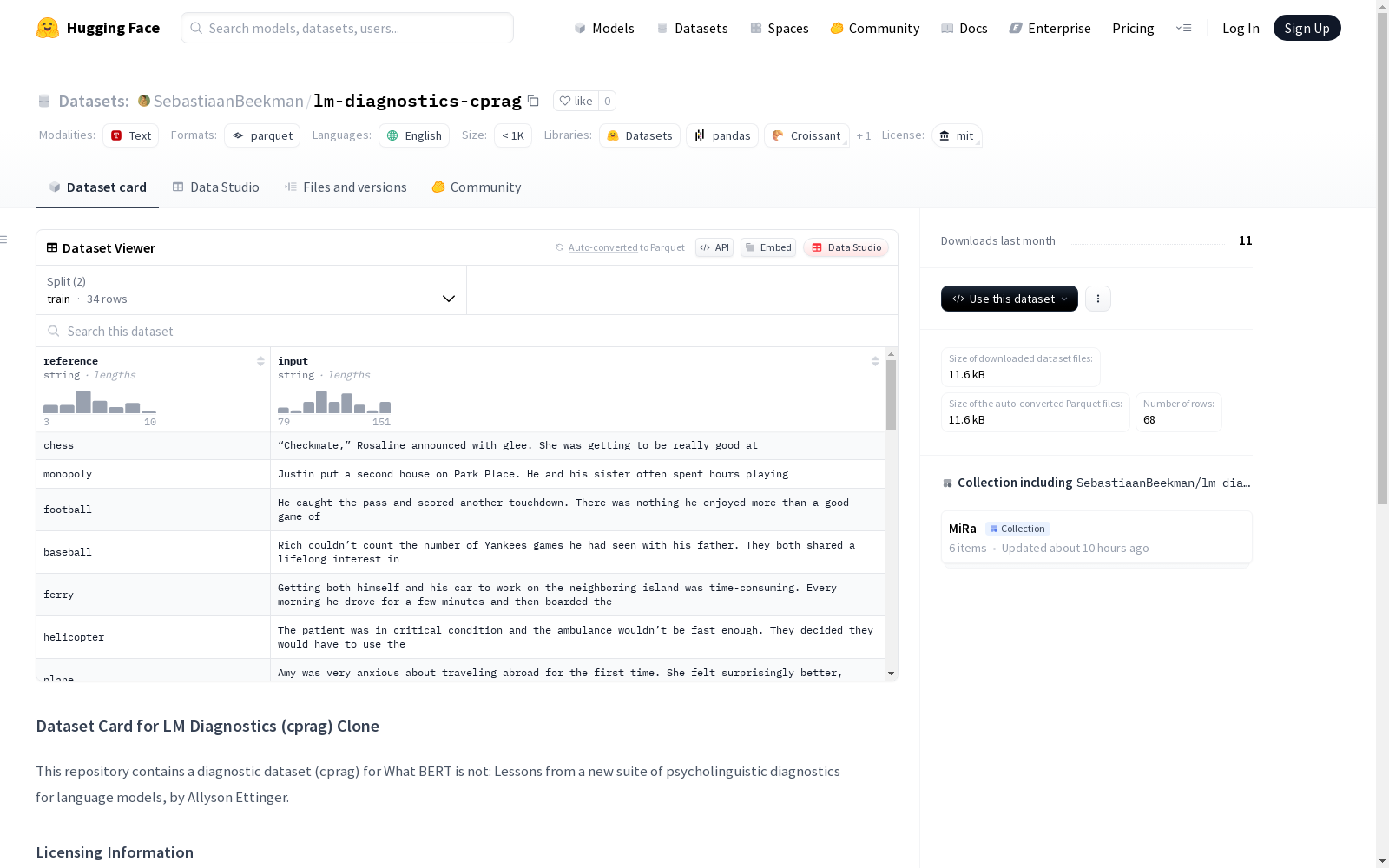
lm-diagnostics-cprag
收藏数据集概述
基本信息
- 数据集名称: LM Diagnostics (cprag) Clone
- 许可证: MIT License
- 语言: 英语 (en)
- 数据规模: 小于1K样本
数据集描述
该数据集为诊断数据集 (cprag),源自论文《What BERT is not: Lessons from a new suite of psycholinguistic diagnostics for language models》,作者为Allyson Ettinger。
引用信息
引用该数据集时,请使用以下BibTeX条目:
bibtex @article{10.1162/tacl_a_00298, author = {Ettinger, Allyson}, title = {What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models}, journal = {Transactions of the Association for Computational Linguistics}, volume = {8}, pages = {34-48}, year = {2020}, month = {01}, abstract = {Pre-training by language modeling has become a popular and successful approach to NLP tasks, but we have yet to understand exactly what linguistic capacities these pre-training processes confer upon models. In this paper we introduce a suite of diagnostics drawn from human language experiments, which allow us to ask targeted questions about information used by language models for generating predictions in context. As a case study, we apply these diagnostics to the popular BERT model, finding that it can generally distinguish good from bad completions involving shared category or role reversal, albeit with less sensitivity than humans, and it robustly retrieves noun hypernyms, but it struggles with challenging inference and role-based event prediction— and, in particular, it shows clear insensitivity to the contextual impacts of negation.}, issn = {2307-387X}, doi = {10.1162/tacl_a_00298}, url = {https://doi.org/10.1162/tacl_a_00298}, eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl_a_00298/1923116/tacl_a_00298.pdf}, }