟,2代表15至30分钟,3代表30分钟至1小时,4代表>1小时)
- 每周学习时长(studytime):每周学习时间(数值型:1代表<2小时,2代表2至5小时,3代表5至10小时,4代表>10小时)
- 过往挂科次数(failures):过往课程挂科次数(数值型:若1≤n<3则为n,否则为4)
- 学校额外辅导(schoolsup):是否接受学校提供的额外学业辅导(二进制分类:是/否)
- 家庭学业辅导(famsup):是否接受家庭提供的学业辅导(二进制分类:是/否)
- 付费课外课程(paid):是否参加本课程科目的付费课外班(二进制分类:是/否)
- 课外活动(activities):是否参与课外活动(二进制分类:是/否)
- 幼儿园就读经历(nursery):是否就读过幼儿园(二进制分类:是/否)
- 高等教育意愿(higher):是否希望接受高等教育(二进制分类:是/否)
- 家庭互联网接入(internet):家中是否可访问互联网(二进制分类:是/否)
- 恋爱关系(romantic):是否处于恋爱关系(二进制分类:是/否)
- 家庭关系质量(famrel):家庭关系质量(数值型:1代表极差至5代表极佳)
- 课后空闲时间(freetime):课后空闲时间多少(数值型:1代表极少至5代表极多)
- 外出社交频率(goout):与朋友外出聚会的频率(数值型:1代表极少至5代表极多)
- 工作日饮酒量(Dalc):工作日酒精消费频率(数值型:1代表极低至5代表极高)
- 周末饮酒量(Walc):周末酒精消费频率(数值型:1代表极低至5代表极高)
- 健康状况(health):当前健康状态(数值型:1代表极差至5代表极佳)
- 旷课次数(absences):学校旷课次数(数值型:0至93次)
以下成绩与对应课程科目(数学或葡萄牙语)相关:
- G1:第一学期成绩(数值型:0至20分)
- G2:第二学期成绩(数值型:0至20分)
- G3:最终成绩(数值型:0至20分,为预测目标变量)
**补充说明:** 共有382名学生同时出现在两个数据集中,可通过搜索每个学生的相同属性特征识别出这些学生,具体方法可参考附件中的R脚本。
提供机构:
scikit-learn
原始信息汇总
学生酒精消费数据集概述
数据集内容
- 数据来源:该数据集来自对中学生数学和葡萄牙语课程的调查,包含丰富的社会、性别和学习信息。
- 数据集组成:包含两个子数据集,分别针对数学课程(student-mat.csv)和葡萄牙语课程(student-por.csv)。
数据集属性
-
通用属性:
- school: 学生所在学校(GP - Gabriel Pereira 或 MS - Mousinho da Silveira)
- sex: 性别(F - 女性 或 M - 男性)
- age: 年龄(15至22岁)
- address: 家庭地址类型(U - 城市 或 R - 农村)
- famsize: 家庭大小(LE3 - 3人以下 或 GT3 - 3人以上)
- Pstatus: 父母同住状态(T - 同住 或 A - 分居)
- Medu: 母亲教育程度(0 - 无,1 - 小学,2 - 5至9年级,3 - 中学,4 - 高等教育)
- Fedu: 父亲教育程度(0 - 无,1 - 小学,2 - 5至9年级,3 - 中学,4 - 高等教育)
- Mjob: 母亲职业(teacher, health, services, at_home, other)
- Fjob: 父亲职业(teacher, health, services, at_home, other)
- reason: 选择该校的原因(home, reputation, course, other)
- guardian: 监护人(mother, father, other)
- traveltime: 上学通勤时间(1 - 少于15分钟,2 - 15至30分钟,3 - 30分钟至1小时,4 - 超过1小时)
- studytime: 每周学习时间(1 - 少于2小时,2 - 2至5小时,3 - 5至10小时,4 - 超过10小时)
- failures: 过去班级失败次数(1至2次为n,3次及以上为4)
- schoolsup: 额外教育支持(是或否)
- famsup: 家庭教育支持(是或否)
- paid: 额外付费课程(是或否)
- activities: 课外活动(是或否)
