translationese-opensubtitles
收藏arXiv2026-03-09 更新2026-03-11 收录
下载链接:
https://huggingface.co/datasets/liu-nlp/translationese-opensubtitles
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由林雪平大学团队构建,是首个公开的英瑞翻译语料库,专门用于探究翻译腔现象与地道表达之间的对比。数据集包含600条从OpenSubtitles选取的英语对话句对,通过OPUS-MT系统和GPT-5生成翻译,并由人工标注提供地道改写版本。每条数据包含错误类型标注、语境说明及改进方案,涉及语法错误、语义偏移、词汇偏好等9类标签。该资源旨在帮助开发能生成更自然地道的非英语输出的模型,特别适用于机器翻译质量评估和语言模型偏好研究领域。
This dataset, developed by a research team from Linköping University, is the first publicly available English-Swedish translation corpus dedicated to investigating the contrast between translationese and authentic native-like expressions. The corpus contains 600 English dialogue sentence pairs extracted from OpenSubtitles; their translations were produced by both the OPUS-MT system and GPT-5, with manually annotated native-like rewritten versions provided for each pair. Each entry in the dataset features error type annotations, contextual descriptions, and improvement proposals, covering 9 label categories including grammatical errors, semantic drift, and lexical preference. This resource aims to support the development of models capable of generating more natural and idiomatic non-English outputs, and is particularly suitable for the fields of machine translation quality assessment and language model preference research.
提供机构:
林雪平大学·计算机与信息科学系
创建时间:
2026-03-09
原始信息汇总
数据集概述
基本信息
- 数据集名称: A Dataset for Probing Translationese Preferences in English-to-Swedish Translation
- 发布者/组织: liu-nlp
- 许可证: apache-2.0
- 语言: 瑞典语 (sv)
- 任务类别: 文本分类
- 数据规模: n<1K (小于1000个样本)
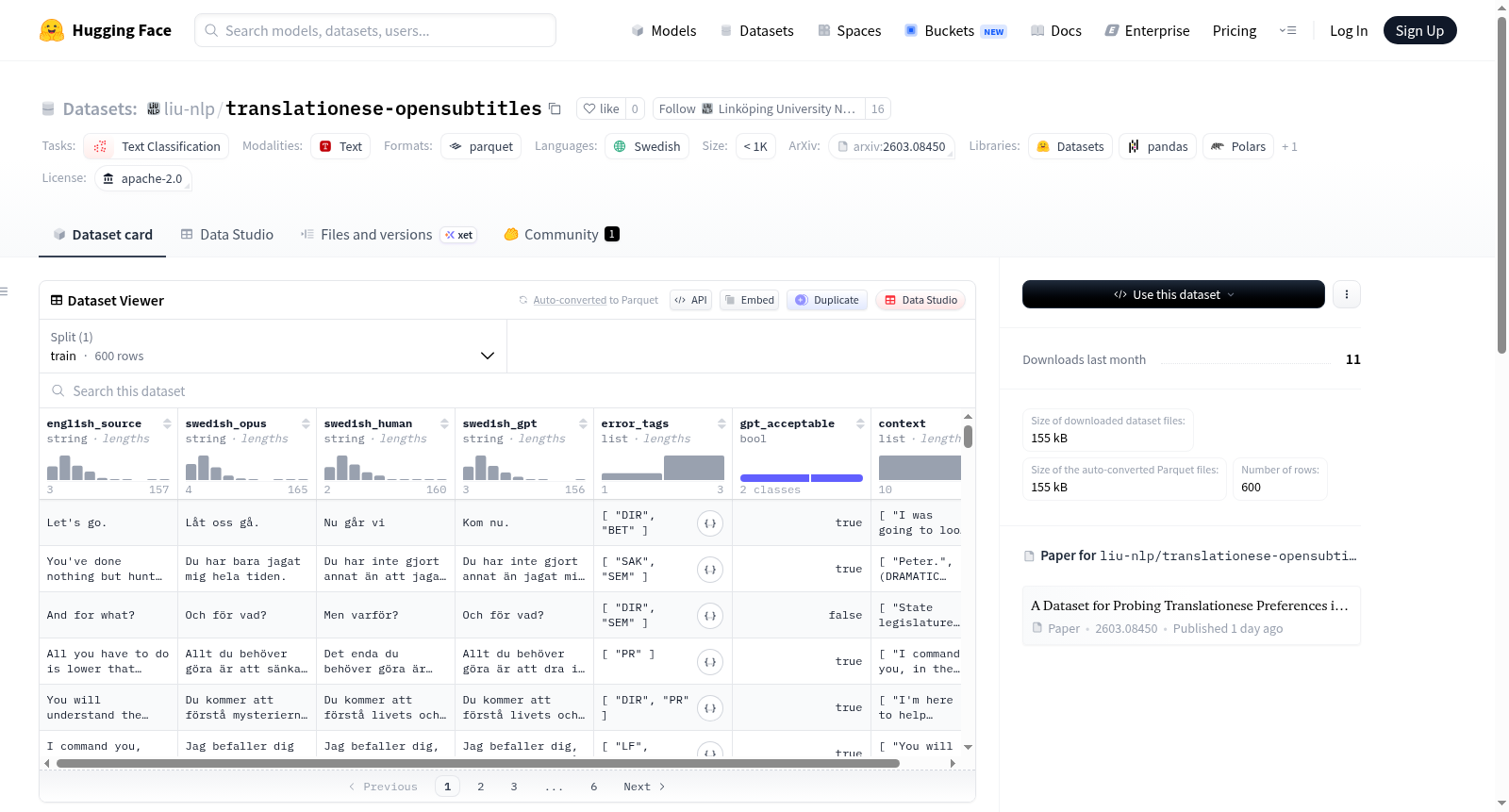
