openbmb/factnet-bench
收藏Hugging Face2026-05-07 更新2026-03-21 收录
下载链接:
https://hf-mirror.com/datasets/openbmb/factnet-bench
下载链接
链接失效反馈官方服务:
资源简介:
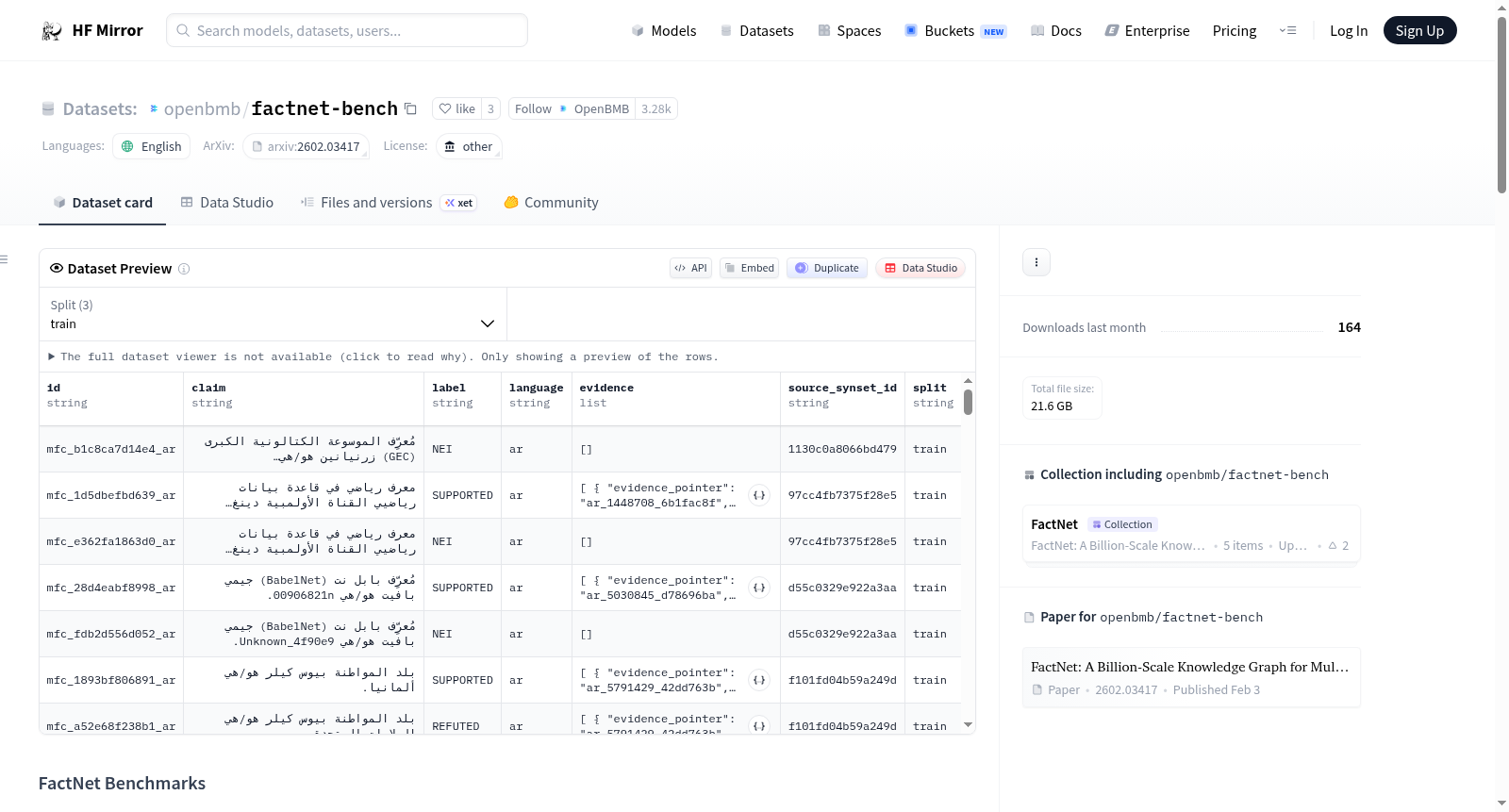
该数据集包含三个基准数据集,分别是知识图谱补全(KGC)、多语言知识图谱问答(MKQA)和多语言事实检查(MFC)。KGC用于评估模型在知识图谱中补全缺失链接的能力,格式为(主语,关系,宾语)三元组。MKQA用于评估多语言知识图谱问答能力,支持多种语言(如英语、中文、德语、法语等),格式为自然语言问题和结构化答案。MFC用于评估多语言事实验证能力,支持多种语言,标签包括支持、反驳和证据不足。每个基准数据集都有详细的构建方法和任务描述。
This repository contains three benchmark datasets derived from FactNet: Knowledge Graph Completion (KGC), Multilingual Knowledge Graph QA (MKQA), and Multilingual Fact Checking (MFC). The KGC benchmark evaluates a models ability to complete missing links in a knowledge graph, formatted as (subject, relation, object) triples. The MKQA benchmark evaluates knowledge graph question answering across multiple languages (e.g., English, Chinese, German, French), formatted as natural language questions with structured answers. The MFC benchmark evaluates fact verification capabilities across languages, with labels including SUPPORTED, REFUTED, and NOT_ENOUGH_INFO. Each benchmark dataset includes detailed construction methods and task descriptions.
