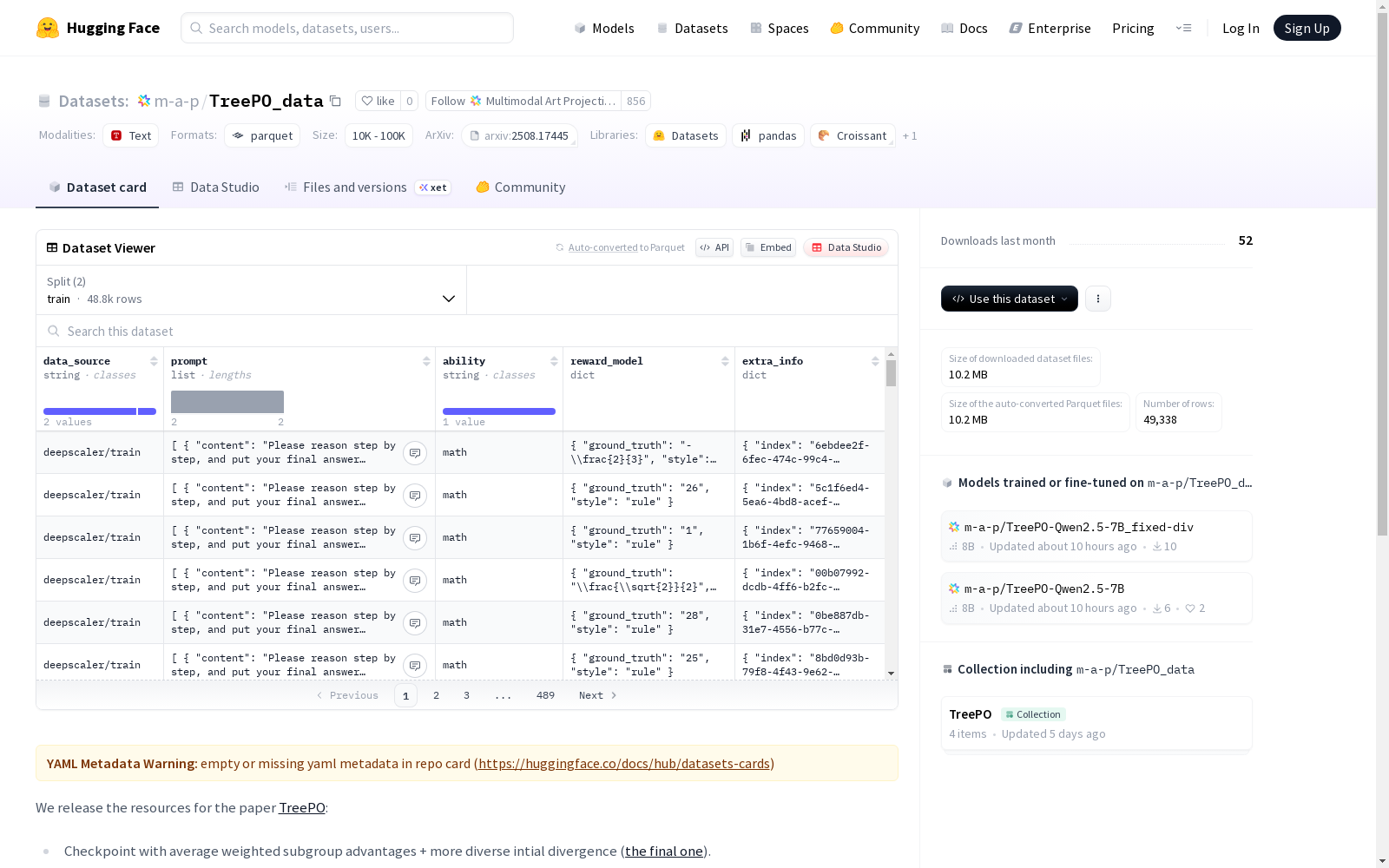
TreePO_data
收藏TreePO 数据集概述
数据集来源
该数据集隶属于论文《TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling》的研究项目,由m-a-p团队发布。
数据集内容
- 数据集类型:训练数据集
- 数据构成:包含deepscaler和simplerl数学推理数据
相关资源
- 论文地址:https://arxiv.org/abs/2508.17445
- 项目主页:https://m-a-p.ai/TreePO
- GitHub仓库:https://github.com/multimodal-art-projection/TreePO
- 最终检查点:https://huggingface.co/m-a-p/TreePO-Qwen2.5-7B
- 固定发散检查点:https://huggingface.co/m-a-p/TreePO-Qwen2.5-7B_fixed-div
引用信息
如需使用该数据集,请引用相关论文: bibtex @misc{li2025treepo, title={TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling}, author={Yizhi Li and Qingshui Gu and Zhoufutu Wen and Ziniu Li and Tianshun Xing and Shuyue Guo and Tianyu Zheng and Xin Zhou and Xingwei Qu and Wangchunshu Zhou and Zheng Zhang and Wei Shen and Qian Liu and Chenghua Lin and Jian Yang and Ge Zhang and Wenhao Huang}, year={2025}, eprint={2508.17445}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2508.17445}, howpublished = {url{https://m-a-p.ai/TreePO}} }