数据内容与结构
- 样本数量: 600 个样本
- 数据分割: 仅包含训练集 (train),共600个示例。
- 核心字段:
english_source: 英语源句子,来自OpenSubtitles。swedish_opus: 由OPUS-MT模型生成的瑞典语翻译。swedish_human: 由人工标注者生成的瑞典语翻译,旨在使OPUS翻译更自然、更地道。swedish_gpt: 由GPT-4生成的瑞典语翻译。error_tags: 针对OPUS翻译的错误标签序列,用于分类其中存在的“翻译腔”类型。gpt_acceptable: 人工标注者的判断,指示GPT翻译是否与人工翻译同等可接受。context: 来自源语言的上下文句子序列(每个样本包含10个句子)。
数据集目的
本数据集旨在用于建模在最小配对设置中对地道语言的隐式偏好,专门用于探究英语到瑞典语翻译中的“翻译腔”偏好。
数据来源与构建
- 英语源句: 来自英文电影字幕库 (OpenSubtitles)。
- 翻译版本:
- OPUS-MT翻译: 使用Helsinki-NLP的opus-mt-en-sv模型生成。
- GPT-4翻译: 使用GPT-4模型生成。
- 人工翻译: 由人工标注者生成,旨在明确改进OPUS翻译,使其更自然、更地道。
- 标注内容: 所有句子均标注了错误标签,用于分类OPUS翻译中存在的“翻译腔”类型。同时包含了对GPT翻译可接受性的人工判断。
引用信息
如需引用本数据集,请使用以下BibTeX条目: bibtex @misc{kunz2026datasetprobingtranslationesepreferences, title={A Dataset for Probing Translationese Preferences in English-to-Swedish Translation}, author={Jenny Kunz and Anja Jarochenko and Marcel Bollmann}, year={2026}, eprint={2603.08450}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2603.08450}, }
搜集汇总
数据集介绍
构建方式
在机器翻译研究领域,构建高质量的数据集对于深入分析翻译文本中的源语言痕迹至关重要。Translationese-opensubtitles数据集的构建过程体现了严谨的学术方法:研究团队从OpenSubtitles语料库中选取了600个英语句子作为源文本,这些句子主要源自口语对话。随后,使用OPUS-MT这一神经机器翻译系统以及GPT-5大语言模型分别生成瑞典语翻译。核心步骤在于人工标注:由两位以瑞典语为母语的认知科学学生进行细致的分析与修订。标注者不仅为每个机器翻译结果标注了详细的错误标签,还基于语感和词典支持,为每个句子提供了更地道的人工替代翻译。此外,数据集还包含了问题描述、解决方案以及上下文解释,并通过多轮质量控制和重复项剔除,确保了数据的一致性与可靠性。
特点
该数据集在翻译研究领域具有鲜明的特色与价值。其核心特征在于首次为英语-瑞典语翻译提供了公开可用的、系统对比翻译腔与地道表达的资源。数据集不仅提供了机器翻译的原始输出与人工优化版本,还创新性地引入了精细的错误标注体系。该体系涵盖了语法错误、语义偏移、词汇偏好、意义缺失、直译痕迹等多种错误类型,并能通过组合标签捕捉错误的复杂性。尤为重要的是,数据集包含了英语源句及其前文语境,使得研究者能够深入探究翻译任务设定与上下文信息对模型偏好的影响。这种将错误原因、语言现象与翻译效果进行关联标注的设计,为分析大语言模型在生成自然、地道非英语输出时的内在偏好提供了多维度的分析基准。