提供机构:
openbmb
搜集汇总
数据集介绍
构建方式
FactNet-Bench基准数据集的设计与构建历经多阶段精密流水线。首先,从维基数据中解析出事实陈述与实体标签,同时借助WikiExtractor工具抽取维基百科页面文本,并解析页面链接与重定向信息。随后,基于Elasticsearch构建索引系统,对维基百科页面、事实陈述及实体标签进行高效存储与检索。在此基础上,通过将事实陈述与文本证据相互链接,构建FactSense实例,并进一步将相似事实聚合为FactSynsets,同时建立跨同义词集的关系边。最终,从FactNet结构中分别衍生出知识图谱补全、多语言知识图谱问答以及多语言事实核查三个基准测试集。
特点
该数据集具有鲜明的多元化特征,涵盖三大任务场景:知识图谱补全(KGC)以(主体、关系、客体)三元组形式评估模型对缺失链接的预测能力,并通过严谨的交叉分割碰撞处理确保评估公正性;多语言知识图谱问答(MKQA)支持英、中、德、法等语种,将结构化知识转化为自然语言问句,考验模型的多语言信息检索与推理能力;多语言事实核查(MFC)则通过支持、反驳、信息不足三类标签,结合基于字符跨度的黄金证据单元,为跨语言事实验证提供标准化评估框架。
使用方法
用户可通过HuggingFace的datasets库便捷加载该基准数据集。具体而言,使用load_dataset('factnet/kgc_bench')可获取知识图谱补全基准;调用load_dataset('factnet/mkqa_bench', 'en')或load_dataset('factnet/mfc_bench', 'en')可分别载入指定语种的多语言知识图谱问答与多语言事实核查数据集。以MFC数据集为例,用户可迭代测试集中的样本,提取声明文本、标注标签及关联证据单元,从而对模型的事实验证能力进行系统性评估。
背景与挑战
背景概述
FactNet-Bench是由Shen Yingli、Lai Wen等研究人员于2026年提出的一个面向多语言事实性知识推理的基准测试套件。该基准源自FactNet,一个基于维基数据和维基百科构建的十亿级知识图谱,旨在系统性地评估模型在知识图谱补全、多语言知识图谱问答以及多语言事实验证三个核心任务上的能力。通过提供涵盖英语、中文、德语、法语等多种语言的标准化评测框架,FactNet-Bench为知识驱动型自然语言处理研究提供了关键的评估平台,推动了多语言事实性知识的理解与推理能力的发展。
当前挑战
FactNet-Bench所解决的领域挑战在于,现有基准多聚焦于单一语言或单一任务,缺乏对多语言事实性推理能力的综合评价。其构建过程亦面临多重技术难点:从维基数据中精确提取事实陈述与标签,并处理大规模跨语言实体对齐;通过Elasticsearch对海量维基页面与事实语句建立高效索引,以支撑后续检索;构建FactSense实例时需将知识图谱中的三元组精准链接至对应文本片段,确保事实正确性;在生成多语言事实验证基准时,需设计合理的支持、驳斥与信息不足三类标签生成策略,并关联精确的证据单元,避免跨语言语义漂移与证据错配。
常用场景
经典使用场景
FactNet Benchmarks 数据集为知识驱动的人工智能研究提供了三项经典评测任务,涵盖知识图谱补全、多语言知识图谱问答以及多语言事实核查。在知识图谱补全任务中,模型需基于(主体、关系、客体)三元组结构预测缺失的实体,评估其对结构化知识的推理能力。多语言知识图谱问答则要求模型以自然语言形式回答多语言事实性问题,检验跨语言语义理解与知识检索的融合水平。多语言事实核查任务聚焦于验证声明是否被证据支持、反驳或信息不足,旨在提升模型在跨语言环境下的事实判别准确性。这三项任务共同构建了一个系统化、多维度的事实性推理评估框架。
实际应用
在实际应用层面,FactNet Benchmarks 可直接服务于智能问答系统、多语言信息检索平台与自动化事实核查工具的研发与评估。例如,基于多语言知识图谱问答基准,可构建支持跨地域用户的多语种对话机器人,帮助用户在不同语言环境下获取准确的结构化知识。多语言事实核查子集则为社交媒体内容审核、新闻真实性检测等场景提供标准化的验证手段,助力打击虚假信息传播。知识图谱补全任务能够优化企业级知识库的自动扩充与错误修复流程,在电商推荐、医疗诊断推理等领域具有重要的部署价值。这些应用场景充分体现了数据集从研究到落地的桥梁作用。
衍生相关工作
FactNet Benchmarks 的出现催生了一系列具有影响力的后续研究工作。围绕知识图谱补全任务,研究者基于其三元组结构与跨分割碰撞控制策略,提出了更有效的负采样方法与图神经网络推理架构。多语言知识图谱问答任务激励了多语言预训练模型的微调与prompt 学习范式的发展,相关工作探索了跨语言锚点迁移与多任务联合训练策略。多语言事实核查子集则为证据检索与声明验证的端到端建模提供了新的基准,推动了基于对比学习与跨语言编码器的事实性推理方法创新。此外,该数据集本身作为 FactNet 知识图谱的下游评测平台,也促进了大规模事实知识库的自动构建与质量评估算法研究。
以上内容由遇见数据集搜集并总结生成