- nursery: 幼儿园经历(是或否)
- higher: 高等教育意愿(是或否)
- internet: 家庭互联网接入(是或否)
- romantic: 恋爱关系(是或否)
- famrel: 家庭关系质量(1 - 非常差至5 - 非常好)
- freetime: 课后自由时间(1 - 非常低至5 - 非常高)
- goout: 与朋友外出(1 - 非常低至5 - 非常高)
- Dalc: 工作日酒精消费(1 - 非常低至5 - 非常高)
- Walc: 周末酒精消费(1 - 非常低至5 - 非常高)
- health: 当前健康状况(1 - 非常差至5 - 非常好)
- absences: 缺课次数(0至93次)
-
课程相关属性:
- G1: 第一学期成绩(0至20分)
- G2: 第二学期成绩(0至20分)
- G3: 最终成绩(0至20分,目标输出)
附加信息
- 学生重叠:数据集中有382名学生同时出现在两个子数据集中,可通过特定属性识别。
搜集汇总
数据集介绍
构建方式
在社会科学与教育研究领域,学生行为数据的采集对于理解青少年发展模式至关重要。本数据集源自对葡萄牙两所中学数学与葡萄牙语课程学生的问卷调查,涵盖了社会、性别及学业等多维度信息。数据通过结构化问卷收集,包含学生个人背景、家庭环境、学习习惯及酒精消费等量化与分类变量,并以CSV格式整理为两个独立文件,分别对应不同学科。数据采集过程注重匿名性与伦理规范,确保了信息的可靠性与代表性。
使用方法
在应用层面,该数据集适用于教育心理学与社会行为学的实证研究。研究者可首先加载student-mat.csv或student-por.csv文件,利用Python的pandas或R语言进行数据清洗与预处理。通过特征工程,可提取关键变量如酒精消费与成绩的关联,并采用回归模型、分类算法或聚类分析进行建模。数据中的重复学生记录可用于跨学科比较,而最终成绩G3常作为预测目标。建议结合交叉验证与可视化工具,以揭示社会因素对学业表现的影响机制。
背景与挑战
背景概述
学生酒精消费数据集源于教育社会学与行为科学的交叉研究,由UCI机器学习知识库于2014年收录,旨在探究青少年社会行为与学业表现的关联机制。该数据集采集自葡萄牙两所中学数学与葡萄牙语课程的学生调查,涵盖家庭背景、学习习惯、社交活动及酒精消费等三十余项多维特征。其核心研究问题聚焦于解析社会经济因素、家庭环境与学生行为模式对学业成果的潜在影响,为教育干预策略和青少年健康政策制定提供了实证基础,推动了教育数据挖掘领域从单一成绩预测向多维度行为建模的范式转变。
当前挑战
该数据集致力于揭示青少年酒精消费行为与学业表现间的复杂因果关系,其挑战在于如何从高维异构特征中剥离混杂变量,例如家庭支持与社交活动的交互效应可能掩盖酒精消费的真实影响。构建过程中面临多重挑战:调查数据存在样本重叠,382名学生同时出现在数学与葡萄牙语子集中,需通过特征匹配实现数据去重;分类变量如父母职业采用非标准化名义编码,增加了特征工程的复杂性;酒精消费量依赖学生自报告,可能存在社会期望偏差与测量误差,影响模型泛化能力。
常用场景
经典使用场景
在青少年行为与教育研究领域,该数据集常被用于探索学生酒精消费模式与学业表现之间的关联。研究者通过整合社会人口学特征、家庭背景及学习习惯等多维度变量,构建预测模型以分析酒精摄入对期末成绩的影响,为教育干预提供数据支撑。
解决学术问题
该数据集有效解决了教育社会学中关于风险行为与学业成就因果机制的量化难题。通过提供结构化社会调查数据,它助力学者识别酒精消费的关键预测因子,并验证家庭支持、课余活动等调节变量的作用,从而深化对青少年发展轨迹的理解。
实际应用
在实际应用中,该数据集被学校与教育机构用于设计针对性健康促进项目。基于数据洞察,教育工作者可制定减少酒精滥用的干预策略,同时优化学术支持系统,以提升学生整体福祉与学业成果,实现数据驱动的教育管理。
数据集最近研究
最新研究方向
在教育数据挖掘领域,学生酒精消费数据集已成为探究青少年行为与学业表现关联的重要资源。当前研究聚焦于运用机器学习模型,如集成学习与深度学习算法,精准预测学生期末成绩,并深入剖析酒精消费与社交、家庭背景等多维因素的复杂交互机制。随着全球对青少年心理健康议题的日益关注,该数据集被广泛应用于行为风险预警系统的构建,助力教育干预策略的优化,其多源特征结构为跨学科研究提供了实证基础,推动了教育公平与健康促进政策的科学化发展。
以上内容由遇见数据集搜集并总结生成