使用方法
该数据集主要服务于自然语言处理,特别是机器翻译与大语言模型评估领域的研究。其典型应用范式是基于最小对比对的探测实验,用以评估模型对地道语言的内在偏好。研究者可以设计不同的提示设置:一种是不提供翻译上下文,仅向模型呈现瑞典语句对,以评估其无任务干扰下的普遍偏好;另一种是提供翻译指令及英语源句,并可选择性地加入不同长度的前文语境,以考察翻译任务和上下文如何影响模型选择。通过计算模型对翻译腔版本和地道替代版本的对数似然或长度归一化概率,可以量化模型的偏好程度与偏差大小。此外,丰富的错误标签支持细粒度分析,使研究者能够探究模型对不同类型翻译问题的敏感度,从而为开发能产出更自然、更地道翻译的模型提供诊断工具与改进方向。
背景与挑战
背景概述
翻译文本常保留源语言特征,与目标语言原生文本存在系统性差异,这一现象被称为翻译腔。为探究语言模型对翻译腔的内在偏好,林雪平大学的研究团队于2026年构建了首个公开的英瑞翻译腔对比数据集translationese-opensubtitles。该数据集基于OpenSubtitles语料,包含600个句子对,每对均提供机器翻译的翻译腔版本与人工撰写的自然地道德语版本,并附有错误类型标注与问题描述。其核心研究在于揭示语言模型在翻译任务中是否倾向于生成字面直译的翻译腔表达,从而为提升非英语语言生成的天然性与地道性提供评估基准与研究方向。
当前挑战
该数据集旨在解决机器翻译与语言模型评估中翻译腔识别的挑战,即如何量化并减少模型对字面直译的偏好,以生成更地道、自然的非英语文本。构建过程中的挑战主要包括:一是语料标注的复杂性,需设计精细的错误标签体系以区分语法错误、语义偏移、词汇偏好及惯用语误译等多类问题;二是数据规模与多样性的平衡,虽然手工标注保证了样本质量与解释深度,但受限于领域单一性与标注成本,数据集规模较小,难以全面覆盖书面语等多种文本类型;三是评估框架的设计,需在最小对比对设置中控制句子长度等因素,以准确探测模型的内在偏好,避免评估偏差。
常用场景
经典使用场景
在机器翻译与自然语言处理领域,translationese-opensubtitles数据集被广泛应用于探究翻译文本中的源语言痕迹现象,即翻译腔。该数据集通过对比英语到瑞典语翻译中的翻译腔句子与地道替代方案,为研究者提供了一个精细的探测工具。其经典使用场景包括评估语言模型对翻译腔的偏好,尤其是在多语言环境下,模型是否倾向于生成更字面而非地道的翻译输出。数据集中的错误标签和问题描述使得分析能够深入到具体语言现象,如惯用语、俚语和领域特定术语的处理,从而揭示模型在生成自然语言时的内在偏差。
解决学术问题
该数据集主要解决了机器翻译和语言模型评估中的关键学术问题,即翻译腔对生成文本自然度和地道性的影响。通过提供带有标注的翻译对比样本,它使研究者能够量化模型在翻译任务中对源语言结构的依赖程度,并识别导致不自然输出的具体语言特征。此外,数据集支持对多语言模型在低资源语言(如瑞典语)上的表现进行基准测试,推动了开发更自然、更地道非英语输出模型的研究。其意义在于为翻译质量评估提供了新的方法论资源,促进了跨语言自然语言生成领域的理论进展与实践创新。
衍生相关工作
该数据集衍生了一系列经典研究工作,特别是在翻译腔探测和模型评估方向。基于其构建理念,后续研究扩展了多语言翻译腔分析,例如将类似方法应用于其他语言对(如英语-中文),以探究翻译腔的普遍性。同时,数据集启发了对大型语言模型在翻译任务中偏差机制的深入探讨,如有研究利用其最小对探测方法评估模型上下文依赖对翻译选择的影响。此外,相关工作在错误分类系统上进一步发展,整合了多维质量度量框架,推动了翻译质量评估标准的演进,并为低资源语言的自然语言生成模型优化提供了实证基础。
以上内容由遇见数据集搜集并总结生成


